- Apprentissage supervisé
- Apprentissage non supervisé
- Apprentissage semi-supervisé
- Apprentissage auto-supervisé
- Apprentissage par renforcement
- Méta-apprentissage
- apprentissage en ligne
- Apprentissage par lots
- Apprentissage du programme
- Apprentissage basé sur des règles
- IA neuro-symbolique
- Ingénierie neuromorphique
- apprentissage automatique quantique
- Classification
- Modélisation générative
- Régression
- Clustering
- Réduction de dimensionnalité
- Estimation de la densité
- Détection d'anomalies
- Nettoyage des données
- AutoML
- Règles de l'association
- Analyse sémantique
- Prédiction structurée
- Ingénierie des fonctionnalités
- Apprentissage des caractéristiques
- Apprendre à classer
- induction grammaticale
- Apprentissage ontologique
- apprentissage multimodal
- pornographie deepfake
- Polémique autour de la génération d'images Google Gemini
- C'est la période la plus terrible de l'année
- Suspension des expériences géantes sur l'IA
- Élimination de Sam Altman d'OpenAI
- Déclaration sur les risques liés à l'IA
- Tay (chatbot)
- Théâtre d'opéra Spatial
- Scandale de plagiat des NFT de Voiceverse
Les statistiques et les méthodes d'optimisation mathématique constituent les fondements de l'apprentissage automatique. L'exploration de données est un domaine d'étude connexe, axé sur l'analyse exploratoire des données (AED) par le biais de l'apprentissage non supervisé . {{rp|vii}}"}},"i":0}}] [ 3 ]
D'un point de vue théorique, l'apprentissage probablement approximativement correct fournit un cadre mathématique et statistique pour décrire l'apprentissage automatique. La plupart des algorithmes d'apprentissage automatique et d'apprentissage profond traditionnels peuvent être décrits comme une minimisation empirique du risque dans ce cadre.
Arthur Samuel , employé d’IBM et pionnier dans le domaine des jeux vidéo et de l’intelligence artificielle . Le synonyme « ordinateurs auto-apprenants » était également utilisé à cette époque.Le premier programme d'apprentissage automatique a été introduit dans les années 1950, lorsque Samuel a inventé un programme informatique qui calculait les chances de victoire aux dames pour chaque camp. Cependant, l'histoire de l'apprentissage automatique s'appuie sur des décennies d'efforts consacrés à l'étude des processus cognitifs humains. En 1949, le psychologue canadien Donald Hebb a publié l'ouvrage « The Organization of Behavior » , dans lequel il présentait une structure neuronale théorique formée par certaines interactions entre les cellules nerveuses . La théorie hebbienne de l'interaction neuronale a jeté les bases du fonctionnement de nombreux algorithmes d'apprentissage automatique, où des neurones artificiels interconnectés modifient la force de leurs connexions en fonction des données. D'autres chercheurs ayant étudié les systèmes cognitifs humains ont également contribué aux technologies modernes d'apprentissage automatique, notamment Walter Pitts et Warren McCulloch , qui ont proposé le premier modèle mathématique de réseaux neuronaux incluant des algorithmes qui reproduisent les processus de pensée humains. la société Raytheon développa Cybertron, une « machine apprenante » expérimentale dotée d'une mémoire à bande perforée . Ce dispositif analysait les signaux sonar , les électrocardiogrammes et les schémas vocaux grâce à un apprentissage par renforcement rudimentaire . Un opérateur humain l'entraînait de manière répétée à reconnaître des formes et un bouton « erreur » lui permettait de corriger ses décisions incorrectes. L'ouvrage de référence sur la recherche en apprentissage automatique dans les années 1960 est « Learning Machines » de Nils Nilsson , qui traite principalement de l'apprentissage automatique pour la classification de formes . L'intérêt pour la reconnaissance de formes se poursuivit dans les années 1970, comme le décrivent Duda et Hart en 1973. En 1981, un rapport présenta des stratégies d'apprentissage permettant à un réseau de neurones artificiels d'apprendre à reconnaître 40 caractères (26 lettres, 10 chiffres et 4 symboles spéciaux) sur un terminal informatique.
Tom M. Mitchell a proposé une définition plus formelle et largement citée des algorithmes étudiés dans le domaine de l'apprentissage automatique : « On dit qu'un programme informatique apprend de l'expérience E relativement à une classe de tâches T et à une mesure de performance P si sa performance aux tâches de T , mesurée par P , s'améliore avec l'expérience E. » Cette définition des tâches concernées par l'apprentissage automatique est fondamentalement opérationnelle plutôt que cognitive. Elle fait suite à la proposition d' Alan Turing dans son article « Computing Machinery and Intelligence », où la question « Les machines peuvent-elles penser ? » est remplacée par celle de savoir si les machines peuvent imiter de manière convaincante un humain dans ses réponses à des questions posées par des humains.
En 2014, Ian Goodfellow et d'autres chercheurs ont introduit les réseaux antagonistes génératifs (GAN), capables de produire des données synthétiques réalistes. En 2016, AlphaGo a vaincu les meilleurs joueurs humains de go grâce à des techniques d'apprentissage par renforcement .
Relations avec d'autres domaines
Intelligence artificielle
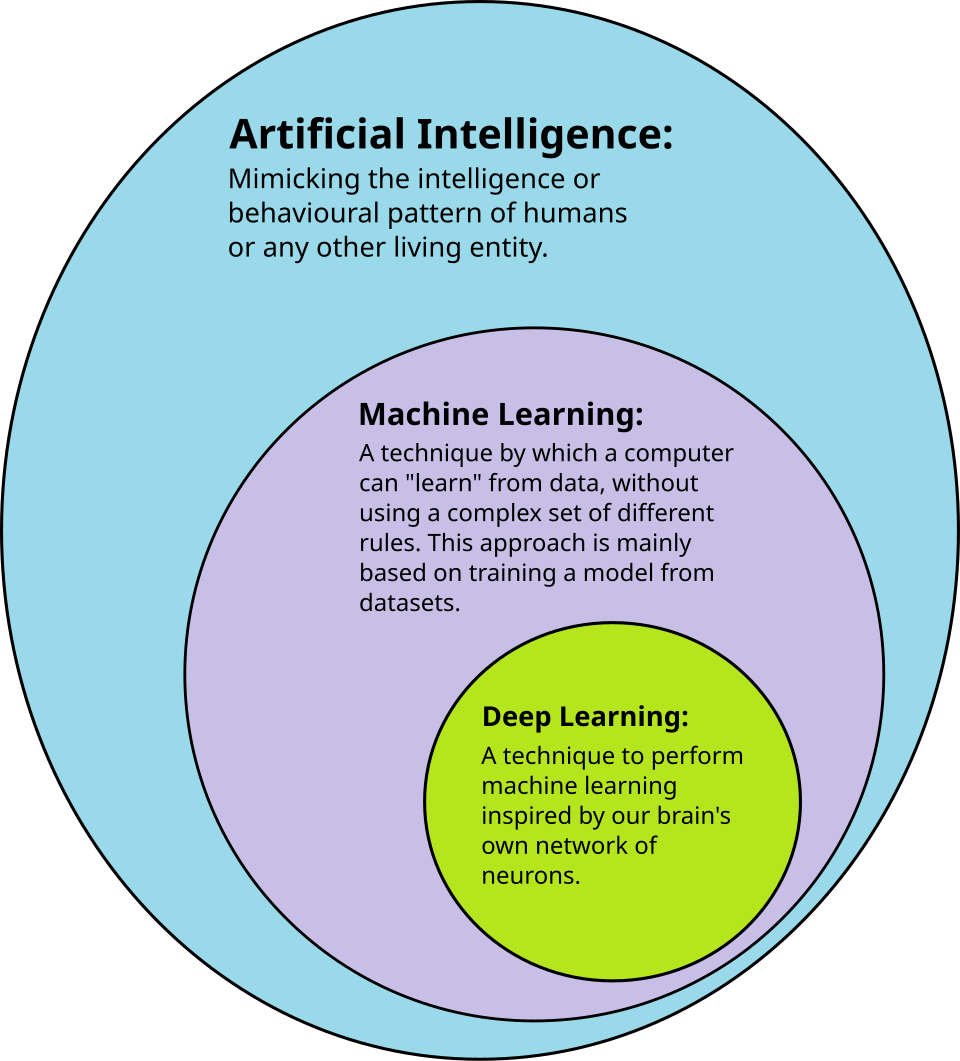
En tant que domaine scientifique, l'apprentissage automatique est né de la quête de l'intelligence artificielle (IA). Aux débuts de l'IA comme discipline académique , certains chercheurs s'intéressaient à la capacité des machines à apprendre à partir de données. Ils ont tenté d'aborder ce problème avec diverses méthodes symboliques, ainsi qu'avec ce que l'on appelait alors les « réseaux de neurones » ; il s'agissait principalement de perceptrons et d'autres modèles qui se sont révélés par la suite être des réinventions des modèles linéaires généralisés des statistiques. Le raisonnement probabiliste a également été employé, notamment dans le diagnostic médical automatisé .
Cependant, l'accent croissant mis sur l' approche logique et fondée sur la connaissance a provoqué une rupture entre l'IA et l'apprentissage automatique. Les systèmes probabilistes étaient confrontés à des problèmes théoriques et pratiques d'acquisition et de représentation des données. Dès 1980, les systèmes experts dominaient l'IA et les statistiques étaient délaissées. Les travaux sur l'apprentissage symbolique/fondé sur la connaissance se sont poursuivis au sein de l'IA, aboutissant à la programmation logique inductive (PLI), mais la recherche plus statistique se situait désormais en dehors du champ de l'IA proprement dit, dans les domaines de la reconnaissance de formes et de la recherche d'informations . La recherche sur les réseaux de neurones a été abandonnée par l'IA et l'informatique à peu près à la même époque. Ce sous-domaine, appelé « connexionnisme », a été poursuivi par des chercheurs d'autres disciplines, notamment John Hopfield , David Rumelhart et Geoffrey Hinton . Leur principal succès est survenu au milieu des années 1980 avec la réinvention de la rétropropagation .
L’apprentissage automatique (ML), réorganisé et reconnu comme un domaine à part entière, a commencé à se développer dans les années 1990. Ce domaine a modifié son objectif, passant de la réalisation de l’intelligence artificielle à la résolution de problèmes pratiques concrets. Il s’est éloigné des approches symboliques héritées de l’IA pour se tourner vers des méthodes et des modèles empruntés aux statistiques, à la logique floue et à la théorie des probabilités .
Compression des données
Une autre perspective consiste à montrer que les algorithmes de compression transforment implicitement les chaînes de caractères en vecteurs d'espace de caractéristiques implicites , et que les mesures de similarité basées sur la compression calculent la similarité au sein de ces espaces de caractéristiques. Pour chaque compresseur C(.), nous définissons un espace vectoriel associé ℵ, tel que C(.) transforme une chaîne d'entrée x en un vecteur dont la norme est ||~x||. Faute de place, un examen exhaustif des espaces de caractéristiques sous-jacents à tous les algorithmes de compression est impossible ; par conséquent, l'étude des vecteurs de caractéristiques se concentre sur trois méthodes de compression sans perte représentatives : LZW, LZ77 et PPM.
Selon la théorie AIXI , dont le lien est expliqué plus directement dans le prix Hutter , la meilleure compression possible de x correspond au logiciel le plus léger possible qui génère x. Par exemple, dans ce modèle, la taille compressée d'un fichier zip inclut à la fois le fichier zip et le logiciel de décompression, puisqu'il est impossible de le décompresser sans les deux ; or, une forme combinée encore plus petite peut exister.
Parmi les logiciels de compression audio/vidéo utilisant l'IA, on peut citer NVIDIA Maxine et AIVC. Parmi les logiciels capables d'effectuer une compression d'images utilisant l'IA, on peut citer OpenCV , TensorFlow , la boîte à outils de traitement d'images (IPT) de MATLAB et la compression d'images générative haute fidélité.
En apprentissage automatique non supervisé , le clustering k-means peut être utilisé pour compresser les données en regroupant les points de données similaires en clusters. Cette technique simplifie le traitement des grands ensembles de données dépourvus d'étiquettes prédéfinies et est largement utilisée dans des domaines tels que la compression d'images .
La compression de données vise à réduire la taille des fichiers, améliorant ainsi l'efficacité du stockage et accélérant la transmission des données. L'algorithme de clustering K-means, un algorithme d'apprentissage automatique non supervisé, est utilisé pour partitionner un ensemble de données en un nombre spécifié de clusters, k, chacun représenté par le centroïde de ses points. Ce processus condense les ensembles de données volumineux en un ensemble plus compact de points représentatifs. Particulièrement avantageux en traitement d'images et de signaux , le clustering K-means contribue à la réduction des données en remplaçant des groupes de points par leurs centroïdes, préservant ainsi l'information essentielle des données originales tout en réduisant considérablement l'espace de stockage requis.
Les grands modèles de langage (LLM) sont également des compresseurs de données sans perte efficaces sur certains ensembles de données, comme l'ont démontré les recherches de DeepMind avec le modèle Chinchilla 70B. Développé par DeepMind, Chinchilla 70B a compressé efficacement les données, surpassant les méthodes conventionnelles telles que le format PNG pour les images et le format FLAC pour l'audio. Il a permis de compresser les données d'image et audio à respectivement 43,4 % et 16,4 % de leur taille d'origine. Cependant, il est à noter que l'ensemble de données utilisé pour les tests recoupe l'ensemble de données d'entraînement du LLM, ce qui laisse penser que le modèle Chinchilla 70B n'est efficace que sur les données sur lesquelles il a déjà été entraîné.
Exploration de données
L'apprentissage automatique et l'exploration de données utilisent souvent les mêmes méthodes et se recoupent largement. Cependant, tandis que l'apprentissage automatique se concentre sur la prédiction à partir de propriétés connues , apprises grâce aux données d'entraînement, l'exploration de données vise la découverte de propriétés jusqu'alors inconnues dans les données (il s'agit de l'étape d'analyse de la découverte de connaissances dans les bases de données). L'exploration de données utilise de nombreuses méthodes d'apprentissage automatique, mais avec des objectifs différents. Réciproquement, l'apprentissage automatique emploie également des méthodes d'exploration de données, soit comme « apprentissage non supervisé », soit comme étape de prétraitement pour améliorer la précision du modèle. Une grande partie de la confusion entre ces deux communautés de recherche provient des hypothèses fondamentales sur lesquelles elles s'appuient : en apprentissage automatique, la performance est généralement évaluée par rapport à la capacité à reproduire des connaissances connues , tandis qu'en découverte de connaissances et exploration de données (KDD), la tâche principale est la découverte de connaissances jusqu'alors inconnues . Évaluée par rapport aux connaissances connues, une méthode non supervisée sera facilement surpassée par d'autres méthodes supervisées, tandis que dans une tâche typique de KDD, les méthodes supervisées ne peuvent être utilisées en raison de l'indisponibilité de données d'entraînement.l’optimisation : de nombreux problèmes d’apprentissage sont formulés comme la minimisation d’une fonction de perte sur un ensemble d’exemples d’entraînement. Les fonctions de perte expriment l’écart entre les prédictions du modèle en cours d’entraînement et les instances réelles du problème (par exemple, en classification, on souhaite attribuer une étiquette aux instances, et les modèles sont entraînés à prédire correctement les étiquettes pré-attribuées d’un ensemble d’exemples).
Généralisation
La caractérisation de la généralisation des différents algorithmes d'apprentissage est un sujet de recherche actuel très actif, notamment pour les algorithmes d'apprentissage profond .les statistiques sont des domaines étroitement liés en termes de méthodes, mais distincts dans leur objectif principal : les statistiques tirent des inférences sur la population à partir d'un échantillon , tandis que l'apprentissage automatique trouve des modèles prédictifs généralisables.
Les analyses statistiques classiques exigent la sélection a priori d'un modèle adapté aux données étudiées. De plus, seules les variables significatives ou théoriquement pertinentes, d'après l'expérience acquise, sont incluses dans l'analyse. À l'inverse, l'apprentissage automatique ne repose pas sur un modèle pré-structuré ; ce sont les données qui façonnent le modèle en détectant des schémas sous-jacents. Plus le nombre de variables (entrées) utilisées pour entraîner le modèle est élevé, plus le modèle final sera précis.
Leo Breiman a distingué deux paradigmes de modélisation statistique : le modèle de données et le modèle algorithmique, où « modèle algorithmique » signifie plus ou moins les algorithmes d’apprentissage automatique comme Random forest .réseaux neuronaux profonds . La physique statistique trouve ainsi des applications dans le domaine du diagnostic médical . informatique théorique appelée théorie de l'apprentissage computationnel . Un cadre théorique majeur est le modèle d'apprentissage probablement approximativement correct . Étant donné la taille finie des ensembles d'entraînement et l'incertitude quant aux résultats futurs, la théorie de l'apprentissage ne fournit généralement pas de garanties quant aux performances des algorithmes. On utilise plutôt fréquemment des bornes probabilistes sur ces performances. La décomposition biais-variance est une méthode permettant de quantifier l'erreur de généralisation .surapprentissage et à une généralisation moins performante.
Outre les limites de performance, les théoriciens de l'apprentissage étudient la complexité temporelle et la faisabilité de l'apprentissage. En théorie de l'apprentissage computationnel, un calcul est considéré comme faisable s'il peut être effectué en temps polynomial . Il existe deux types de résultats concernant la complexité temporelle : les résultats positifs indiquent qu'une certaine classe de fonctions peut être apprise en temps polynomial, tandis que les résultats négatifs indiquent que certaines classes ne peuvent pas être apprises en temps polynomial.
Les approches d'apprentissage automatique sont traditionnellement divisées en trois grandes catégories, qui correspondent à des paradigmes d'apprentissage, selon la nature du « signal » ou du « retour d'information » disponible pour le système d'apprentissage :
- Apprentissage supervisé : L'ordinateur reçoit des exemples d'entrées et leurs sorties souhaitées, fournis par un « enseignant », et le but est d'apprendre une règle générale qui associe les entrées aux sorties.
- Apprentissage non supervisé : aucune étiquette n’est fournie à l’algorithme d’apprentissage, qui doit trouver lui-même la structure de ses données d’entrée. L’apprentissage non supervisé peut être une fin en soi (découvrir des modèles cachés dans les données) ou un moyen d’atteindre un objectif ( apprentissage de caractéristiques ).
- Apprentissage par renforcement : Un programme informatique interagit avec un environnement dynamique dans lequel il doit atteindre un objectif précis (comme conduire un véhicule ou jouer à un jeu contre un adversaire). Au fur et à mesure qu’il évolue dans son environnement, le programme reçoit des récompenses en guise de retour d’information, qu’il tente de maximiser, ce qui lui permet d’apprendre de l’expérience.
Bien que chaque algorithme présente des avantages et des limitations, aucun algorithme ne fonctionne pour tous les problèmes.
Apprentissage supervisé
Les algorithmes d'apprentissage supervisé construisent un modèle mathématique d'un ensemble de données contenant à la fois les entrées et les sorties souhaitées. Ces données, appelées données d'entraînement , sont constituées d'un ensemble d'exemples d'entraînement. Chaque exemple d'entraînement possède une ou plusieurs entrées et la sortie souhaitée, également appelée signal de supervision. Dans le modèle mathématique, chaque exemple d'entraînement est représenté par un tableau ou un vecteur, parfois appelé vecteur de caractéristiques , et les données d'entraînement sont représentées par une matrice . Par l'optimisation itérative d'une fonction objectif , les algorithmes d'apprentissage supervisé apprennent une fonction permettant de prédire la sortie associée à de nouvelles entrées. Une fonction optimale permet à l'algorithme de déterminer correctement la sortie pour des entrées qui ne faisaient pas partie des données d'entraînement. Un algorithme qui améliore la précision de ses sorties ou de ses prédictions au fil du temps est dit avoir appris à effectuer cette tâche.
Les algorithmes d'apprentissage supervisé comprennent notamment l'apprentissage actif , la classification et la régression . Les algorithmes de classification sont utilisés lorsque les sorties sont limitées à un ensemble restreint de valeurs, tandis que les algorithmes de régression sont utilisés lorsque les sorties peuvent prendre n'importe quelle valeur numérique dans un intervalle donné. Par exemple, dans un algorithme de classification qui filtre les courriels, l'entrée est un courriel entrant et la sortie est le dossier dans lequel le classer. En revanche, la régression est utilisée pour des tâches telles que la prédiction de la taille d'une personne en fonction de facteurs comme l'âge et la génétique, ou la prévision des températures futures à partir de données historiques.
L'apprentissage par similarité est un domaine de l'apprentissage automatique supervisé étroitement lié à la régression et à la classification. Son objectif est d'apprendre à partir d'exemples grâce à une fonction de similarité qui mesure le degré de ressemblance ou de relation entre deux objets. Il trouve des applications dans le classement , les systèmes de recommandation , le suivi d'identité visuelle, la vérification faciale et la vérification vocale.
Apprentissage non supervisé
L'analyse de clusters consiste à répartir un ensemble d'observations en sous-ensembles (appelés clusters ) de sorte que les observations appartenant à un même cluster soient similaires selon un ou plusieurs critères prédéfinis, tandis que les observations provenant de clusters différents sont dissemblables. Les différentes techniques de clustering reposent sur différentes hypothèses concernant la structure des données, souvent définie par une métrique de similarité et évaluée, par exemple, par la compacité interne (la similarité entre les membres d'un même cluster) et la séparation (la différence entre les clusters). D'autres méthodes sont basées sur l'estimation de la densité et de la connectivité du graphe .
Un type particulier d'apprentissage non supervisé appelé apprentissage auto-supervisé consiste à entraîner un modèle en générant le signal de supervision à partir des données elles-mêmes.
Réduction de dimensionnalité
La réduction de dimensionnalité est un processus qui consiste à réduire le nombre de variables aléatoires considérées en obtenant un ensemble de variables principales . Autrement dit, il s'agit de réduire la dimension de l' ensemble de caractéristiques , également appelée « nombre de caractéristiques ». La plupart des techniques de réduction de dimensionnalité peuvent être considérées comme des méthodes d'élimination ou d'extraction de caractéristiques . L'une des méthodes les plus courantes est l'analyse en composantes principales (ACP). L'ACP consiste à transformer des données de grande dimension (par exemple, 3D) en un espace de plus petite dimension (par exemple, 2D). L' hypothèse de variété propose que les ensembles de données de grande dimension se situent sur des variétés de faible dimension . De nombreuses techniques de réduction de dimensionnalité reposent sur cette hypothèse, donnant lieu aux domaines de l'apprentissage de variétés et de la régularisation de variétés .
Apprentissage semi-supervisé
Dans l'apprentissage faiblement supervisé , les étiquettes d'entraînement sont bruitées, limitées ou imprécises ; cependant, ces étiquettes sont souvent moins coûteuses à obtenir, ce qui donne des ensembles d'entraînement effectifs plus grands.
Apprentissage par renforcement
L'apprentissage par renforcement est un domaine de l'apprentissage automatique qui étudie comment les agents logiciels doivent agir dans un environnement pour maximiser une certaine notion de récompense cumulative. De par sa généralité, ce domaine est étudié dans de nombreuses autres disciplines, telles que la théorie des jeux , la théorie du contrôle , la recherche opérationnelle , la théorie de l'information , l'optimisation par simulation , les systèmes multi-agents , l'intelligence collective , les statistiques et les algorithmes génétiques . En apprentissage par renforcement, l'environnement est généralement représenté par un processus de décision markovien (MDP). De nombreux algorithmes d'apprentissage par renforcement utilisent des techniques de programmation dynamique . Ces algorithmes ne supposent pas la connaissance d'un modèle mathématique exact du MDP et sont utilisés lorsque les modèles exacts sont irréalisables. Ils sont utilisés dans les véhicules autonomes ou pour apprendre à jouer à un jeu contre un adversaire humain.
Autres types
D’autres approches ont été développées qui ne correspondent pas parfaitement à cette catégorisation tripartite, et il arrive que plusieurs d’entre elles soient utilisées par un même système d’apprentissage automatique. Par exemple, la modélisation thématique et le méta-apprentissage .
Auto-apprentissage
L'auto-apprentissage, en tant que paradigme d'apprentissage automatique, a été introduit en 1982 avec un réseau de neurones capable d'auto-apprentissage, appelé réseau adaptatif à barres croisées (CAA). Il apporte une solution au problème de l'apprentissage sans récompense externe, en introduisant l'émotion comme récompense interne. L'émotion est utilisée pour évaluer l'état d'un agent auto-apprenant. L'algorithme d'auto-apprentissage CAA calcule, de manière à former des barres croisées, à la fois les décisions concernant les actions et les émotions (sentiments) liées aux conséquences des situations. Le système est piloté par l'interaction entre cognition et émotion. L'algorithme d'auto-apprentissage met à jour une matrice de mémoire W = ||w(a,s)|| de sorte qu'à chaque itération, il exécute la routine d'apprentissage automatique suivante :
- dans la situation s agir a
- subir une conséquence situation s L'analyse en composantes principales et l'analyse de clusters en sont des exemples classiques . Les algorithmes d'apprentissage de caractéristiques, également appelés algorithmes d'apprentissage de représentations, cherchent souvent à préserver l'information contenue dans leurs données d'entrée tout en la transformant pour la rendre utile, généralement en tant qu'étape de prétraitement avant la classification ou les prédictions. Cette technique permet de reconstruire les données d'entrée à partir de la distribution génératrice de données inconnue, sans pour autant être nécessairement fidèle aux configurations improbables sous cette distribution. Elle remplace l'ingénierie manuelle des caractéristiques et permet à une machine d'apprendre les caractéristiques et de les utiliser pour accomplir une tâche spécifique.
L'apprentissage de caractéristiques peut être supervisé ou non supervisé. Dans l'apprentissage supervisé, les caractéristiques sont apprises à partir de données d'entrée étiquetées. On peut citer comme exemples les réseaux de neurones artificiels , les perceptrons multicouches et l'apprentissage supervisé de dictionnaires . Dans l'apprentissage non supervisé, les caractéristiques sont apprises à partir de données d'entrée non étiquetées. On peut citer comme exemples l'apprentissage de dictionnaires, l'analyse en composantes indépendantes , les auto-encodeurs , la factorisation matricielle et diverses techniques de clustering .
Les algorithmes d'apprentissage de variétés tentent d'y parvenir sous la contrainte que la représentation apprise soit de faible dimension. Les algorithmes de codage parcimonieux tentent d'y parvenir sous la contrainte que la représentation apprise soit parcimonieuse, c'est-à-dire que le modèle mathématique comporte de nombreux zéros. Les algorithmes d'apprentissage de sous-espaces multilinéaires visent à apprendre des représentations de faible dimension directement à partir de représentations tensorielles pour des données multidimensionnelles, sans les remodeler en vecteurs de dimension supérieure. Les algorithmes d'apprentissage profond découvrent plusieurs niveaux de représentation, ou une hiérarchie de caractéristiques, les caractéristiques de niveau supérieur, plus abstraites, étant définies en fonction des caractéristiques de niveau inférieur (ou les générant). Il a été avancé qu'une machine intelligente apprend une représentation qui démêle les facteurs de variation sous-jacents expliquant les données observées.
L'apprentissage de caractéristiques se justifie par le fait que les tâches d'apprentissage automatique, telles que la classification, requièrent souvent des données d'entrée faciles à traiter mathématiquement et informatiquement. Cependant, les données réelles, comme les images, les vidéos et les données sensorielles, n'ont pas encore fait l'objet de tentatives de définition algorithmique de caractéristiques spécifiques. Une alternative consiste à découvrir ces caractéristiques ou représentations par l'examen, sans recourir à des algorithmes explicites.
Apprentissage de dictionnaires clairsemés
Détection d'anomalies
Dans le contexte de la détection des abus et des intrusions réseau, les objets d'intérêt ne sont souvent pas rares, mais plutôt des périodes d'inactivité inattendues. Ce schéma ne correspond pas à la définition statistique courante d'une valeur aberrante comme objet rare. De nombreuses méthodes de détection de valeurs aberrantes (notamment les algorithmes non supervisés) échouent sur de telles données si elles ne sont pas correctement agrégées. En revanche, un algorithme d'analyse de clusters peut permettre de détecter les micro-clusters formés par ces schémas.
Il existe trois grandes catégories de techniques de détection d'anomalies. Les techniques non supervisées détectent les anomalies dans un ensemble de données de test non étiqueté, en supposant que la majorité des instances sont normales, et en recherchant les instances qui semblent les moins représentatives du reste des données. Les techniques supervisées nécessitent un ensemble de données étiqueté « normal » et « anormal » et impliquent l'entraînement d'un classificateur (la principale différence avec de nombreux autres problèmes de classification statistique réside dans le déséquilibre inhérent à la détection des valeurs aberrantes). Les techniques semi-supervisées construisent un modèle représentant le comportement normal à partir d'un ensemble de données d'entraînement normal donné, puis testent la probabilité qu'une instance de test soit générée par ce modèle.
Apprentissage robotique
L'apprentissage robotique s'inspire d'une multitude de méthodes d'apprentissage automatique, en commençant par l'apprentissage supervisé, l'apprentissage par renforcement, et enfin le méta-apprentissage (par exemple MAML).
Règles de l'association
L'apprentissage automatique basé sur des règles est un terme général désignant toute méthode d'apprentissage automatique qui identifie, apprend ou fait évoluer des « règles » pour stocker, manipuler ou appliquer des connaissances. La caractéristique principale d'un algorithme d'apprentissage automatique basé sur des règles est l'identification et l'utilisation d'un ensemble de règles relationnelles qui représentent collectivement les connaissances acquises par le système. Ceci contraste avec d'autres algorithmes d'apprentissage automatique qui identifient généralement un modèle unique, applicable universellement à toute instance pour effectuer une prédiction. Les approches d'apprentissage automatique basées sur des règles comprennent l'apprentissage de systèmes de classification , l'apprentissage de règles d'association et les systèmes immunitaires artificiels .
S’appuyant sur le concept de règles fortes, Rakesh Agrawal , Tomasz Imieliński et Arun Swami ont introduit les règles d’association pour identifier les régularités entre les produits dans les données transactionnelles à grande échelle enregistrées par les systèmes de points de vente (PDV) des supermarchés . Par exemple, la règle identifiée dans les données de vente d’un supermarché indiquerait que si un client achète des oignons et des pommes de terre ensemble, il est probable qu’il achète également de la viande hachée. Ces informations peuvent servir de base à des décisions marketing telles que la tarification promotionnelle ou le placement des produits . Outre l’analyse du panier d’achat , les règles d’association sont aujourd’hui utilisées dans des domaines d’application comme l’exploration des données d’utilisation du Web , la détection d’intrusion , la production en continu et la bioinformatique . Contrairement à l’exploration de séquences , l’apprentissage des règles d’association ne tient généralement pas compte de l’ordre des articles, ni au sein d’une même transaction, ni entre différentes transactions.
Les systèmes de classification apprenants (LCS) sont une famille d'algorithmes d'apprentissage automatique basés sur des règles qui combinent un composant de découverte, généralement un algorithme génétique , avec un composant d'apprentissage, effectuant soit un apprentissage supervisé , soit un apprentissage par renforcement , soit un apprentissage non supervisé . Ils cherchent à identifier un ensemble de règles dépendantes du contexte qui stockent et appliquent collectivement les connaissances de manière progressive pour faire des prédictions.
La programmation logique inductive (PLI) est une approche d'apprentissage des règles qui utilise la programmation logique comme représentation uniforme des exemples d'entrée, des connaissances préalables et des hypothèses. À partir d'un encodage des connaissances préalables et d'un ensemble d'exemples représentés sous forme de base de données logique de faits, un système de PLI génère un programme logique hypothétique qui inclut tous les exemples positifs et aucun exemple négatif. La programmation inductive est un domaine connexe qui considère tout type de langage de programmation pour la représentation des hypothèses (et pas seulement la programmation logique), comme par exemple les programmes fonctionnels .
La programmation logique inductive est particulièrement utile en bioinformatique et en traitement automatique du langage naturel . Gordon Plotkin et Ehud Shapiro ont posé les fondements théoriques de l'apprentissage automatique inductif dans un cadre logique. Shapiro a développé leur première implémentation (Model Inference System) en 1981 : un programme Prolog qui inférait inductivement des programmes logiques à partir d'exemples positifs et négatifs. Le terme « inductif » se réfère ici à l'induction philosophique , qui propose une théorie pour expliquer les faits observés, par opposition à l'induction mathématique , qui vise à démontrer une propriété pour tous les éléments d'un ensemble bien ordonné.
Modèles
UNUn modèle d'apprentissage automatique est un type demodèle mathématiquequi, une fois « entraîné » sur un ensemble de données donné, peut être utilisé pour effectuer des prédictions ou des classifications sur de nouvelles données. Au cours de l'entraînement, un algorithme d'apprentissage ajuste itérativement les paramètres internes du modèle afin de minimiser les erreurs dans ses prédictions. Par extension, le terme « modèle » peut désigner différents niveaux de spécificité, allant d'une classe générale de modèles et de leurs algorithmes d'apprentissage associés à un modèle entièrement entraîné dont tous les paramètres internes sont optimisés.
Différents types de modèles ont été utilisés et étudiés pour les systèmes d'apprentissage automatique ; le choix du meilleur modèle pour une tâche est appelé sélection de modèle .
réseaux neuronaux artificiels
Les réseaux de neurones artificiels (RNA), ou systèmes connexionnistes , sont des systèmes informatiques vaguement inspirés des réseaux neuronaux biologiques qui constituent le cerveau des animaux . Ces systèmes « apprennent » à réaliser des tâches en considérant des exemples, généralement sans être programmés avec des règles spécifiques à la tâche.
Un réseau de neurones artificiels (RNA) est un modèle basé sur un ensemble d'unités ou nœuds interconnectés appelés « neurones artificiels », qui modélisent de manière simplifiée les neurones du cerveau biologique. Chaque connexion, à l'instar des synapses dans le cerveau biologique, peut transmettre une information, un « signal », d'un neurone artificiel à un autre. Un neurone artificiel qui reçoit un signal peut le traiter, puis le transmettre à d'autres neurones artificiels qui lui sont connectés. Dans les implémentations courantes de RNA, le signal à une connexion entre neurones artificiels est un nombre réel , et la sortie de chaque neurone artificiel est calculée par une fonction non linéaire de la somme de ses entrées. Les connexions entre neurones artificiels sont appelées « arêtes ». Les neurones artificiels et les arêtes possèdent généralement un poids qui s'ajuste au cours de l'apprentissage. Ce poids augmente ou diminue l'intensité du signal à une connexion. Les neurones artificiels peuvent avoir un seuil : le signal n'est transmis que si le signal agrégé dépasse ce seuil. Généralement, les neurones artificiels sont regroupés en couches. Différentes couches peuvent effectuer différents types de transformations sur leurs entrées. Les signaux circulent de la première couche (la couche d'entrée) à la dernière couche (la couche de sortie), éventuellement après avoir traversé les couches plusieurs fois.
L'objectif initial des réseaux de neurones artificiels était de résoudre des problèmes à l'instar du cerveau humain . Cependant, au fil du temps, l'attention s'est portée sur l'exécution de tâches spécifiques, entraînant des écarts par rapport au fonctionnement biologique . Les réseaux de neurones artificiels ont été utilisés dans de nombreux domaines, tels que la vision par ordinateur , la reconnaissance vocale , la traduction automatique , le filtrage des réseaux sociaux , les jeux de société et vidéo, ainsi que le diagnostic médical .
L’apprentissage profond est constitué de plusieurs couches cachées au sein d’un réseau neuronal artificiel. Cette approche tente de modéliser la façon dont le cerveau humain traite la lumière et le son pour produire la vision et l’ouïe. La vision par ordinateur et la reconnaissance vocale comptent parmi les applications réussies de l’apprentissage profond.
Arbres de décision
L'apprentissage par arbres de décision utilise un arbre de décision comme modèle prédictif pour passer des observations relatives à un élément (représentées par les branches) aux conclusions concernant sa valeur cible (représentée par les feuilles). Il s'agit d'une des approches de modélisation prédictive utilisées en statistique, en exploration de données et en apprentissage automatique. Les modèles arborescents où la variable cible peut prendre un ensemble discret de valeurs sont appelés arbres de classification ; dans ces structures arborescentes, les feuilles représentent les étiquettes de classe et les branches représentent les conjonctions de caractéristiques qui conduisent à ces étiquettes. Les arbres de décision où la variable cible peut prendre des valeurs continues (généralement des nombres réels ) sont appelés arbres de régression. En analyse décisionnelle, un arbre de décision peut être utilisé pour représenter visuellement et explicitement les décisions et le processus décisionnel . En exploration de données, un arbre de décision décrit les données, mais l'arbre de classification résultant peut servir d'entrée pour la prise de décision.
Régression par forêt aléatoire
La régression par forêt aléatoire (RFR) fait partie des modèles basés sur les arbres de décision . La RFR est une méthode d'apprentissage ensembliste qui construit plusieurs arbres de décision et moyenne leurs prédictions afin d'améliorer la précision et d'éviter le surapprentissage. Pour construire ces arbres, la RFR utilise un échantillonnage bootstrap ; chaque arbre est entraîné sur des données aléatoires de l'ensemble d'entraînement. Cette sélection aléatoire des données d'entraînement permet au modèle de réduire les biais et d'atteindre une plus grande précision. La RFR génère des arbres de décision indépendants et peut traiter des données à sortie unique ainsi que des tâches de régression à plusieurs variables explicatives. Ceci la rend compatible avec diverses applications.
Machines à vecteurs de support
Analyse de régression
L'analyse de régression englobe une grande variété de méthodes statistiques permettant d'estimer la relation entre les variables d'entrée et leurs caractéristiques associées. Sa forme la plus courante est la régression linéaire , où une droite est tracée pour ajuster au mieux les données selon un critère mathématique tel que la méthode des moindres carrés ordinaires . Cette dernière est souvent étendue par des méthodes de régularisation afin d'atténuer le surapprentissage et les biais, comme dans la régression ridge . Pour les problèmes non linéaires, les modèles de référence incluent la régression polynomiale (par exemple, utilisée pour l'ajustement de courbes de tendance dans Microsoft Excel ), la régression logistique (souvent utilisée en classification statistique ) ou encore la régression à noyau , qui introduit la non-linéarité en exploitant la technique du noyau pour projeter implicitement les variables d'entrée dans un espace de dimension supérieure.
La régression linéaire multivariée étend le concept de régression linéaire pour traiter simultanément plusieurs variables dépendantes. Cette approche estime les relations entre un ensemble de variables d'entrée et plusieurs variables de sortie en ajustant un modèle linéaire multidimensionnel . Elle est particulièrement utile lorsque les sorties sont interdépendantes ou partagent des schémas sous-jacents, comme la prédiction de plusieurs indicateurs économiques ou la reconstruction d'images , qui sont par nature multidimensionnelles.
réseaux bayésiens
Un réseau bayésien, également appelé réseau de croyances ou modèle graphique acyclique orienté, est un modèle graphique probabiliste qui représente un ensemble de variables aléatoires et leur indépendance conditionnelle par un graphe acyclique orienté (DAG). Par exemple, un réseau bayésien peut représenter les relations probabilistes entre maladies et symptômes. Connaissant des symptômes, le réseau permet de calculer les probabilités de présence de différentes maladies. Des algorithmes efficaces existent pour réaliser l'inférence et l'apprentissage. Les réseaux bayésiens qui modélisent des séquences de variables, comme des signaux vocaux ou des séquences protéiques , sont appelés réseaux bayésiens dynamiques . Les généralisations des réseaux bayésiens capables de représenter et de résoudre des problèmes de décision en situation d'incertitude sont appelées diagrammes d'influence .
processus gaussiens
Un processus gaussien est un processus stochastique dans lequel chaque ensemble fini de variables aléatoires du processus suit une distribution normale multivariée , et il repose sur une fonction de covariance prédéfinie , ou noyau, qui modélise la façon dont les paires de points sont liées entre elles en fonction de leur emplacement.
Étant donné un ensemble de points observés, ou d'exemples d'entrée-sortie, la distribution de la sortie (non observée) d'un nouveau point en fonction de ses données d'entrée peut être calculée directement en examinant les points observés et les covariances entre ces points et le nouveau point non observé.
Les processus gaussiens sont des modèles de substitution populaires dans l'optimisation bayésienne utilisés pour effectuer l'optimisation des hyperparamètres .
Algorithmes génétiques
Fonctions de croyance
Modèles basés sur des règles
Modèles de formation
En général, les modèles d'apprentissage automatique nécessitent une grande quantité de données fiables pour effectuer des prédictions précises. Lors de l'entraînement d'un modèle, les ingénieurs en apprentissage automatique doivent cibler et collecter un échantillon de données vaste et représentatif. Les données de l'ensemble d'entraînement peuvent être aussi variées qu'un corpus de texte , une collection d'images, des données de capteurs ou des données collectées auprès des utilisateurs d'un service. Le surapprentissage est un écueil à surveiller lors de l'entraînement d'un modèle d'apprentissage automatique. Les modèles entraînés à partir de données biaisées ou non évaluées peuvent produire des prédictions faussées ou indésirables. Les modèles biaisés peuvent avoir des conséquences néfastes, aggravant ainsi les impacts négatifs sur la société ou les objectifs. Un biais algorithmique peut résulter d'une préparation incomplète des données pour l'entraînement. L'éthique de l'apprentissage automatique est un domaine d'étude en plein essor et s'intègre de plus en plus au sein des équipes d'ingénierie en apprentissage automatique.
Apprentissage fédéré
Applications
L'apprentissage automatique a de nombreuses applications, notamment :
AgricultureEn 2006, Netflix, fournisseur de services de médias en ligne, a organisé le premier concours « Prix Netflix » afin de trouver un programme capable de mieux prédire les préférences des utilisateurs et d'améliorer d'au moins 10 % la précision de son algorithme de recommandation de films Cinematch. Une équipe conjointe de chercheurs d' AT&T Labs Research, en collaboration avec les équipes Big Chaos et Pragmatic Theory, a conçu un modèle d'ensemble qui a remporté le Grand Prix en 2009, d'une valeur d'un million de dollars. Peu après l'attribution du prix, Netflix a réalisé que les notes attribuées par les spectateurs n'étaient pas les meilleurs indicateurs de leurs habitudes de visionnage (« tout est une recommandation ») et a modifié son moteur de recommandation en conséquence. En 2010, un article du Wall Street Journal a souligné l'utilisation de l'apprentissage automatique par Rebellion Research pour prédire la crise financière de 2008 . En 2012, Vinod Khosla , cofondateur de Sun Microsystems , prévoyait que 80 % des emplois de médecins seraient supprimés au cours des deux décennies suivantes au profit des logiciels de diagnostic médical automatisés basés sur l'apprentissage automatique. En 2014, il a été rapporté qu'un algorithme d'apprentissage automatique avait été appliqué à l'histoire de l'art pour étudier des tableaux et qu'il aurait pu révéler des influences jusque-là insoupçonnées chez les artistes. En 2019 , Springer Nature a publié le premier ouvrage de recherche créé à l'aide de l'apprentissage automatique. En 2020, l'apprentissage automatique a été utilisé pour faciliter le diagnostic et aider les chercheurs à développer un traitement contre la COVID-19. Récemment, l'apprentissage automatique a été appliqué pour prédire les comportements écoresponsables des voyageurs. Plus récemment, l'apprentissage automatique a également été utilisé pour optimiser les performances et la gestion thermique des smartphones en fonction de l'interaction de l'utilisateur avec le téléphone. Correctement appliqués, les algorithmes d'apprentissage automatique (AA) peuvent exploiter un large éventail de caractéristiques d'entreprise pour prédire les rendements boursiers sans surapprentissage . Grâce à une ingénierie des caractéristiques efficace et à la combinaison de prévisions, les AA peuvent générer des résultats bien supérieurs à ceux obtenus par des techniques linéaires de base comme les moindres carrés ordinaires (MCO) .
Les progrès récents en matière d'apprentissage automatique se sont étendus au domaine de la chimie quantique, où de nouveaux algorithmes permettent désormais de prédire les effets du solvant sur les réactions chimiques, offrant ainsi de nouveaux outils aux chimistes pour adapter les conditions expérimentales afin d'obtenir des résultats optimaux.
L’apprentissage automatique devient un outil précieux pour étudier et prédire les décisions d’évacuation lors de catastrophes de grande et de petite ampleur. Différentes solutions ont été testées pour prédire si et quand les occupants d’un logement décident d’évacuer pendant les feux de forêt et les ouragans. D’autres applications se sont concentrées sur les décisions prises avant l’évacuation en cas d’incendie de bâtiment.
Limites
Bien que l’apprentissage automatique ait transformé certains domaines, les programmes d’apprentissage automatique ne parviennent souvent pas à produire les résultats escomptés. Les raisons de cet échec sont nombreuses : manque de données (appropriées), manque d’accès aux données, biais dans les données, problèmes de confidentialité, tâches et algorithmes mal choisis, outils et personnes inadaptés, manque de ressources et problèmes d’évaluation.
La théorie de la « boîte noire » pose un autre défi de taille. L’expression « boîte noire » désigne une situation où l’algorithme produisant un résultat est totalement opaque, ce qui signifie que même les concepteurs d’une application ne peuvent pas vérifier le modèle que la machine a extrait des données. La commission spéciale de la Chambre des lords a affirmé qu’un tel « système d’intelligence » susceptible d’avoir un « impact considérable sur la vie d’un individu » ne serait pas considéré comme acceptable à moins qu’il ne fournisse une explication complète et satisfaisante des décisions qu’il prend.
En 2018, une voiture autonome d' Uber n'a pas détecté un piéton, qui a été tué après une collision. Les tentatives d'utilisation de l'apprentissage automatique dans le domaine de la santé avec le système IBM Watson n'ont pas donné les résultats escomptés, malgré des années de développement et des milliards de dollars investis. Le chatbot Bing Chat de Microsoft a été signalé pour avoir tenu des propos hostiles et offensants envers ses utilisateurs.
L’apprentissage automatique a été utilisé comme stratégie pour actualiser les données probantes issues d’une revue systématique et pour alléger la charge de travail accrue des examinateurs liée à la croissance de la littérature biomédicale. Bien qu’il se soit amélioré grâce aux ensembles d’entraînement, il n’est pas encore suffisamment développé pour réduire la charge de travail sans compromettre la sensibilité nécessaire à la recherche elle-même.
Explicabilité
Le fait de s'en tenir à une théorie erronée et excessivement complexe, manipulée pour correspondre à toutes les données d'entraînement antérieures, est connu sous le nom de surapprentissage. De nombreux systèmes tentent de réduire le surapprentissage en récompensant une théorie en fonction de sa capacité à s'adapter aux données, mais en la pénalisant en fonction de sa complexité.
Effondrement du modèle
Hallucinations

Dans le domaine de l'intelligence artificielle (IA), une hallucination ou hallucination artificielle (également appelée baratin , confabulation ou délire ) est une réponse générée par l'IA qui contient des informations fausses ou trompeuses présentées comme des faits . Le terme établit une analogie approximative avec la psychologie humaine, où une hallucination implique généralement de fausses perceptions .
Par exemple, un chatbot alimenté par de grands modèles de langage (GML), comme ChatGPT , peut intégrer des contrevérités aléatoires d'apparence plausible dans son contenu généré. La détection et la correction des erreurs et des hallucinations constituent des défis majeurs pour le déploiement pratique et la fiabilité des GML dans des contextes critiques, tels que la conception de puces, la logistique de la chaîne d'approvisionnement et le diagnostic médical. Certains ingénieurs logiciels et statisticiens ont critiqué le terme « hallucination de l'IA », l'accusant d'anthropomorphiser les ordinateurs de manière abusive . Contrairement aux grands modèles de langage, les modèles d'intelligence artificielle symbolique ne produisent généralement pas d'hallucinations.
Autres limitations et vulnérabilités
Les apprenants peuvent également être déçus par un apprentissage erroné. Un exemple simple : un classificateur d’images entraîné uniquement sur des photos de chevaux bruns et de chats noirs pourrait conclure que toutes les taches brunes représentent probablement des chevaux. Plus concrètement, contrairement aux humains, les classificateurs d’images actuels ne fondent généralement pas leurs jugements sur la relation spatiale entre les éléments de l’image. Ils apprennent des relations entre pixels qui échappent à l’œil humain, mais qui correspondent néanmoins à des images de certains types d’objets réels. Modifier ces relations sur une image légitime peut produire des images « adversariales » que le système classera mal.
Les vulnérabilités adverses peuvent également résulter de systèmes non linéaires ou de perturbations non paramétriques. Pour certains systèmes, il est possible de modifier la sortie en changeant un seul pixel choisi de manière adverse. Les modèles d'apprentissage automatique sont souvent vulnérables à la manipulation ou à l'évasion par le biais de l'apprentissage automatique adverse .
Des chercheurs ont démontré comment des portes dérobées peuvent être insérées de manière indétectable dans des modèles d'apprentissage automatique de classification (par exemple, pour les catégories « spam » et « non-spam » des publications) souvent développés ou entraînés par des tiers. Ces derniers peuvent modifier la classification de n'importe quelle donnée d'entrée, même dans les cas où une certaine transparence des données/logiciels est assurée, incluant éventuellement un accès en boîte blanche .
Évaluations des modèles
La classification des modèles d'apprentissage automatique peut être validée par des techniques d'estimation de précision telles que la méthode de validation croisée ( ou validation externe), qui divise les données en un ensemble d'entraînement et un ensemble de test (généralement 2/3 pour l'entraînement et 1/3 pour le test) et évalue les performances du modèle entraîné sur l'ensemble de test. En comparaison, la méthode de validation croisée à K plis partitionne aléatoirement les données en K sous-ensembles, puis réalise K expériences, chacune considérant un sous-ensemble pour l'évaluation et les K-1 sous-ensembles restants pour l'entraînement du modèle. Outre les méthodes de validation croisée et de validation externe, le bootstrap , qui échantillonne n instances avec remise à partir de l'ensemble de données, peut être utilisé pour évaluer la précision du modèle.
Outre la précision globale, les chercheurs rapportent fréquemment la sensibilité et la spécificité , c'est-à-dire le taux de vrais positifs (TVP) et le taux de vrais négatifs (TVN), respectivement. De même, ils rapportent parfois le taux de faux positifs (TFP) ainsi que le taux de faux négatifs (TFN). Cependant, ces taux sont des ratios qui ne permettent pas d'identifier leurs numérateurs et dénominateurs. La courbe ROC ( Receiver Operating Characteristic ), ainsi que l'aire sous la courbe (AUC) correspondante, offrent des outils supplémentaires pour l'évaluation des modèles de classification. Une AUC plus élevée est associée à un modèle plus performant.
Éthique
Certains domaines d'application peuvent également avoir des implications éthiques particulièrement importantes, comme la santé , l'éducation, la justice pénale ou l'armée.
Biais
Bien que la collecte responsable des données et la documentation des règles algorithmiques utilisées par un système soient considérées comme des éléments essentiels de l'apprentissage automatique, certains chercheurs attribuent la vulnérabilité de l'apprentissage automatique aux biais au manque de participation et de représentation des populations minoritaires dans le domaine de l'IA. En effet, selon une étude menée par la Computing Research Association en 2021, les femmes ne représentent que 16,1 % du corps professoral spécialisé en IA dans plusieurs universités à travers le monde. De plus, parmi les nouveaux docteurs en IA résidant aux États-Unis, 45 % se déclarent blancs, 22,4 % asiatiques, 3,2 % hispaniques et 2,4 % afro-américains, ce qui illustre le manque de diversité dans le domaine de l'IA.
Il a été démontré que les modèles de langage appris à partir de données contiennent des biais similaires à ceux des humains. Puisque les langues humaines comportent des biais, les machines entraînées sur des corpus linguistiques apprendront nécessairement ces mêmes biais. En 2016, Microsoft a testé Tay , un chatbot qui apprenait à partir de Twitter, et celui-ci a rapidement intégré un langage raciste et sexiste.
Dans une expérience menée par ProPublica , un média d'investigation , un algorithme d'apprentissage automatique a identifié à tort les prévenus noirs comme présentant un risque élevé de récidive deux fois plus souvent que les prévenus blancs, comme étant deux fois plus susceptibles de récidiver. En 2015, Google Photos a confondu des personnes noires avec des gorilles, provoquant la polémique. L'étiquette « gorille » a été retirée par la suite, mais en 2023, l'application ne parvenait toujours pas à reconnaître les gorilles. Des problèmes similaires de reconnaissance des personnes non blanches ont été constatés dans de nombreux autres systèmes.
En raison de ces défis, l'adoption efficace de l'apprentissage automatique dans d'autres domaines pourrait prendre plus de temps. Le souci d' équité dans l'apprentissage automatique, c'est-à-dire la réduction des biais et la promotion de son utilisation au service du bien commun, est de plus en plus exprimé par les chercheurs en intelligence artificielle, notamment Fei-Fei Li , qui a déclaré : « L'IA n'a rien d'artificiel. Elle est inspirée par les humains, elle est créée par les humains et, surtout, elle a un impact sur eux. C'est un outil puissant que nous commençons à peine à comprendre, et cela représente une immense responsabilité. »
Incitations financières
Certains professionnels de santé craignent que ces systèmes ne soient pas conçus dans l'intérêt public, mais plutôt comme des outils de génération de profits. C'est particulièrement vrai aux États-Unis, où se pose depuis longtemps le dilemme éthique d'améliorer les soins de santé tout en augmentant les profits. Par exemple, les algorithmes pourraient être conçus pour prescrire aux patients des examens ou des médicaments inutiles, dans lesquels les propriétaires de l'algorithme détiennent des parts. L'apprentissage automatique en santé offre aux professionnels un outil supplémentaire potentiel pour diagnostiquer, traiter et planifier le rétablissement des patients, mais cela nécessite d'atténuer ces biais.
Matériel
Depuis les années 2010, les progrès réalisés tant dans les algorithmes d'apprentissage automatique que dans le matériel informatique ont permis de développer des méthodes plus efficaces pour l'entraînement des réseaux neuronaux profonds (un sous-domaine spécifique de l'apprentissage automatique) comportant de nombreuses couches d'unités cachées non linéaires. En 2019, les processeurs graphiques ( GPU ), souvent dotés d'améliorations spécifiques à l'IA, ont supplanté les processeurs (CPU) comme méthode dominante d'entraînement des systèmes d'IA commerciaux à grande échelle dans le cloud. OpenAI a estimé la puissance de calcul matérielle utilisée dans les plus grands projets d'apprentissage profond, d' AlexNet (2012) à AlphaZero (2017), et a constaté une multiplication par 300 000 de la puissance de calcul requise, avec un temps de doublement de 3,4 mois.
Unités de traitement tensoriel (TPU)
Les unités de traitement tensoriel (TPU) sont des accélérateurs matériels spécialisés développés par Google spécifiquement pour les charges de travail d'apprentissage automatique. Contrairement aux GPU et FPGA à usage général , les TPU sont optimisées pour les calculs tensoriels, ce qui les rend particulièrement efficaces pour les tâches d'apprentissage profond telles que l'entraînement et l'inférence. Elles sont largement utilisées dans les services d'IA de Google Cloud et les modèles d'apprentissage automatique à grande échelle comme DeepMind AlphaFold de Google et les grands modèles de langage. Les TPU exploitent des unités de multiplication matricielle et une mémoire à large bande passante pour accélérer les calculs tout en maintenant une efficacité énergétique optimale. Depuis leur introduction en 2016, les TPU sont devenues un composant clé de l'infrastructure d'IA, notamment dans les environnements cloud.
Calcul neuromorphique
L’informatique neuromorphique désigne une classe de systèmes informatiques conçus pour émuler la structure et la fonctionnalité des réseaux neuronaux biologiques. Ces systèmes peuvent être mis en œuvre par le biais de simulations logicielles sur du matériel conventionnel ou par le biais d’architectures matérielles spécialisées.
Réseaux neuronaux physiques
Un réseau neuronal physique est un type spécifique de matériel neuromorphique qui utilise des matériaux à résistance ajustable, tels que les memristors, pour émuler la fonction des synapses neuronales . Le terme « réseau neuronal physique » souligne l’utilisation de matériel physique pour le calcul, par opposition aux implémentations logicielles. Il désigne de manière générale les réseaux neuronaux artificiels qui utilisent des matériaux à résistance ajustable pour reproduire les synapses neuronales.
apprentissage automatique embarqué
L'apprentissage automatique embarqué est un sous-domaine de l'apprentissage automatique où les modèles sont déployés sur des systèmes embarqués aux ressources de calcul limitées, tels que les ordinateurs portables , les dispositifs périphériques et les microcontrôleurs . L'exécution directe des modèles sur ces dispositifs élimine la nécessité de transférer et de stocker des données sur des serveurs cloud pour un traitement ultérieur, réduisant ainsi les risques de fuites de données, de violations de la vie privée et de vol de propriété intellectuelle, de données personnelles et de secrets commerciaux. L'apprentissage automatique embarqué peut être mis en œuvre grâce à diverses techniques, telles que l'accélération matérielle , le calcul approximatif , et l'optimisation des modèles. Parmi les techniques d'optimisation courantes , on peut citer l'élagage , la quantification , la distillation des connaissances , la factorisation de faible rang, la recherche d'architecture de réseau et le partage de paramètres.
Logiciel
Logiciels propriétaires avec des éditions gratuites et open source
Logiciel propriétaire
Revues
Conférences
- Conférence AAAI sur l'intelligence artificielle
- Association pour la linguistique informatique ( ACL )
- Conférence européenne sur l'apprentissage automatique et les principes et pratiques de la découverte des connaissances dans les bases de données ( ECML PKDD )
- Conférence internationale sur les méthodes d'intelligence computationnelle pour la bioinformatique et la biostatistique ( CIBB )
- Conférence internationale sur l'apprentissage automatique ( ICML )
- Conférence internationale sur les représentations d'apprentissage ( ICLR )
- Conférence internationale sur les robots et systèmes intelligents ( IROS )
- Conférence sur la découverte des connaissances et l'exploration des données ( KDD )
- Conférence sur les systèmes de traitement de l'information neuronale ( NeurIPS )