Une autre extension importante est le modèle autorégressif à coefficients variables dans le temps (TVAR), où les coefficients autorégressifs peuvent varier au fil du temps afin de modéliser des processus évolutifs ou non stationnaires. Les modèles TVAR sont largement utilisés lorsque la dynamique sous-jacente du système n'est pas constante, comme dans la modélisation des séries temporelles de capteurs , les sciences du climat , l'économie et la finance (en économétrie ) , le traitement du signal , les télécommunications , les systèmes radar et les signaux biologiques .
Contrairement au modèle à moyenne mobile (MA), le modèle autorégressif n'est pas toujours stationnaire ; la non-stationnarité peut survenir soit en raison de la présence d'une racine unitaire , soit en raison de paramètres de modèle variant dans le temps, comme dans les modèles autorégressifs variant dans le temps.
Les grands modèles de langage sont dits autorégressifs, mais ils ne constituent pas un modèle autorégressif classique au sens strict du terme, car ils ne sont pas linéaires.
où sont les paramètres du modèle, et est un bruit blanc . Ceci peut s'écrire de manière équivalente en utilisant l' opérateur de décalage arrière B comme
de sorte que, en déplaçant le terme de sommation à gauche et en utilisant la notation polynomiale , nous avons
Un modèle autorégressif peut ainsi être considéré comme la sortie d'un filtre à réponse impulsionnelle infinie à pôles égaux dont l'entrée est un bruit blanc.
Certaines contraintes sur les paramètres sont nécessaires pour que le modèle reste stationnaire au sens faible . Par exemple, les processus du modèle AR(1) avec ne sont pas stationnaires. Plus généralement, pour qu'un modèle AR( p ) soit stationnaire au sens faible, les racines du polynôme doivent se situer à l'extérieur du cercle unité , c'est-à-dire que chaque racine (complexe) doit satisfaire (voir pages 89 et 92 ).
 1
1 Effet intertemporel des chocs
Dans un processus AR, un choc ponctuel affecte les valeurs de la variable évolutive sur une période infinie. Prenons l'exemple du modèle AR(1) . Une valeur non nulle de à l'instant t = 1 affecte de . Alors, d'après l'équation AR de en fonction de , cela affecte de . Puis, d'après l'équation AR de en fonction de , cela affecte de . En poursuivant ce processus, on constate que l'effet de ne s'arrête jamais, même si, dans le cas d'un processus stationnaire , cet effet tend vers zéro à la limite.
Puisque chaque choc affecte les valeurs de X à l'infini dans le futur à partir du moment où il se produit, toute valeur donnée X<sub> t</sub> est affectée par des chocs survenus à l'infini dans le passé. On peut également le constater en réécrivant l'autorégression.
(où le terme constant a été supprimé en supposant que la variable a été mesurée comme des écarts par rapport à sa moyenne) comme
Lorsque la division polynomiale du membre de droite est effectuée, le polynôme de l'opérateur de décalage arrière appliqué à a un ordre infini, c'est-à-dire qu'un nombre infini de valeurs retardées de apparaissent du côté droit de l'équation.
Polynôme caractéristique
La fonction d'autocorrélation d'un processus AR( p ) peut être exprimée comme
où sont les racines du polynôme
où B est l' opérateur de décalage arrière , où est la fonction définissant l'autorégression, et où sont les coefficients de l'autorégression. La formule n'est valable que si toutes les racines sont de multiplicité 1.
Graphiques des processus AR( p )
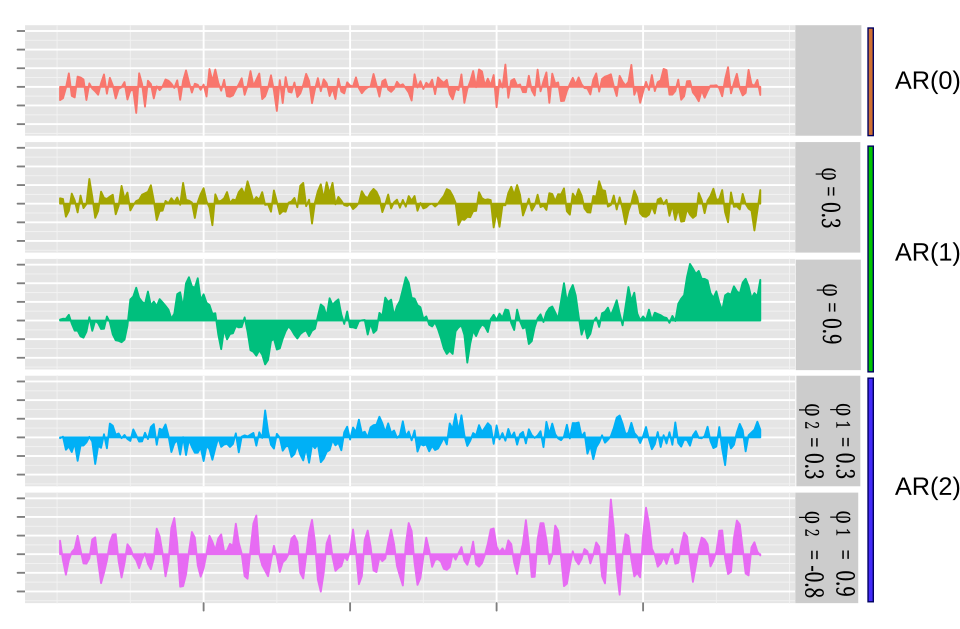
Le processus AR le plus simple est AR(0), qui ne présente aucune dépendance entre ses termes. Seul le terme d'erreur/d'innovation/de bruit contribue à la sortie du processus ; ainsi, sur la figure, AR(0) correspond à un bruit blanc.
Pour un processus AR(1) avec un ε positif , seuls le terme précédent et le bruit contribuent à la sortie. Si ε est proche de 0, le processus ressemble encore à un bruit blanc, mais lorsque ε tend vers 1, la contribution du terme précédent par rapport au bruit augmente. Il en résulte un lissage ou une intégration de la sortie, similaire à un filtre passe-bas .
Dans un processus AR(2), les deux termes précédents et le terme de bruit contribuent à la sortie. Si les deux termes sont positifs, la sortie se comporte comme un filtre passe-bas, atténuant la partie haute fréquence du bruit. Si le terme est positif tandis que le terme est négatif, le processus favorise les changements de signe entre ses termes. La sortie oscille alors. Ce phénomène peut être lié à la détection de fronts ou de changements de direction.
Exemple : Un processus AR(1)
Un processus AR(1) est défini par : où est un processus de bruit blanc de moyenne nulle et de variance constante . (Remarque : l'indice de a été omis.) Le processus est stationnaire au sens faible si , car il est obtenu comme sortie d'un filtre stable dont l'entrée est un bruit blanc. (Si , alors la variance de dépend du décalage temporel t , de sorte que la variance de la série diverge vers l'infini lorsque t tend vers l'infini, et n'est donc pas stationnaire au sens faible.) En supposant , la moyenne est identique pour toutes les valeurs de t par définition de la stationnarité au sens faible. Si la moyenne est notée , il découle de que et donc
La variance est
où représente l'écart type de . Ceci peut être démontré en remarquant que
et ensuite en remarquant que la quantité ci-dessus est un point fixe stable de cette relation.
L' autocovariance est donnée par
On peut constater que la fonction d'autocovariance décroît avec un temps de décroissance (également appelé constante de temps ) de .
La fonction de densité spectrale est la transformée de Fourier de la fonction d'autocovariance. En termes discrets, il s'agit de la transformée de Fourier à temps discret :
Cette expression est périodique en raison de la nature discrète de , ce qui se manifeste par le terme cosinus au dénominateur. Si l'on suppose que le temps d'échantillonnage ( ) est beaucoup plus petit que le temps de décroissance ( ), alors on peut utiliser une approximation continue pour :
ce qui donne un profil lorentzien pour la densité spectrale :
où est la fréquence angulaire associée au temps de décroissance .
On peut obtenir une autre expression pour en remplaçant d'abord par dans l'équation définissante. En répétant ce processus N fois, on obtient
Pour N tendant vers l'infini, tendra vers zéro et :
On constate que est un bruit blanc convolué avec le noyau et la moyenne constante. Si le bruit blanc suit une loi gaussienne, alors est également un processus gaussien. Dans les autres cas, le théorème central limite indique que suivra approximativement une loi normale lorsque est proche de un.
Pour , le processus suivra une progression géométrique ( croissance ou décroissance exponentielle ). Dans ce cas, la solution peut être trouvée analytiquement : où est une constante inconnue ( condition initiale ).
Forme explicite moyenne/différence du processus AR(1)
Le modèle AR(1) est l'analogue à temps discret du processus continu d'Ornstein-Uhlenbeck . Il est donc parfois utile de comprendre les propriétés du modèle AR(1) formulées sous une forme équivalente. Sous cette forme, le modèle AR(1), avec le paramètre de processus , est donné par
En réécrivant ceci comme et en déduisant ensuite (par récurrence) , on peut montrer que
Choisir le délai maximal
Le modèle AR( p ) est donné par l'équation
Elle repose sur des paramètres où i = 1, ..., p . Il existe une correspondance directe entre ces paramètres et la fonction de covariance du processus, et cette correspondance peut être inversée pour déterminer les paramètres à partir de la fonction d'autocorrélation (elle-même obtenue à partir des covariances). Ceci est réalisé à l'aide des équations de Yule-Walker.
Équations de Yule-Walker
Les équations de Yule-Walker, nommées d'après Udny Yule et Gilbert Walker , sont l'ensemble d'équations suivant.
où fonction delta de Kronecker .
Puisque le dernier terme d'une équation individuelle est non nul uniquement si
Estimation des paramètres AR
Les équations ci-dessus (les équations de Yule-Walker) offrent plusieurs méthodes pour estimer les paramètres d'un modèle AR( p ), en remplaçant les covariances théoriques par des valeurs estimées. Certaines de ces variantes peuvent être décrites comme suit :
- Estimation des autocovariances ou des autocorrélations. Chacun de ces termes est estimé séparément, à l'aide d'estimateurs classiques. Différentes méthodes permettent d'effectuer cette estimation, et le choix de la méthode influe sur les propriétés du schéma d'estimation. Par exemple, certains choix peuvent produire des estimations négatives de la variance.
- La formulation de ce problème le ramène à une régression par les moindres carrés, où l'on construit un problème de prédiction par les moindres carrés ordinaires, en prédisant les valeurs de X<sub> t</sub> à partir des p valeurs précédentes de la même série. On peut le considérer comme un schéma de prédiction directe. Les équations normales de ce problème correspondent à une approximation de la forme matricielle des équations de Yule-Walker, où chaque occurrence d'une autocovariance de même retard est remplacée par une estimation légèrement différente.
- Formulation sous forme étendue d'un problème de prédiction par les moindres carrés ordinaires. Deux ensembles d'équations de prédiction sont ici combinés en un seul schéma d'estimation et un seul ensemble d'équations normales. L'un est l'ensemble des équations de prédiction directe et l'autre est l'ensemble correspondant des équations de prédiction inverse, liées à la représentation inverse du modèle AR.
- Ici, les valeurs prédites de X<sub> t</sub> seraient basées sur les p valeurs futures de la même série. l'estimation spectrale d'entropie maximale .
D'autres méthodes d'estimation sont possibles, notamment l'estimation par maximum de vraisemblance . Deux variantes distinctes existent : la première (globalement équivalente à la méthode des moindres carrés avec prédiction directe) considère la fonction de vraisemblance correspondant à la distribution conditionnelle des valeurs ultérieures de la série, étant donné les valeurs initiales p ; la seconde considère la fonction de vraisemblance correspondant à la distribution conjointe inconditionnelle de toutes les valeurs de la série observée. Des différences importantes dans les résultats de ces méthodes peuvent apparaître si la série observée est courte ou si le processus est proche de la non-stationnarité.
Spectre
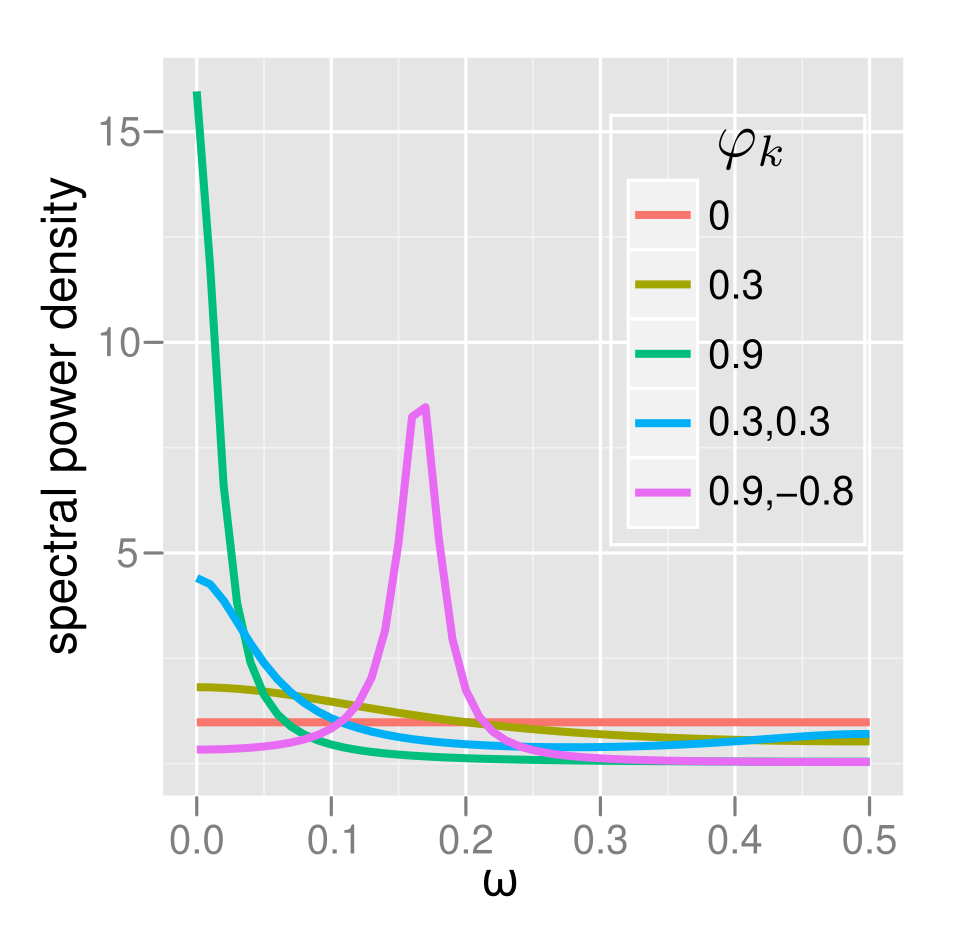
La densité spectrale de puissance (PSD) d'un processus AR( p ) avec variance de bruit est
AR(0)
Pour le bruit blanc (AR(0))
AR(1)
Pour AR(1)
- Si un seul pic spectral est présent à une fréquence donnée , souvent appelée bruit rouge , alors , plus la valeur de λ se rapproche de 1, plus la puissance est importante aux basses fréquences (donc avec des décalages temporels plus grands). Il s'agit alors d'un filtre passe-bas qui, appliqué à la lumière à spectre complet, filtre tout sauf la lumière rouge. 0"
0
- S'il existe un minimum à une certaine longueur d'onde , souvent appelé bruit bleu , celui-ci agit de la même manière qu'un filtre passe-haut : tout ce qui n'est pas la lumière bleue sera filtré.
AR(2)
Le comportement d'un processus AR(2) est entièrement déterminé par les racines de son équation caractéristique , qui s'exprime en termes de l' opérateur de retard comme suit :
ou de manière équivalente par les pôles de sa fonction de transfert , qui est définie dans le domaine Z par :
Il s'ensuit que les pôles sont des valeurs de z satisfaisant :
ce qui donne :
Les processus AR(2) peuvent être divisés en trois groupes en fonction des caractéristiques de leurs racines/pôles :
- Lorsque , le processus présente une paire de pôles complexes conjugués, créant un pic de fréquence moyenne à :
avec une largeur de bande autour du pic inversement proportionnelle aux modules des pôles :
Les termes impliquant des racines carrées sont tous réels dans le cas des pôles complexes puisqu'ils n'existent que lorsque .
Autrement, le processus a de véritables racines, et :
- Lorsqu'il agit comme un filtre passe-bas sur le bruit blanc avec un pic spectral à 0"
- Lorsqu'il agit comme un filtre passe-haut sur le bruit blanc avec un pic spectral à .
Le processus est non stationnaire lorsque les pôles sont situés sur ou à l'extérieur du cercle unité, ou, de manière équivalente, lorsque les racines caractéristiques sont situées sur ou à l'intérieur du cercle unité. Le processus est stable lorsque les pôles sont strictement situés à l'intérieur du cercle unité (les racines strictement à l'extérieur du cercle unité), ou, de manière équivalente, lorsque les coefficients sont dans le triangle .
La fonction PSD complète peut être exprimée sous forme réelle comme suit :
Implémentations dans les logiciels statistiques
- R – le package stats inclut la fonction ar ; le package astsa inclut la fonction sarima pour ajuster divers modèles, y compris AR.
- MATLAB – la boîte à outils d’économétrie et la boîte à outils d’identification de systèmes incluent des modèles AR.
- MATLAB et Octave – la boîte à outils TSA contient plusieurs fonctions d'estimation pour les modèles AR univariés, multivariés et adaptatifs.
- PyMC 3 – le cadre de statistiques bayésiennes et de programmation probabiliste prend en charge les modes AR avec p retards.
- bayesloop – prend en charge l’inférence de paramètres et la sélection de modèles pour le processus AR-1 avec des paramètres variant dans le temps.
- Python – statsmodels.org héberge un modèle AR.
Réponse impulsionnelle
La réponse impulsionnelle d'un système est la variation d'une variable évolutive en réponse à une variation de la valeur d'un terme de choc k périodes auparavant, en fonction de k . Puisque le modèle AR est un cas particulier du modèle autorégressif vectoriel, le calcul de la réponse impulsionnelle décrit dans la section « Réponse impulsionnelle » du modèle autorégressif vectoriel s'applique ici.
prévision à n pas
Une fois les paramètres de l'autorégression
Une fois les données estimées, l'autorégression peut être utilisée pour prévoir un nombre quelconque de périodes futures. Soit t la première période pour laquelle les données ne sont pas encore disponibles ; substituez les valeurs connues précédentes X <sub>t-i</sub> ( i = 1, ..., p) dans l'équation autorégressive, en annulant le terme d'erreur (car nous prévoyons que X <sub>t </sub> est égal à sa valeur attendue, et la valeur attendue du terme d'erreur non observé est nulle). Le résultat de l'équation autorégressive est la prévision pour la première période non observée. Ensuite, soit t la période suivante pour laquelle les données ne sont pas encore disponibles ; l'équation autorégressive est à nouveau utilisée pour effectuer la prévision, à une différence près : la valeur de X une période avant celle qui est prévue n'est pas connue, donc sa valeur attendue — la valeur prédite issue de la prévision précédente — est utilisée à la place. Pour les périodes suivantes, la même procédure est appliquée, en ajoutant à chaque fois une valeur de prévision supplémentaire au second membre de l'équation prédictive, jusqu'à ce qu'après p prévisions, toutes les valeurs du second membre soient des valeurs prédites des étapes précédentes.
Il existe quatre sources d'incertitude concernant les prédictions obtenues de cette manière : (1) l'incertitude quant à la pertinence du modèle autorégressif ; (2) l'incertitude quant à la précision des valeurs prévues utilisées comme valeurs retardées dans le membre de droite de l'équation autorégressive ; (3) l'incertitude quant aux valeurs réelles des coefficients autorégressifs ; et (4) l'incertitude quant à la valeur du terme d'erreur pour la période considérée. Chacune des trois dernières sources peut être quantifiée et combinée afin de définir un intervalle de confiance pour les prédictions à n pas. Cet intervalle s'élargit à mesure que n augmente, du fait de l'utilisation d'un nombre croissant de valeurs estimées pour les variables du membre de droite.