
Un nuage de points , également appelé diagramme de dispersion , est un type de graphique ou de diagramme mathématique utilisant des coordonnées cartésiennes pour afficher les valeurs de deux variables pour un ensemble de données. Si les points sont codés (couleur, forme, taille), une variable supplémentaire peut être affichée. Les données sont représentées sous forme de points, chacun ayant la valeur d'une variable déterminant sa position sur l'axe horizontal et la valeur de l'autre variable déterminant sa position sur l' axe vertical . Le nuage de points est l'un des sept outils de base du contrôle qualité.
Histoire
Selon Michael Friendly et Daniel Denis, la caractéristique déterminante qui distingue les nuages de points des graphiques linéaires est la représentation d'observations spécifiques de données bivariées, où une variable est portée sur l'axe horizontal et l'autre sur l'axe vertical. Ces deux variables sont souvent issues d'une représentation physique, comme la dispersion des balles sur une cible ou une projection géographique ou céleste.
Bien qu'Edmund Halley ait créé un graphique bivarié de la température et de la pression en 1686, il a omis les points de données précis utilisés pour démontrer la relation. Friendly et Denis affirment que sa visualisation était différente d'un véritable nuage de points. Ils attribuent le premier nuage de points à John Herschel . En 1833, Herschel a représenté graphiquement l'angle entre l'étoile centrale de la constellation de la Vierge et Gamma Virginis au fil du temps afin de déterminer comment cet angle évolue, non pas par le calcul, mais par un dessin à main levée et son appréciation.
Sir Francis Galton a étendu et popularisé le nuage de points et de nombreux autres outils statistiques afin de fournir une base scientifique à l'eugénisme. Lorsqu'en 1886, Galton publia un nuage de points et une ellipse de corrélation de la taille des parents et des enfants, il perfectionna la méthode de Herschel consistant à représenter des points de données en regroupant et en moyennant les cellules adjacentes pour obtenir une visualisation plus lisse. Karl Pearson, R.A. Fischer et d'autres statisticiens et eugénistes s'appuyèrent sur les travaux de Galton et formalisèrent les corrélations et les tests de signification.
Aperçu
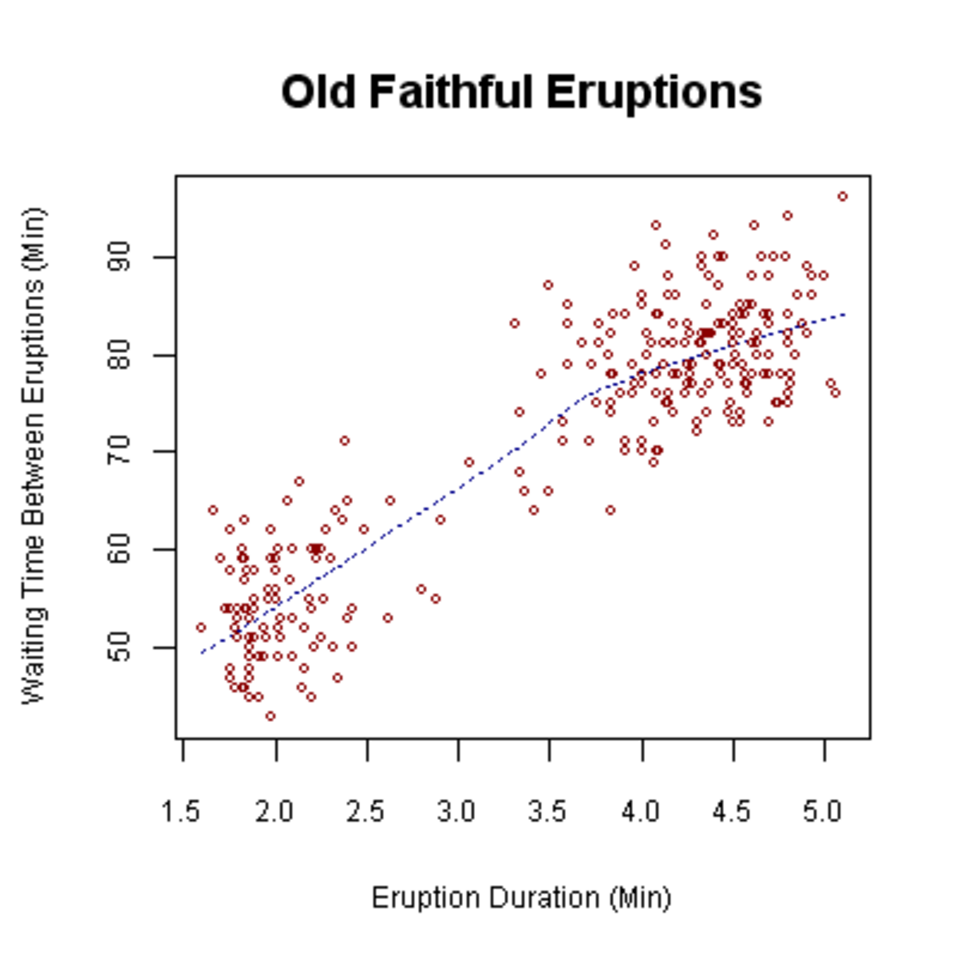
Un nuage de points peut être utilisé soit lorsqu'une variable continue est contrôlée par l'expérimentateur et que l'autre en dépend, soit lorsque les deux variables continues sont indépendantes. Si un paramètre est systématiquement incrémenté et/ou décrémenté par l'autre, il est appelé paramètre de contrôle ou variable indépendante et est généralement représenté sur l'axe horizontal. La variable mesurée ou dépendante est généralement représentée sur l'axe vertical. En l'absence de variable dépendante, les deux types de variables peuvent être représentés sur n'importe quel axe et le nuage de points illustrera uniquement le degré de corrélation (et non de causalité ) entre deux variables.
Un nuage de points peut suggérer différents types de corrélations entre des variables, avec un certain intervalle de confiance . Par exemple, le poids et la taille seraient représentés sur l' axe des ordonnées ( y ) , et la taille sur l' axe des abscisses ( x ). Les corrélations peuvent être positives (croissantes), négatives (décroissantes) ou nulles (absence de corrélation). Si la pente de la courbe est orientée du bas à gauche vers le haut à droite, cela indique une corrélation positive entre les variables étudiées. Si elle est orientée du haut à gauche vers le bas à droite, cela indique une corrélation négative. Une droite de régression (ou courbe de tendance) peut être tracée pour étudier la relation entre les variables. Une équation de corrélation entre les variables peut être déterminée par des méthodes d'ajustement linéaire. Pour une corrélation linéaire, la méthode d'ajustement est appelée régression linéaire et garantit une solution correcte en un temps fini. Aucune méthode d'ajustement linéaire universelle ne garantit une solution correcte pour toutes les relations. Un nuage de points est également très utile pour observer comment deux ensembles de données comparables présentent des relations non linéaires entre les variables. La capacité à faire cela peut être améliorée en ajoutant une ligne lisse telle que LOESS . De plus, si les données sont représentées par un modèle de mélange de relations simples, ces relations seront visuellement évidentes sous forme de modèles superposés.
Le diagramme de dispersion est l'un des sept outils de base du contrôle de la qualité .
Les graphiques de dispersion peuvent être construits sous forme de graphiques à bulles , à marqueurs ou/et à lignes .
Exemple

Par exemple, pour établir un lien entre la capacité pulmonaire d'une personne et sa capacité à retenir sa respiration, un chercheur sélectionnerait un groupe de personnes, puis mesurerait la capacité pulmonaire de chacune (première variable) et la durée de leur apnée (seconde variable). Le chercheur représenterait ensuite les données sur un nuage de points, en plaçant la « capacité pulmonaire » sur l'axe horizontal et la « durée d'apnée » sur l'axe vertical.
Une personne ayant une capacité pulmonaire de400 cl qui ont retenu leur souffle pourLa durée de 21,7 s serait représentée par un point unique sur le nuage de points, aux coordonnées cartésiennes (400 ; 21,7) . Ce nuage de points, regroupant toutes les données des participants, permettrait au chercheur de comparer visuellement les deux variables et d’identifier une éventuelle relation entre elles.
Matrices de nuages de points
Pour un ensemble de variables de données (dimensions) X₁ , X₂ , ..., Xₖ , la matrice de nuages de points affiche tous les nuages de points par paires des variables sur une seule vue, sous forme de plusieurs nuages de points organisés en matrice. Pour k variables , la matrice de nuages de points comporte k lignes et k colonnes. Un point situé à l'intersection de la i -ème ligne et de la j -ème colonne représente la variable Xᵢ en fonction de la variable Xⱼ . [ 10 que chaque ligne et chaque colonne correspondent à une dimension, et que chaque cellule représente un nuage de points bidimensionnel.
Une matrice de nuages de points généralisée offre diverses possibilités de représentation de paires de variables catégorielles et quantitatives. Un diagramme en mosaïque , un diagramme de fluctuations ou un histogramme à facettes peuvent être utilisés pour représenter deux variables catégorielles. D'autres types de graphiques sont utilisés pour une variable catégorielle et une variable quantitative.
