{{Cite conference|last1=Bayer|first1=R.|last2=McCreight|first2=E.|book-title=Proceedings of the 1970 ACM SIGFIDET (Now SIGMOD) Workshop on Data Description, Access and Control -...
En autorisant un plus grand nombre d'enfants sous un même nœud qu'un arbre binaire de recherche auto-équilibré classique , l'arbre B réduit sa hauteur et répartit les données dans un nombre réduit de blocs distincts. Ceci est particulièrement important pour les arbres stockés sur un support de stockage secondaire (par exemple, un disque dur), car ces systèmes présentent une latence relativement élevée et traitent des blocs de données relativement volumineux ; d'où l'utilisation de l'arbre B dans les bases de données et les systèmes de fichiers . Cet avantage demeure majeur lorsque l'arbre est stocké en mémoire, car les systèmes informatiques modernes dépendent fortement des caches du processeur . Comparée à la lecture depuis le cache, la lecture depuis la mémoire après un défaut de cache est nettement plus lente.
laboratoires de recherche de Boeing , Rudolf Bayer et Edward M. McCreight ont inventé les arbres B pour gérer efficacement les pages d'index des grands fichiers à accès aléatoire. Leur hypothèse de base était que les index seraient si volumineux que seules de petites portions de l'arbre pourraient tenir en mémoire vive. L'article de Bayer et McCreight, « Organization and maintenance of large ordered index » a été diffusé pour la première fois en juillet 1970, puis publié dans Acta Informatica .
Bayer et McCreight n'ont jamais expliqué la signification du B , le cas échéant ; Boeing , balanced , between , broad , bushy et Bayer ont été proposés. À la question : « Que signifie le B dans B-Tree ? », McCreight a répondu :
Tout le monde le fait !
Vous n'imaginez pas où une simple conversation à l'heure du déjeuner peut mener. Bref, Rudy et moi étions là, à déjeuner. Il fallait trouver un nom pour le truc… On travaillait chez Boeing à l'époque, mais on ne pouvait pas l'utiliser sans consulter les avocats. Alors voilà, il y a un B.
Cela a un rapport avec l'équilibre B. Il y a un autre B.
Rudy était l'auteur principal. Rudy (Bayer) avait plusieurs années de plus que moi et avait publié bien plus de titres que moi. Voilà donc un autre B.
Et donc, à table, nous n'avons jamais réussi à déterminer s'il y en avait une qui paraissait plus sensée que les autres.
Ce que Rudy aime à dire, c'est que plus vous réfléchissez à ce que signifie le B dans B-Tree, mieux vous comprenez les B-Trees !
Chaque nœud, à l'exception de la racine et des feuilles, a au moins ⌈ m /2⌉ enfants.
Le nœud racine possède au moins deux enfants, sauf s'il s'agit d'une feuille.
Toutes les feuilles apparaissent au même niveau.
Un nœud non-feuille avec k enfants contient k − 1 clés.
Les clés de chaque nœud non-feuille servent de valeurs de séparation pour diviser ses sous-arbres. Par exemple, si un nœud interne possède 3 nœuds enfants (ou sous-arbres), il doit avoir 2 clés : 1 et 2. Toutes les valeurs du sous-arbre le plus à gauche seront inférieures à 1 , toutes les valeurs du sous-arbre du milieu seront comprises entre 1 et 2 , et toutes les valeurs du sous-arbre le plus à droite seront supérieures à 2 .
Nœuds internes
Internal nodes (also known as inner nodes) are all nodes except for leaf nodes and the root node. They are usually represented as an ordered set of elements and child pointers. Every internal node contains a maximum of U children and a minimum of L children. Thus, the number of elements is always 1 less than the number of child pointers (the number of elements is between L−1 and U−1). U must be either 2L or 2L−1; therefore, each internal node is at least half full. The relationship between U and L implies that two half-full nodes can be joined to make a legal node, and one full node can be split into two legal nodes (if there's room to push one element up into the parent). These properties make it possible to delete and insert new values into a B-tree while also adjusting the tree to preserve its properties.
The root node
The root node's number of children has the same upper limit as internal nodes but has no lower limit. For example, when there are fewer than L−1 elements in the entire tree, the root will be the only node in the tree with no children at all.
Leaf nodes
In Knuth's terminology, the "leaf" nodes are the actual data objects/chunks. The internal nodes that are one level above these leaves are what would be called the "leaves" by other authors: these nodes only store keys (at most m-1, and at least m/2-1 if they are not the root) and pointers (one for each key) to nodes carrying the data objects/chunks.
A B-tree of depth n+1 can hold about U times as many items as a B-tree of depth n, but the cost of search, insert, and delete operations grows with the depth of the tree. As with any balanced tree, the cost grows much more slowly than the number of elements.
Some balanced trees store values only at leaf nodes and use different kinds of nodes for leaf nodes and internal nodes. B-trees keep values in every node in the tree except leaf nodes.
Differences in terminology
The literature on B-trees is not uniform in its terminology.
Bayer et McCreight (1972) , Comer (1979) et d'autres auteurs définissent l' ordre d'un arbre B comme le nombre minimal de clés dans un nœud non racine. Folk et Zoellick soulignent l'ambiguïté de cette terminologie, le nombre maximal de clés étant incertain. Un arbre B d'ordre 3 peut contenir au maximum 6 clés ou 7 clés. Knuth (1998) contourne ce problème en définissant l' ordre comme le nombre maximal d'enfants (soit un de plus que le nombre maximal de clés)
Le terme « feuille » est également sujet à controverse. Bayer et McCreight (1972) considéraient le niveau feuille comme le niveau de clés le plus bas, tandis que Knuth le définissait comme le niveau inférieur. De nombreuses implémentations sont possibles. Dans certaines architectures, les feuilles peuvent contenir l'enregistrement de données complet ; dans d'autres, elles ne contiennent que des pointeurs vers cet enregistrement. Ces choix ne sont pas fondamentaux pour le concept d'arbre B.
Par souci de simplicité, la plupart des auteurs supposent qu'un nœud peut contenir un nombre fixe de clés. L'hypothèse de base est que la taille de la clé et celle du nœud sont toutes deux fixes. En pratique, des clés de longueur variable peuvent être utilisées.
description informelle
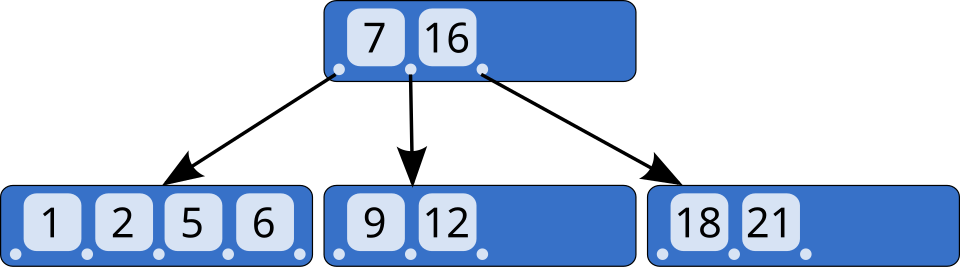
Un arbre B Bayer & McCreight 1972 ) d'ordre 5 Knuth 1998 )
Structure des nœuds
Comme pour les autres arbres, les arbres B peuvent être représentés comme une collection de trois types de nœuds : racine , interne (ou intérieur) et feuille .
Veuillez noter les définitions de variables suivantes :
Tous les nœuds feuilles ont le même nombre d'ancêtres (c'est-à-dire qu'ils sont tous à la même profondeur).
Chaque nœud interne d'un arbre B a le format suivant :
structure interne des nœuds
pt 0
k 0
partie 1
pr 0
k 1
partie 2
pr 1
...
k K -1
pt K
pr K -1
structure de pointeur de nœud interne
structure des nœuds feuilles
pr 0
k 0
pr 1
k 1
...
pr K -1
k K -1
structure de pointeur de nœud feuille
Type de nœud
nombre de clés
nombre de nœuds enfants
Min
Max
Min
Max
nœud racine lorsqu'il s'agit d'un nœud feuille
0
Nœud interne
nœud feuille
degré minimal (ou facteur de branchement) de l'arbre. Un facteur de 2 garantit la possibilité de diviser ou de fusionner les nœuds.
If an internal node has keys, then adding a key to that node can be accomplished by splitting the hypothetical key node into two keys; joining the neighbor would add keys.
A B-tree is kept balanced after insertion by splitting a would-be overfilled node, of keys, into two keys, in which case the two siblings and parent are merged, reducing the depth by one.
This depth will increase slowly as elements are added to the tree, but an increase in the overall depth is infrequent, and results in all leaf nodes being one more node farther away from the root.
Comparison to other trees
Because a range of child nodes is permitted, B-trees do not need re-balancing as frequently as other self-balancing search trees, but may waste some space since nodes are not entirely full.
B-trees have substantial advantages over alternative implementations when the time to access the data of a node greatly exceeds the time spent processing that data, because the cost of accessing the node may then be amortized over multiple operations within the node. This usually occurs when the node data are stored in secondary storage, such as disk drives. By maximizing the number of keys within each internal node, the height of the tree decreases, and the number of expensive node accesses is reduced. In addition, rebalancing of the tree occurs less frequently. The maximum number of child nodes depends on the information that must be stored for each child node and the size of a full disk block or an analogous size in secondary storage. While 2–3 B-trees are easier to explain, practical B-trees using secondary storage need a large number of child nodes to improve performance.
Variants
Le terme « arbre B » peut désigner une structure spécifique ou une classe générale de structures. Au sens strict, un arbre B stocke les clés dans ses nœuds internes, mais pas nécessairement dans les enregistrements de ses feuilles. La classe générale inclut des variantes telles que l' arbre B+ , l'arbre B * et l' arbre B *+ .
Dans un arbre B+ , les nœuds internes ne stockent aucun pointeur vers les enregistrements ; tous les pointeurs vers les enregistrements sont donc stockés dans les nœuds feuilles. De plus, un nœud feuille peut inclure un pointeur vers le nœud feuille suivant afin d'accélérer l'accès séquentiel. Comme les nœuds internes d'un arbre B+ contiennent moins de pointeurs, chaque nœud peut contenir davantage de clés, ce qui rend l'arbre moins profond et donc la recherche plus rapide.
L'arbre B * équilibre davantage les nœuds internes voisins afin d'obtenir un réseau plus dense. Cette variante garantit que les nœuds non racines sont remplis au moins aux deux tiers au lieu de la moitié. L'opération la plus coûteuse lors de l'insertion d'un nœud dans un arbre B étant sa division, les arbres B * sont conçus pour retarder cette opération autant que possible. Pour ce faire, au lieu de diviser immédiatement un nœud lorsqu'il est plein, ses clés sont partagées avec un nœud voisin. Cette opération de partage est moins coûteuse que la division car elle nécessite uniquement le déplacement des clés entre les nœuds existants, sans allocation de mémoire pour un nouveau nœud. Lors de l'insertion, on vérifie d'abord si le nœud dispose d'espace libre ; si c'est le cas, la nouvelle clé y est insérée. Cependant, si le nœud est plein (il contient B+ et B * .
Les arbres B peuvent être transformés en arbres de statistiques d'ordre pour permettre des recherches rapides du Nème enregistrement dans l'ordre des clés, ou le comptage du nombre d'enregistrements entre deux enregistrements quelconques, et diverses autres opérations connexes.
Utilisation des arbres B dans les bases de données
la notation d'ordre . Par exemple, une recherche binaire dans une table triée contenant temps d'accès et du délai de rotation. Le temps d'accès peut varier de 0 à 20 millisecondes, voire plus, et le délai de rotation est en moyenne environ la moitié de la période de rotation. Pour un disque dur à 7 200 tr/min, la période de rotation est de 8,33 millisecondes. Pour un disque tel que le Seagate ST3500320NS, le temps d'accès entre deux pistes est de 0,8 milliseconde et le temps d'accès moyen en lecture est de 8,5 millisecondes. Par souci de simplification, supposons que la lecture sur disque prenne environ 10 millisecondes.
Le temps nécessaire pour localiser un enregistrement parmi un million dans l'exemple ci-dessus serait de 20 lectures de disque, chacune prenant 10 millisecondes, ce qui équivaut à 0,2 seconde.
Le temps de recherche est réduit car les enregistrements individuels sont regroupés dans un bloc disque . Un bloc disque peut avoir une taille de 16 kilo-octets. Si chaque enregistrement fait 160 octets, alors 100 enregistrements peuvent être stockés dans chaque bloc. Le temps de lecture disque mentionné ci-dessus correspond en réalité à un bloc entier. Une fois la tête de lecture/écriture positionnée, un ou plusieurs blocs disque peuvent être lus avec un délai minimal. Avec 100 enregistrements par bloc, les six dernières comparaisons environ ne nécessitent aucune lecture disque : elles sont toutes effectuées dans le dernier bloc disque lu.
Pour accélérer encore la recherche, il faut réduire le temps nécessaire pour effectuer les 13 à 14 premières comparaisons (qui nécessitaient chacune un accès disque).
performance de l'indice
Un index B-tree permet d'améliorer les performances. Il crée une structure arborescente à plusieurs niveaux qui divise la base de données en blocs ou pages de taille fixe. Chaque niveau de cet arbre permet de lier ces pages via une adresse, autorisant ainsi une page (appelée nœud ou page interne) à référencer une autre, les pages feuilles se trouvant au niveau le plus bas. Une page constitue généralement le point de départ de l'arbre, ou « racine ». C'est à partir de cette page que commence la recherche d'une clé particulière, en parcourant un chemin qui se termine dans une feuille. La plupart des pages de cette structure sont des pages feuilles qui font référence à des lignes spécifiques de la table.
Comme chaque nœud (ou page interne) peut avoir plus de deux enfants, un index de type arbre B aura généralement une hauteur plus faible (la distance entre la racine et la feuille la plus éloignée) qu'un arbre binaire de recherche. Dans l'exemple ci-dessus, les lectures initiales sur disque ont réduit de moitié la plage de recherche. On peut améliorer cela en créant un index auxiliaire contenant le premier enregistrement de chaque bloc disque (parfois appelé index clairsemé ). Cet index auxiliaire représenterait 1 % de la taille de la base de données d'origine, mais sa recherche serait rapide. La présence d'une entrée dans l'index auxiliaire nous indiquerait le bloc à interroger dans la base de données principale ; après cette interrogation, il suffirait de parcourir ce bloc précis de la base de données principale, moyennant une lecture disque supplémentaire.
Dans l'exemple ci-dessus, l'index contiendrait 10 000 entrées et nécessiterait au maximum 14 comparaisons pour renvoyer un résultat. Comme pour la base de données principale, les six dernières comparaisons environ de l'index auxiliaire seraient effectuées sur le même bloc disque. La recherche dans l'index pourrait être effectuée en environ huit lectures disque, et l'accès à l'enregistrement souhaité en neuf lectures disque.
La création d'un index auxiliaire peut être répétée pour créer un index auxiliaire à partir de l'index auxiliaire. On obtiendrait ainsi un index auxiliaire-auxiliaire ne nécessitant que 100 entrées et tenant dans un seul bloc disque.
Au lieu de lire 14 blocs de disque pour trouver l'enregistrement recherché, il suffit d'en lire 3. Ce principe de blocage est à la base de la création de l'arbre B, où les blocs de disque forment une hiérarchie de niveaux constituant l'index. La lecture et la recherche du premier (et unique) bloc de l'index aux-aux, qui est la racine de l'arbre, identifient le bloc pertinent dans l'index aux du niveau inférieur. La lecture et la recherche de ce bloc de l'index aux permettent d'identifier le bloc pertinent à lire jusqu'au dernier niveau, appelé niveau feuille, qui identifie un enregistrement dans la base de données principale. Au lieu de 150 millisecondes, il ne faut plus que 30 millisecondes pour obtenir l'enregistrement.
Les index auxiliaires ont transformé le problème de recherche d'une recherche binaire nécessitant environ cache disque , évitant ainsi une lecture disque. L'arbre B reste l'implémentation d'index standard dans la quasi-totalité des bases de données relationnelles , et de nombreuses bases de données non relationnelles l'utilisent également.
Insertions et suppressions
Si la base de données reste inchangée, la compilation de l'index est simple et celui-ci n'a jamais besoin d'être modifié. En cas de modifications, la gestion de la base de données et de son index requiert des ressources de calcul supplémentaires.
Supprimer des enregistrements d'une base de données est relativement simple. L'index reste inchangé et l'enregistrement est simplement marqué comme supprimé. La base de données conserve son ordre de tri. Cependant, en cas de nombreuses suppressions différées , la recherche et le stockage deviennent moins performants.
Dans un fichier séquentiel trié, l'insertion d'un enregistrement peut s'avérer très lente, car il est nécessaire de libérer de l'espace. Insérer un enregistrement avant le premier implique de décaler tous les enregistrements vers le bas. Une telle opération est tout simplement trop coûteuse pour être pratique. Une solution consiste à ménager des espaces. Au lieu de tasser tous les enregistrements dans un bloc, ce dernier peut comporter des espaces libres pour permettre des insertions ultérieures. Ces espaces seraient marqués comme s'il s'agissait d'enregistrements « supprimés ».
Les insertions et les suppressions sont rapides tant qu'il y a de l'espace disponible sur un bloc. Si une insertion ne peut pas être effectuée sur le bloc, il faut trouver de l'espace libre sur un bloc voisin et ajuster les indices auxiliaires. Dans le meilleur des cas, il y a suffisamment d'espace disponible à proximité pour minimiser la réorganisation des blocs. Une autre solution consiste à utiliser des blocs de disque hors séquence.
Utilisation dans les bases de données
L'arbre B utilise tous les concepts décrits ci-dessus. Plus précisément, un arbre B :
conserve les clés triées pour un parcours séquentiel
utilise un index hiérarchique pour minimiser le nombre de lectures de disque
utilise des blocs partiellement remplis pour accélérer les insertions et les suppressions
maintient l'index équilibré grâce à un algorithme récursif
De plus, un arbre B minimise le gaspillage en veillant à ce que les nœuds internes soient remplis au moins à moitié. Un arbre B peut gérer un nombre arbitraire d'insertions et de suppressions.
hauteurs dans le meilleur et le pire des cas
Soit
Soit le nombre minimal d'enfants qu'un nœud interne (non racine) doit avoir. Pour un arbre B ordinaire,
Comer (1979) et Cormen et al. (2001) donnent la hauteur dans le pire des cas (la hauteur maximale) d'un arbre B comme :
Algorithmes
La recherche binaire est généralement (mais pas nécessairement) utilisée dans les nœuds pour trouver les valeurs de séparation et l'arbre enfant d'intérêt.
Insertion
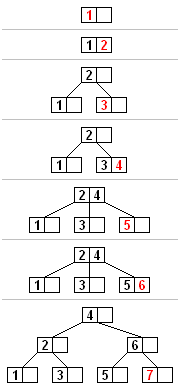
Exemple d'insertion dans un arbre B avec chaque itération. Les nœuds de cet arbre B ont au maximum 3 enfants (ordre de Knuth 3).
Toute insertion commence par un nœud feuille. Pour insérer un nouvel élément, parcourez l'arbre jusqu'à trouver le nœud feuille où l'élément doit être ajouté. Insérez ensuite le nouvel élément dans ce nœud en suivant les étapes suivantes :
Si le nœud contient moins d'éléments que le nombre maximal autorisé, il y a de la place pour le nouvel élément. Insérez-le dans le nœud en conservant l'ordre des éléments.
Sinon, si le nœud est plein, divisez-le en deux nœuds égaux, donc :
On choisit une seule médiane parmi les éléments de la feuille et le nouvel élément inséré.
Les valeurs inférieures à la médiane sont placées dans le nouveau nœud gauche, et les valeurs supérieures à la médiane sont placées dans le nouveau nœud droit, la médiane servant de valeur de séparation.
La valeur de séparation est insérée dans le nœud parent, ce qui peut entraîner sa division, et ainsi de suite. Si le nœud n'a pas de parent (c'est-à-dire s'il s'agit de la racine), une nouvelle racine est créée au-dessus de ce nœud (ce qui augmente la hauteur de l'arbre).
Si la division remonte jusqu'à la racine, elle crée une nouvelle racine avec une seule valeur de séparation et deux enfants. C'est pourquoi la limite inférieure de la taille des nœuds internes ne s'applique pas à la racine. Le nombre maximal d'éléments par nœud est U − 1. Lorsqu'un nœud est divisé, un élément est déplacé vers le parent, et un élément est ajouté. Il doit donc être possible de diviser le nombre maximal U − 1 éléments en deux nœuds valides. Si ce nombre est impair, alors U = 2L et l'un des nouveaux nœuds contient ( U − 2)/2 = L − 1 éléments, et est donc un nœud valide. L'autre contient un élément supplémentaire, et est donc également valide. Si U − 1 est pair, alors U = 2L − 1, donc le nœud contient 2L − 2 éléments. La moitié de ce nombre est L − 1, qui est le nombre minimal d'éléments autorisés par nœud.
Un autre algorithme permet de parcourir l'arbre en une seule passe, de la racine au nœud d'insertion, en divisant préventivement les nœuds pleins rencontrés. Ceci évite de devoir charger les nœuds parents en mémoire, une opération potentiellement coûteuse s'ils sont stockés sur un support secondaire. Cependant, pour utiliser cet algorithme, il faut pouvoir envoyer un élément au parent et diviser les U − 2 éléments restants en deux nœuds valides, sans ajouter de nouvel élément. Cela implique que U = 2L et non U = 2L − 1, ce qui explique pourquoi certains ouvrages de référence imposent cette condition pour définir les arbres B.algorithme spécifique de « chargement en masse » pour obtenir un arbre plus efficace avec un facteur de branchement plus élevé.
Une fois les données triées, toutes les insertions se font à l'extrémité droite de l'arbre. En particulier, lorsqu'un nœud est divisé, on a la garantie qu'aucune insertion supplémentaire n'aura lieu dans sa moitié gauche. Lors du chargement en masse, on tire parti de cette propriété et, au lieu de diviser uniformément les nœuds surchargés, on les divise de la manière la plus inégale possible : on laisse le nœud gauche complètement rempli et on crée un nœud droit sans clé et avec un seul enfant (en violation des règles habituelles des arbres B).
À la fin du chargement en masse, l'arbre est composé presque exclusivement de nœuds entièrement remplis ; seul le nœud le plus à droite de chaque niveau peut être partiellement rempli. Comme ces nœuds peuvent également être partiellement remplis , pour rétablir les règles normales d'un arbre B, on les combine avec leurs frères gauches (garantis pleins) et on divise les clés afin d'obtenir deux nœuds au moins partiellement remplis. Le seul nœud qui n'a pas de frère gauche entièrement rempli est la racine, qui peut donc être partiellement remplie.
Dans les systèmes de fichiers
Outre son utilisation dans les bases de données, l'arbre B (ou
Certains systèmes d'exploitation anciens, ainsi que certains systèmes très spécialisés, exigeaient que l'application alloue la taille maximale d'un fichier lors de sa création. Le fichier pouvait alors être alloué sous forme de blocs de disque contigus. Dans ce cas, pour convertir l'adresse du bloc de fichier en adresse de bloc de disque, le système d'exploitation ajoutait simplement l'adresse du bloc de fichier à l'adresse du premier bloc de disque constituant le fichier. Ce procédé est simple, mais la taille du fichier ne pouvait pas dépasser celle qui lui avait été attribuée lors de sa création.
Tous les systèmes d'exploitation modernes et courants permettent la croissance des fichiers. Les blocs de disque résultants peuvent ne pas être contigus, ce qui complexifie la correspondance entre les blocs logiques et les blocs physiques.
MS-DOS , par exemple, utilisait une simple table d'allocation de fichiers (FAT). La FAT contient une entrée pour chaque bloc disque , indiquant si le bloc est utilisé par un fichier et, le cas échéant, quel est le bloc suivant (s'il existe) pour ce même fichier. L'allocation de chaque fichier est donc représentée par une liste chaînée dans la table. Pour trouver l'adresse disque d'un bloc de fichier , le système d'exploitation (ou l'utilitaire de disque) doit parcourir séquentiellement la liste chaînée du fichier dans la FAT. Pire encore, pour trouver un bloc disque libre, il doit parcourir la FAT séquentiellement. Pour MS-DOS, cela ne représentait pas un inconvénient majeur car les disques et les fichiers étaient petits et la FAT comportait peu d'entrées et des chaînes de fichiers relativement courtes. Dans le système de fichiers FAT12 (utilisé sur les disquettes et les premiers disques durs), il n'y avait pas plus de 4 080 entrées, et la FAT résidait généralement en mémoire. Avec l'augmentation de la capacité des disques, l'architecture FAT a commencé à présenter des limitations. Sur un disque de grande capacité utilisant FAT, il peut être nécessaire d'effectuer des lectures disque pour déterminer l'emplacement d'un bloc de fichier à lire ou à écrire.
TOPS-20 utilisait un arbre à deux niveaux (0 à 2) similaire à un arbre B. Un bloc disque était constitué de 512 mots de 36 bits. Si le fichier tenait dans un bloc de 512 mots (2⁹ ) , le répertoire du fichier pointait vers ce bloc disque physique. Si le fichier tenait dans 2¹⁸ mots , le répertoire pointait vers un index auxiliaire ; les 512 mots de cet index étaient soit nuls (le bloc n'était pas alloué), soit pointaient vers l'adresse physique du bloc. Si le fichier tenait dans 2²⁷ mots , le répertoire pointait vers un bloc contenant un index auxiliaire-auxiliaire ; chaque entrée était soit nulle, soit pointait vers un index auxiliaire. Par conséquent, le bloc disque physique d'un fichier de 2²⁷ mots pouvait être localisé en deux lectures disque et lu en une troisième.Les systèmes de fichiers HFS+ et APFS d'Apple , NTFS de Microsoft , AIX (jfs2) et certains systèmes de fichiers Linux , tels que Bcachefs , Btrfs et ext4 , utilisent des arbres B.
liste à sauts , les deux structures offrent des performances similaires, mais l'arbre B s'adapte mieux aux grandes valeurs de n . Un arbre T , utilisé dans les systèmes de bases de données en mémoire vive , est comparable mais plus compact.
Variations
concurrence d'accès
Lehman et Yao ont démontré que tous les verrous de lecture pouvaient être évités (et l'accès concurrent grandement amélioré) en reliant les blocs de l'arbre à chaque niveau par un pointeur « suivant ». Il en résulte une structure arborescente où les opérations d'insertion et de recherche descendent de la racine vers les feuilles. Les verrous d'écriture ne sont nécessaires que lors de la modification d'un bloc. Ceci maximise la concurrence d'accès pour plusieurs utilisateurs, un aspect important pour les bases de données et autres méthodes de stockage ISAM basées sur les arbres B. En contrepartie, les pages vides ne peuvent pas être supprimées de l'arbre B pendant les opérations normales. (Des stratégies permettent d'implémenter la fusion de nœuds. )
Le brevet américain n° 5283894, délivré en 1994, semble décrire une méthode d'accès méta permettant l'accès et la modification simultanés d'un arbre B+ sans verrouillage. Cette technique accède à l'arbre « en remontant » pour les recherches et les mises à jour grâce à des index en mémoire supplémentaires pointant vers les blocs de chaque niveau du cache de blocs. Aucune réorganisation n'est nécessaire pour les suppressions et, contrairement à la méthode de Lehman et Yao, aucun pointeur « suivant » n'est présent dans chaque bloc.
Un arbre Maple est un arbre B développé pour être utilisé dans le noyau Linux afin de réduire les conflits de verrouillage dans la gestion de la mémoire virtuelle.
Arbre (a,b)
Les arbres (a,b) sont des généralisations des arbres B. Les arbres B imposent à chaque nœud interne un nombre minimal et maximal d' enfants, pour une valeur prédéfinie de a et b . À l'inverse, un arbre (a,b) permet de fixer arbitrairement bas le nombre minimal d'enfants d'un nœud interne. Dans un arbre (a,b), chaque nœud interne possède entre
Plus d articles de Worldlex Wiki
Revenez a l index pour explorer davantage de pages sur l histoire, la science, la culture, la geographie et la societe en francais.