"
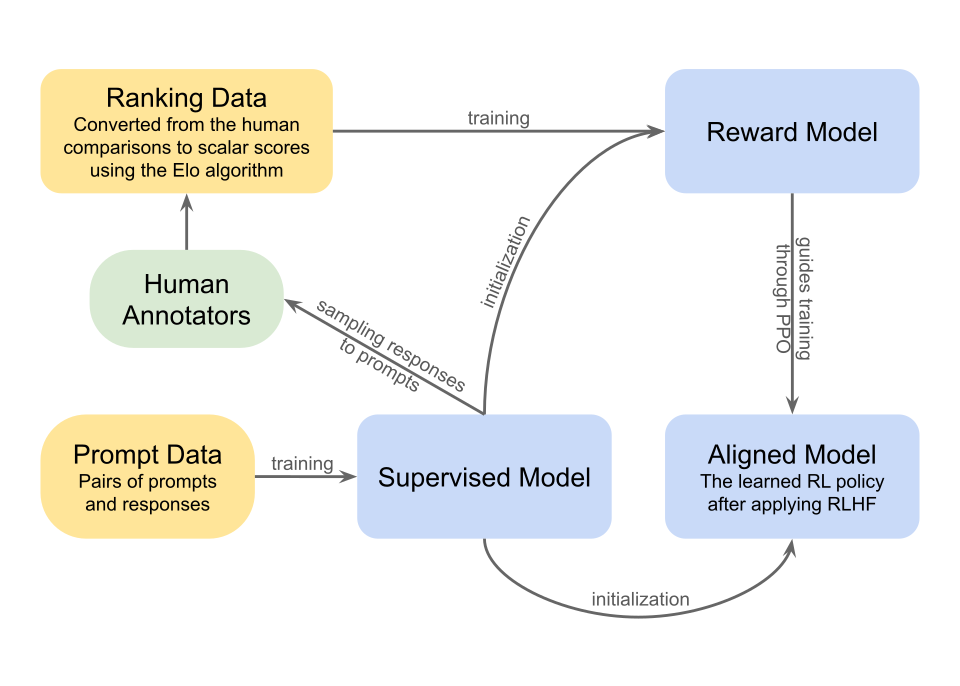
Dans l'apprentissage par renforcement classique, l'objectif d'un agent intelligent est d'apprendre une fonction qui guide son comportement, appelée politique . Cette fonction est optimisée itérativement afin d'accroître le signal de récompense issu de la performance de l'agent. Cependant, définir explicitement une fonction de récompense qui approxime précisément les préférences humaines est complexe. C'est pourquoi l'apprentissage par renforcement à haute résolution (RLHF) vise à entraîner un « modèle de récompense » directement à partir des retours humains . Ce modèle est d'abord entraîné de manière supervisée afin de prédire si une réponse à une invite donnée est pertinente (récompense élevée) ou non (récompense faible), en se basant sur les données de classement collectées auprès d' annotateurs humains . Ce modèle sert ensuite de fonction de récompense pour améliorer la politique de l'agent grâce à un algorithme d'optimisation tel que l'optimisation de politique proximale .
L'apprentissage par renforcement basé sur les préférences humaines ( RLHF) trouve des applications dans divers domaines de l'apprentissage automatique, notamment le traitement automatique du langage naturel ( résumé de texte , agents conversationnels ), la vision par ordinateur (modèles de conversion texte-image ) et le développement de bots pour jeux vidéo . Bien que le RLHF soit une méthode efficace pour entraîner des modèles à mieux se conformer aux préférences humaines, il se heurte à des difficultés liées à la collecte des données de préférences. Si le RLHF ne nécessite pas d'énormes quantités de données pour améliorer ses performances, l'obtention de données de préférences de haute qualité reste un processus coûteux. De plus, si les données ne sont pas collectées avec soin à partir d'un échantillon représentatif, le modèle résultant peut présenter des biais indésirables .
sûrs , à la fois utiles et inoffensifs (c'est-à-dire sans biais , toxicité ni contenu nuisible). Demander à des humains de créer manuellement des exemples de textes inoffensifs et nuisibles serait difficile et chronophage. Or, les humains sont capables d'évaluer et de comparer rapidement la nocivité de différents textes générés par une IA. Par conséquent, un objectif plus pratique serait de permettre au modèle d'utiliser ce type de retour humain pour améliorer sa génération de textes.Malgré les avantages évidents de l'intégration du retour d'information humain dans l'entraînement des modèles, les efforts précédents, y compris certains qui exploitent l'apprentissage par renforcement (RL), se sont heurtés à des difficultés importantes. La plupart des tentatives étaient soit limitées et difficiles à généraliser, échouant sur des tâches plus complexes , soit confrontées à des difficultés d'apprentissage à partir de fonctions de récompense éparses (manquant d'informations spécifiques et relatives à de grandes quantités de texte à traiter simultanément) ou bruitées (récompensant de manière incohérente des sorties similaires)
L'apprentissage par renforcement basé sur le feedback humain (RLHF) n'est pas la première méthode ayant permis d'exploiter le feedback humain pour l'apprentissage par renforcement, mais il demeure l'une des plus répandues. Le RLHF a été initialement conçu comme une tentative de création d'un algorithme général pour apprendre à partir d'une quantité raisonnable de feedback humain. L'algorithme tel qu'il est utilisé aujourd'hui a été introduit par OpenAI dans un article portant sur l'amélioration de la continuation ou du résumé de texte grâce au feedback humain, et sa popularité a explosé lorsque la même méthode a été réutilisée dans leur article sur InstructGPT . Il a également été démontré que le RLHF améliore la robustesse des agents d'apprentissage par renforcement et leur capacité d' exploration , ce qui se traduit par un processus d'optimisation plus apte à gérer l'incertitude et à explorer efficacement son environnement à la recherche de la récompense maximale.
Recueillir les commentaires humains
Le retour d'information humain est généralement recueilli en invitant les utilisateurs à classer les différentes phases du comportement de l'agent. Ces classements peuvent ensuite servir à évaluer les performances, par exemple à l'aide du système de classement Elo , un algorithme qui calcule le niveau de compétence relatif des joueurs d'un jeu en se basant uniquement sur le résultat de chaque partie. Bien que le classement des performances soit la forme de retour d'information la plus répandue, des recherches récentes ont exploré d'autres formes, telles que le retour d'information numérique, le retour d'information en langage naturel et les incitations à modifier directement les performances du modèle.
L'une des motivations initiales de l'apprentissage par renforcement par renforcement (RLHF) était son efficacité, qui ne nécessite qu'une quantité relativement faible de données de comparaison [8]. démontré qu'une petite quantité de données peut conduire à des résultats comparables à ceux obtenus avec une plus grande quantité. De plus, augmenter la quantité de données tend à être moins efficace qu'augmenter proportionnellement la taille du modèle de récompense [16]. quantité de données plus importante et plus diversifiée peut s'avérer cruciale pour les tâches où il est essentiel d'éviter les biais liés à un groupe d'annotateurs partiellement représentatif
Lorsqu'on apprend à partir du retour d'information humain par comparaison par paires selon le modèle de Bradley-Terry-Luce (ou le modèle de Plackett-Luce pour les comparaisons K-wise portant sur plus de deux comparaisons), l' estimateur du maximum de vraisemblance (EMV) des fonctions de récompense linéaires converge si les données de comparaison sont générées selon un modèle linéaire bien spécifié . Cela implique que, sous certaines conditions, si un modèle est entraîné à déterminer les choix préférés des individus parmi des paires (ou groupes) de choix, il améliorera nécessairement sa capacité à prédire les préférences futures. Cette amélioration est attendue tant que les comparaisons utilisées pour l'apprentissage reposent sur une règle cohérente et simple.
Les deux modèles de collecte de données hors ligne, où le modèle apprend en interagissant avec un ensemble de données statique et en mettant à jour sa politique par lots, ainsi que les modèles de collecte de données en ligne, où le modèle interagit directement avec l'environnement dynamique et met à jour sa politique immédiatement, ont été étudiés mathématiquement, démontrant les bornes de complexité d'échantillonnage pour RLHF sous différents modèles de rétroaction.
Dans le modèle de collecte de données hors ligne, lorsque l'objectif est l'apprentissage de politiques, une estimation du maximum de vraisemblance pessimiste intégrant une borne inférieure de confiance comme estimation de la récompense est la plus efficace. De plus, il a été démontré que, le cas échéant, considérer directement les comparaisons K-wise est asymptotiquement plus efficace que de les convertir en comparaisons par paires à des fins de prédiction.
Dans le contexte en ligne, lorsque le retour d'information humain est recueilli par comparaisons par paires selon le modèle de Bradley-Terry-Luce et que l'objectif est de minimiser le regret de l'algorithme (l'écart de performance par rapport à un agent optimal), il a été démontré qu'un estimateur du maximum de vraisemblance optimiste, intégrant une borne supérieure de confiance comme estimation de la récompense, permet de concevoir des algorithmes efficaces (nécessitant relativement peu de données d'entraînement). Un défi majeur du RLHF, lors de l'apprentissage par comparaisons par paires (ou duels), réside dans la nature non markovienne de ses politiques optimales. Contrairement aux scénarios plus simples où la stratégie optimale ne requiert pas la mémoire des actions passées, en RLHF, la meilleure action à entreprendre dépend souvent des événements et décisions antérieurs, rendant la stratégie intrinsèquement dépendante de la mémoire.
Applications
L'apprentissage par renforcement basé sur les fonctions ( RLHF) a été appliqué à divers domaines du traitement automatique du langage naturel (TALN), tels que les agents conversationnels, la synthèse de texte et la compréhension du langage naturel. L'apprentissage par renforcement classique, où les agents apprennent de leurs actions en fonction d'une « fonction de récompense » prédéfinie, est difficile à appliquer aux tâches de TALN car les récompenses sont souvent difficiles à définir ou à mesurer, notamment pour les tâches complexes impliquant des valeurs ou des préférences humaines. Le RLHF permet d'orienter les modèles de TALN, en particulier les modèles de langage , afin qu'ils fournissent des réponses conformes aux préférences humaines pour ces tâches, en intégrant ces préférences au préalable dans le modèle de récompense. Il en résulte un modèle capable de générer des réponses plus pertinentes et de rejeter les requêtes inappropriées ou non pertinentes. Parmi les exemples notables de modèles de langage entraînés par RLHF, citons ChatGPT d' OpenAI (et son prédécesseur InstructGPT ), Sparrow de DeepMind , Gemini de Google , et Claude d' Anthropic .
En vision par ordinateur, l'algorithme RLHF a également été utilisé pour aligner des modèles texte-image . Les études ayant utilisé avec succès RLHF à cette fin ont constaté que l'utilisation de la régularisation KL dans RLHF, visant à empêcher la politique apprise de trop s'éloigner du modèle non aligné, a contribué à stabiliser le processus d'entraînement en réduisant le surapprentissage du modèle de récompense. Les images finales des modèles entraînés avec la régularisation KL se sont avérées être de qualité significativement supérieure à celles des modèles entraînés sans régularisation KL. D'autres méthodes ont tenté d'intégrer le retour d'information par un entraînement plus direct – basé sur la maximisation de la récompense sans apprentissage par renforcement – mais ont reconnu qu'une approche basée sur RLHF serait probablement plus performante grâce à la génération d'échantillons en ligne utilisée dans RLHF lors des mises à jour, ainsi qu'à la régularisation KL susmentionnée sur le modèle précédent, qui atténue le surapprentissage de la fonction de récompense.
L'apprentissage par renforcement basé sur les préférences humaines ( RLHF) a d'abord été appliqué à d'autres domaines, comme le développement de bots pour jeux vidéo et les tâches de robotique simulée . Par exemple, OpenAI et DeepMind ont entraîné des agents à jouer à des jeux Atari en se basant sur les préférences humaines. Dans l'entraînement classique de ces bots par RL, la fonction de récompense est simplement corrélée à la performance de l'agent dans le jeu, généralement à l'aide de métriques comme le score . En comparaison, avec le RLHF, un humain visualise périodiquement deux extraits vidéo du comportement de l'agent dans le jeu et doit choisir celui qui lui semble le plus convaincant. Cette approche permet aux agents d'atteindre un niveau compétitif sans jamais avoir accès à leur score. En effet, il a été démontré que le RLHF peut parfois surpasser les performances du RL avec des métriques de score, car les préférences humaines peuvent contenir des informations plus pertinentes que les métriques de performance. Les agents ont obtenu d'excellents résultats dans de nombreux environnements testés, surpassant souvent les performances humaines.
Entraînement
En RLHF, deux modèles distincts sont entraînés : un modèle de récompense et une politique d’apprentissage par renforcement . Le modèle de récompense apprend à déterminer les comportements souhaitables en fonction des retours humains, tandis que la politique, guidée par le modèle de récompense, détermine les actions de l’agent. Ces deux modèles sont généralement initialisés à l’aide d’un modèle de langage autorégressif pré-entraîné . Ce modèle est ensuite entraîné de manière supervisée sur un ensemble de données relativement restreint, composé de paires de requêtes adressées à un assistant et de leurs réponses correspondantes, rédigées par des annotateurs humains.
Modèle de récompense
Le modèle de récompense est une fonction qui prend une chaîne de caractères (un morceau de texte) en entrée et produit un seul nombre, qui est la « récompense ».
Il est généralement initialisé avec un modèle pré-entraîné, ce qui lui confère une compréhension du langage et concentre l'entraînement explicitement sur l'apprentissage des préférences humaines. Outre son utilisation pour initialiser le modèle de récompense et la politique d'apprentissage par renforcement, le modèle sert ensuite à échantillonner les données à comparer par les annotateurs.
Le modèle de récompense est ensuite entraîné en remplaçant la dernière couche du modèle précédent par une tête de régression initialisée aléatoirement . Cette modification transforme le modèle, initialement chargé de la classification de son vocabulaire, en un modèle produisant simplement un nombre correspondant au score de chaque invite et réponse. Ce modèle est entraîné sur les données de comparaison des préférences humaines collectées précédemment à partir du modèle supervisé. Plus précisément, il est entraîné à minimiser la fonction de perte d'entropie croisée suivante :
où représente le nombre de réponses classées par les étiqueteurs, la sortie du modèle de récompense pour la réponse rapide et la réponse complète , la réponse complète préférée par rapport à , désigne la fonction sigmoïde et désigne l' espérance mathématique . On peut considérer cela comme une forme de régression logistique , où le modèle prédit la probabilité qu'une réponse soit préférée à .
Cette fonction de perte mesure essentiellement la différence entre les prédictions du modèle de récompense et les décisions prises par les humains. L'objectif est de rapprocher au maximum les prédictions du modèle des préférences humaines en minimisant cette différence. Dans le cas de comparaisons par paires uniquement, le facteur est donc de . En général, toutes les comparaisons de chaque invite sont utilisées pour l'entraînement comme un seul lot .
Après l'entraînement, les sorties du modèle sont normalisées de sorte que les complétions de référence aient un score moyen de 0. C'est-à-dire, pour chaque paire requête et référence en calculant la récompense moyenne sur l'ensemble de données d'entraînement et en la définissant comme biais dans la tête de récompense.
Politique
Optimisation de la politique proximale
Mélange des gradients de pré-entraînement
Un troisième terme est généralement ajouté à la fonction objectif pour éviter l'oubli catastrophique du modèle. Par exemple, si le modèle est uniquement entraîné au service client, il risque d'oublier des connaissances générales en géographie. Pour prévenir ce problème, le processus RLHF intègre l'objectif initial de modélisation du langage. Autrement dit, des textes aléatoires sont extraits de l'ensemble de données de pré-entraînement initial , et le modèle est entraîné à maximiser la log-vraisemblance du texte . La fonction objectif finale s'écrit alors :
où contrôle l'intensité de ce terme de préentraînement. Cette fonction objectif combinée est appelée PPO-ptx, où « ptx » signifie « Mixage des gradients de préentraînement ». Elle a été utilisée pour la première fois dans l'article InstructGPT.
Au total, cette fonction objectif définit la méthode d'ajustement de la politique RL, combinant l'objectif de s'aligner sur les retours humains et de maintenir la compréhension du langage d'origine du modèle.
En l'écrivant de manière totalement explicite, la fonction objectif PPO-ptx est :
Limites
L’ apprentissage par renforcement par la recherche (RLHF) présente des difficultés liées à la collecte de retours humains, à l’apprentissage d’un modèle de récompense et à l’optimisation de la politique. Comparée à la collecte de données pour des techniques telles que l’apprentissage non supervisé ou auto-supervisé , la collecte de données pour le RLHF est moins facilement extensible et plus coûteuse. Sa qualité et sa cohérence peuvent varier en fonction de la tâche, de l’interface, ainsi que des préférences et des biais des utilisateurs.
L'efficacité de l'apprentissage par renforcement à long terme (RLHF) dépend de la qualité du retour d'information humain. Par exemple, le modèle peut devenir biaisé , favorisant certains groupes au détriment d'autres, si le retour d'information manque d'impartialité, est incohérent ou erroné. Il existe un risque de surapprentissage , où le modèle mémorise des exemples de retour d'information spécifiques au lieu d'apprendre à généraliser . Par exemple, un retour d'information provenant principalement d'un groupe démographique spécifique pourrait amener le modèle à apprendre des particularités ou du bruit, en plus de l'alignement souhaité. Un alignement excessif sur le retour d'information spécifique reçu (c'est-à-dire sur le biais qu'il contient) peut conduire à des performances sous-optimales du modèle dans de nouveaux contextes ou lorsqu'il est utilisé par différents groupes. Une fonction de récompense unique ne peut pas toujours représenter les opinions de divers groupes de personnes. Même avec un échantillon représentatif, des points de vue et des préférences contradictoires peuvent amener le modèle de récompense à privilégier l'opinion de la majorité, ce qui peut désavantager les groupes sous-représentés.
Dans certains cas, comme cela peut se produire avec l'apprentissage par renforcement classique , le modèle risque d'apprendre à manipuler le processus de rétroaction ou à contourner le système pour obtenir des récompenses plus importantes plutôt que d'améliorer réellement ses performances. Dans le cas de l'apprentissage par renforcement à haute fréquence (RLHF), un modèle peut apprendre à exploiter le fait qu'il est récompensé pour ce qui est évalué positivement et pas nécessairement pour ce qui est réellement bon, ce qui peut l'amener à apprendre à persuader et à manipuler. Par exemple, les modèles pourraient apprendre qu'une confiance apparente, même inexacte, rapporte des récompenses plus élevées. Un tel comportement, s'il n'est pas contrôlé, est non seulement encouragé, mais peut également entraîner d'importants problèmes de déploiement en raison du potentiel du modèle à induire en erreur. Des études ont montré que les humains ne sont pas compétents pour identifier les erreurs dans les sorties des modèles linguistiques logiques (LLM) lors de tâches complexes ; par conséquent, les modèles apprenant à générer un texte semblant confiant mais incorrect peuvent entraîner des problèmes importants lors de leur déploiement.
Alternatives
Apprentissage par renforcement à partir des retours d'IA
À l’instar de RLHF, l’apprentissage par renforcement à partir du retour d’information de l’IA (RLAIF) repose sur l’entraînement d’un modèle de préférences, à la différence que le retour d’information est généré automatiquement. Cette approche est notamment utilisée dans l’IA constitutionnelle d’ Anthropic , où le retour d’information de l’IA est basé sur la conformité aux principes d’une constitution.
Algorithmes d'alignement direct
Les algorithmes d'alignement direct (DAA) ont été proposés comme une nouvelle classe d'algorithmes qui cherchent à optimiser directement les grands modèles de langage (LLM) sur des données de retour d'information humain de manière supervisée au lieu des méthodes traditionnelles de gradient de politique.
Ces algorithmes visent à aligner les modèles sur l'intention humaine de manière plus transparente en supprimant l'étape intermédiaire d'entraînement d'un modèle de récompense distinct. Au lieu de prédire d'abord les préférences humaines puis d'optimiser en fonction de ces prédictions, les méthodes d'alignement direct entraînent les modèles de bout en bout sur des résultats étiquetés ou validés par des humains. Cela réduit les risques de désalignement potentiels liés à des objectifs indirects ou à la manipulation des récompenses.
En optimisant directement le comportement préféré des humains, ces approches permettent souvent un alignement plus étroit avec les valeurs humaines, une meilleure interprétabilité et des chaînes de formation plus simples par rapport à RLHF.
Optimisation directe des préférences
L'optimisation directe des préférences (DPO) est une technique d'apprentissage des préférences humaines. À l'instar de l'apprentissage par renforcement hyperbolique (RLHF), elle a été appliquée pour aligner des modèles de langage pré-entraînés de grande taille à l'aide de données de préférences générées par des utilisateurs. Contrairement au RLHF, qui entraîne d'abord un modèle intermédiaire distinct pour comprendre les résultats escomptés, puis enseigne au modèle principal comment les atteindre, la DPO simplifie le processus en ajustant directement le modèle principal en fonction des préférences des utilisateurs. Elle utilise un changement de variables pour définir la « perte de préférence » directement en fonction de la politique et utilise cette perte pour affiner le modèle, l'aidant ainsi à comprendre et à hiérarchiser les préférences humaines sans étape supplémentaire. En résumé, cette approche influence directement les décisions du modèle en fonction des retours d'information humains, positifs ou négatifs.
Pour rappel, le pipeline de RLHF est le suivant :
- Nous commençons par collecter un ensemble de données sur les préférences humaines .
- Nous ajustons ensuite un modèle de récompense aux données, par estimation du maximum de vraisemblance à l'aide du modèle de Plackett-Luce.
- Nous entraînons finalement une politique optimale qui maximise la fonction objectif :
Cependant, au lieu de passer par l'étape intermédiaire du modèle de récompense, DPO optimise directement la politique finale.
Tout d'abord, il faut résoudre directement le problème de la politique optimale, ce qui peut être fait à l'aide des multiplicateurs de Lagrange , comme c'est généralement le cas en mécanique statistique :
où se trouve la fonction de partition ? Malheureusement, cela n’est pas faisable, car cela nécessite de sommer sur toutes les réponses possibles :
Ensuite, inversez cette relation pour exprimer implicitement la récompense en termes de politique optimale :
Enfin, en réinjectant cette expression dans l'estimateur du maximum de vraisemblance, on obtient
Généralement, le DPO est utilisé pour modéliser les préférences humaines dans les comparaisons par paires, de sorte que . Dans ce cas, nous avons
L'algorithme DPO élimine le besoin d'un modèle de récompense ou d'une boucle d'apprentissage par renforcement distincts, traitant l'alignement comme un problème d'apprentissage supervisé sur des données de préférence. Plus simple à mettre en œuvre et à entraîner que l'algorithme RLHF, il a démontré produire des résultats comparables, voire supérieurs. Cependant, il a également été démontré que RLHF surpasse DPO sur certains jeux de données, notamment sur des benchmarks visant à mesurer la véracité. Par conséquent, le choix de la méthode peut varier en fonction des caractéristiques des données de préférence humaine et de la nature de la tâche.
Optimisation des préférences d'identité
L'optimisation des préférences d'identité (IPO) est une modification de l'objectif DPO original qui introduit un terme de régularisation pour réduire le risque de surapprentissage même lorsque les données de préférence sont bruitées.
Pour atteindre cet objectif, l'IPO minimise la fonction de perte quadratique où .
L'IPO permet de contrôler l'écart entre les rapports de vraisemblance logarithmiques du modèle de politique et du modèle de référence en régularisant systématiquement la solution par rapport à ce dernier. Elle permet un apprentissage direct à partir des préférences, sans modélisation des récompenses et sans recourir à l' hypothèse de Bradley-Terry qui suppose que les préférences par paires peuvent être remplacées par des récompenses ponctuelles.
Optimisation de Kahneman-Tversky
L'optimisation de Kahneman-Tversky (KTO) est un autre algorithme d'alignement direct qui s'appuie sur la théorie des perspectives pour modéliser l'incertitude dans les décisions humaines. Contrairement à l'optimisation par choix discret (DPO), la KTO ne requiert qu'un signal de rétroaction binaire (souhaitable ou indésirable) au lieu de paires de préférences explicites.
La fonction de valeur est définie par morceaux selon qu'elle est souhaitable ( ) ou indésirable ( ) :
Ici, ce paramètre contrôle le degré d'aversion au risque de la fonction de valeur (plus il est élevé , plus la saturation de la fonction logistique est rapide ) et sert de référence à la divergence de Kullback-Leibler. Étant donné que de nombreux processus de rétroaction réels produisent plus facilement des données binaires (« j'aime/je n'aime pas ») que des comparaisons par paires, KTO est conçu pour optimiser l'utilisation des données et refléter plus directement l'aversion aux pertes en utilisant une notion simple de « bon » ou « mauvais » au niveau de l'exemple.