L'inférence bayésienne (prononcé /beɪziən/ ou /beɪʒən / ) [ 1 ] est une méthode d' inférence statistique qui de Bayes pour calculer la probabilité d'une hypothèse, compte tenu des données a priori , et la mettre à jour à mesure que de nouvelles informations sont disponibles . Fondamentalement , l' inférence bayésienne utilise une distribution a priori pour estimer les probabilités a posteriori. C'est une technique importante en statistique , et plus particulièrement en statistique mathématique . La mise à jour bayésienne est essentielle pour l' analyse dynamique de séquences de données . L'inférence bayésienne trouve des applications dans de nombreux domaines, tels que les sciences , l'ingénierie , la philosophie , la médecine , le sport , la psychologie et le droit . En philosophie de la théorie de la décision , elle est étroitement liée à la probabilité subjective, souvent appelée « probabilité bayésienne ».
Introduction à la règle de Bayes
Explication formelle
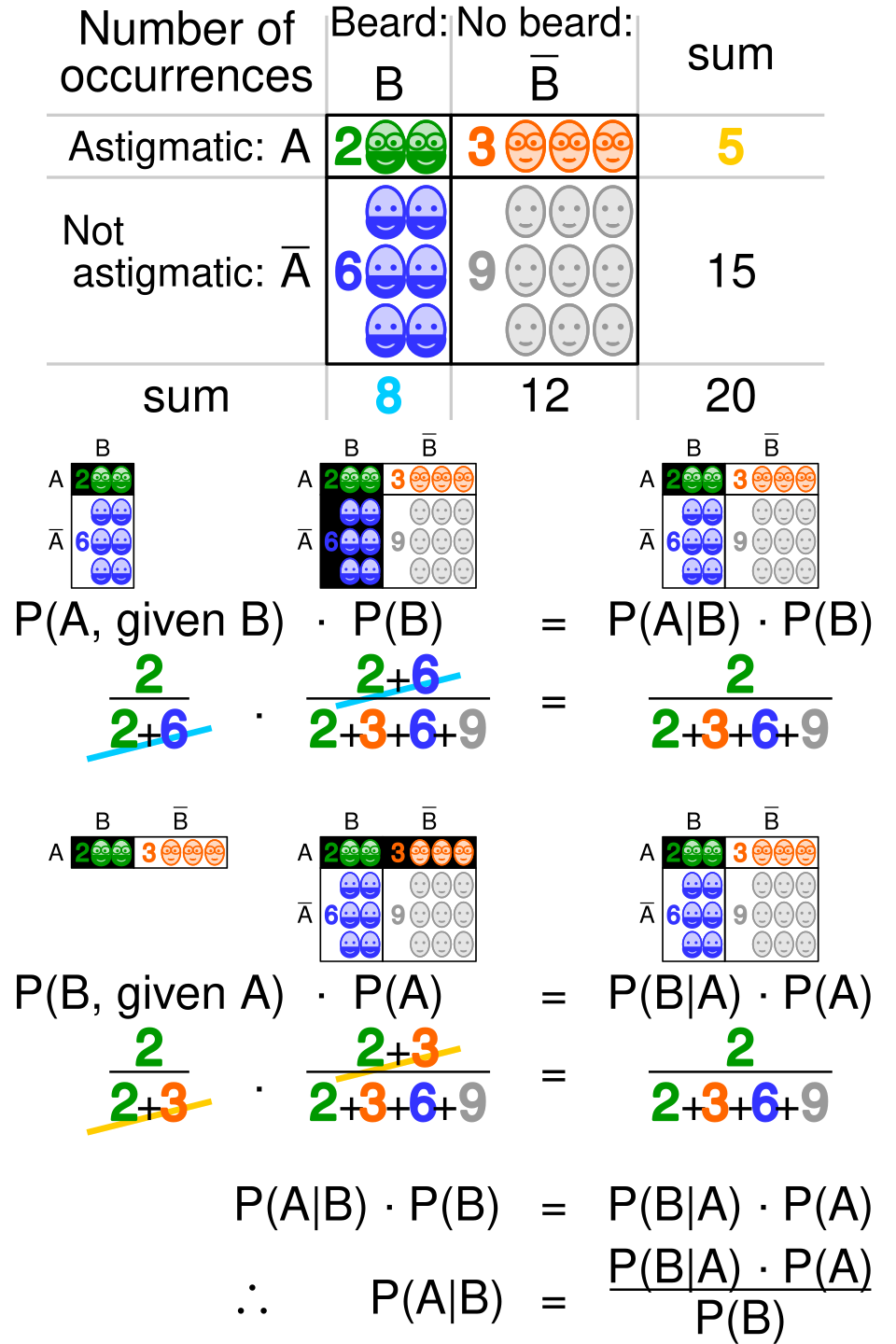
Hypothèse Preuve | Satisfait l'hypothèse H | Viole l' hypothèse | Total | |
|---|---|---|---|---|
| A-t-on des preuves E | | |||
| Aucune preuve | ||||
| Total | | 1 | ||
L'inférence bayésienne déduit la probabilité a posteriori à partir de deux antécédents : une probabilité a priori et une fonction de vraisemblance issue d'un modèle statistique appliqué aux données observées. L'inférence bayésienne calcule la probabilité a posteriori selon le théorème de Bayes .
où
0 (Sinon, on en a une .)
Pour différentes valeurs de , seuls les facteurs et , tous deux au numérateur, affectent la valeur de – la probabilité a posteriori d'une hypothèse est proportionnelle à sa probabilité a priori (sa vraisemblance intrinsèque) et à la vraisemblance nouvellement acquise (sa compatibilité avec les nouvelles preuves observées).
Dans les cas où (« non »), la négation logique de , est une vraisemblance valide, la règle de Bayes peut être réécrite comme suit :
parce que
et
Cela attire l'attention sur le terme
Si ce terme est approximativement égal à 1, la probabilité de l'hypothèse, compte tenu des preuves , est d'environ 50 % (probabilité égale ou nulle). Si ce terme est très petit, proche de zéro, la probabilité de l'hypothèse, compte tenu des preuves, est proche de 1, ou l'hypothèse conditionnelle est assez probable. Si ce terme est très grand, bien supérieur à 1, l'hypothèse, compte tenu des preuves, est assez improbable. Si l'hypothèse (sans tenir compte des preuves) est improbable, alors est petit (mais pas nécessairement astronomiquement petit) et est bien supérieur à 1 ; ce terme peut être approximé par et les probabilités pertinentes peuvent être comparées directement entre elles.
Une façon simple et rapide de se souvenir de l'équation serait d'utiliser la règle de la multiplication :
Alternatives à la mise à jour bayésienne
La mise à jour bayésienne est largement utilisée et pratique sur le plan informatique. Cependant, ce n'est pas la seule règle de mise à jour que l'on puisse considérer comme rationnelle.
Ian Hacking a fait remarquer que les arguments traditionnels du « livre hollandais » ne précisaient pas la mise à jour bayésienne : ils laissaient ouverte la possibilité que des règles de mise à jour non bayésiennes puissent éviter les livres hollandais. Hacking a écrit : « Ni l’argument du livre hollandais, ni aucun autre argument de l’arsenal personnaliste des preuves des axiomes de probabilité n’implique l’hypothèse dynamique. Aucun n’implique le bayésianisme. Le personnaliste exige donc que l’hypothèse dynamique soit bayésienne. Il est vrai que, par souci de cohérence, un personnaliste pourrait abandonner le modèle bayésien d’apprentissage par l’expérience. Le sel pourrait alors perdre de sa saveur. »
En effet, il existe des règles de mise à jour non bayésiennes qui évitent également les livres néerlandais (comme indiqué dans la littérature sur la « cinématique des probabilités ») suite à la publication de la règle de Richard C. Jeffrey , qui applique la règle de Bayes au cas où la probabilité est elle-même attribuée à la preuve. Les hypothèses supplémentaires nécessaires pour exiger de manière unique une mise à jour bayésienne ont été jugées substantielles, complexes et insatisfaisantes.
Inférence sur les possibilités exclusives et exhaustives
Si les preuves sont utilisées simultanément pour mettre à jour les croyances sur un ensemble de propositions exclusives et exhaustives, l'inférence bayésienne peut être considérée comme agissant sur cette distribution de croyances dans son ensemble.
Formulation générale
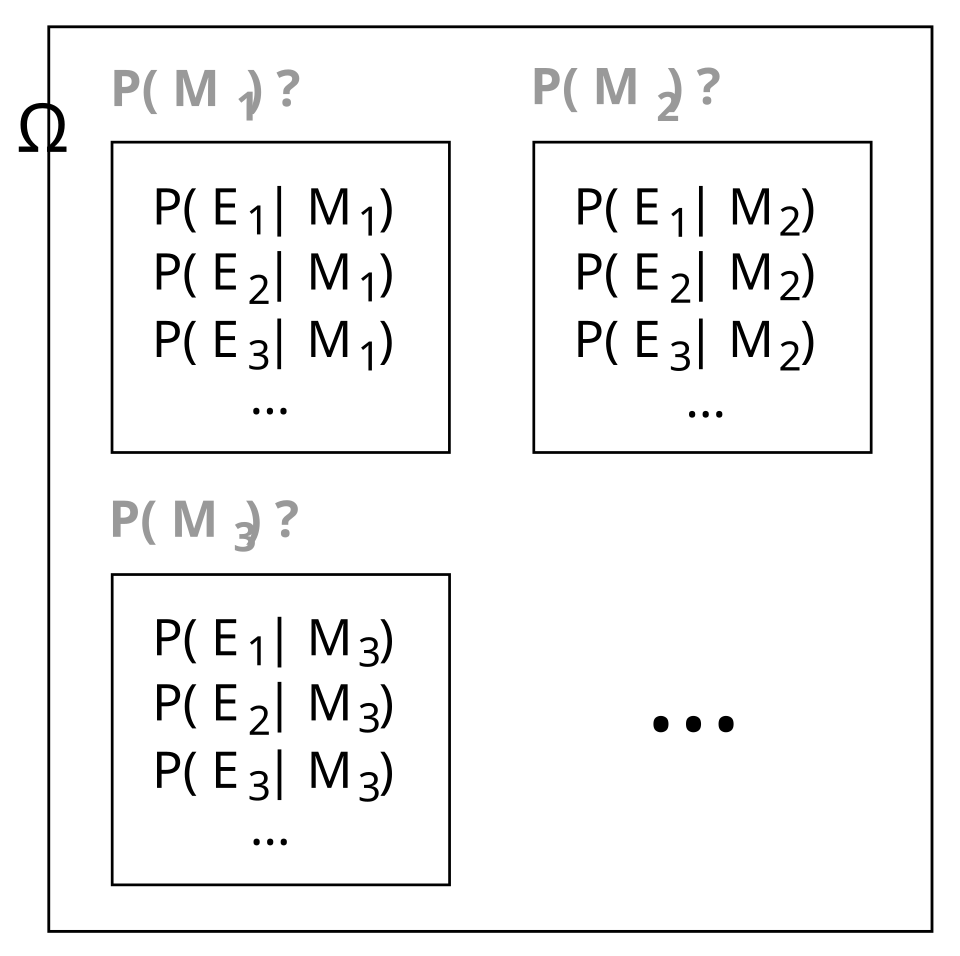
Supposons qu'un processus génère des événements indépendants et identiquement distribués , mais dont la distribution de probabilité est inconnue. Soit l'espace des événements représentant l'état actuel des croyances relatives à ce processus. Chaque modèle est représenté par un événement . Les probabilités conditionnelles sont spécifiées pour définir les modèles. représente le degré de croyance en . Avant la première étape d'inférence, est un ensemble de probabilités a priori initiales . Leur somme doit être égale à 1, mais elles sont par ailleurs arbitraires.
Supposons que le processus génère . Pour chaque , la distribution a priori est mise à jour en distribution a posteriori . D'après le théorème de Bayes :
Cette procédure peut être répétée après examen de nouveaux éléments de preuve.
Observations multiples
Pour une suite d' observations indépendantes et identiquement distribuées , on peut démontrer par récurrence que l'application répétée de ce qui précède est équivalente à où
Formulation paramétrique : motivation de la description formelle
En paramétrant l'espace des modèles, la croyance en tous les modèles peut être mise à jour en une seule étape. La distribution de la croyance sur l'espace des modèles peut alors être vue comme une distribution de la croyance sur l'espace des paramètres. Les distributions présentées dans cette section sont exprimées comme continues, représentées par des densités de probabilité, conformément à la pratique courante. La technique est cependant tout aussi applicable aux distributions discrètes.
Soit le vecteur engendrant l'espace des paramètres. Soit la distribution a priori initiale sur , où est un ensemble de paramètres de la distribution a priori elle-même, ou hyperparamètres . Soit une suite d' observations d'événements indépendantes et identiquement distribuées , où toutes sont distribuées comme pour un certain . Le théorème de Bayes est appliqué pour trouver la distribution a posteriori sur :
Description formelle
Définitions
inférence bayésienne
- La distribution a priori est la distribution du ou des paramètres avant toute observation de données . Il peut être difficile de déterminer cette distribution a priori ; dans ce cas, une solution possible consiste à utiliser la distribution a priori de Jeffreys pour obtenir une distribution a priori avant de la mettre à jour avec de nouvelles observations.
- La distribution d'échantillonnage est la distribution des données observées conditionnellement à ses paramètres, c'est-à-dire . On parle également de vraisemblance , notamment lorsqu'elle est considérée comme une fonction du ou des paramètres, parfois notée .
- La vraisemblance marginale (parfois appelée évidence ) est la distribution des données observées marginalisée par rapport au(x) paramètre(s). Elle quantifie la concordance entre les données et l'avis d'experts, de manière géométrique et précise. Si la vraisemblance marginale est nulle, il n'y a pas de concordance entre les données et l'avis d'experts et le théorème de Bayes ne peut être appliqué.
- La distribution a posteriori est la distribution du ou des paramètres après prise en compte des données observées. Elle est déterminée par la règle de Bayes , qui est au cœur de l'inférence bayésienne.
Cela s'exprime en termes de « la probabilité a posteriori est proportionnelle à la vraisemblance multipliée par la probabilité a priori », ou parfois par « la probabilité a posteriori = la vraisemblance multipliée par la probabilité a priori, sur la base des preuves ».
- En pratique, pour la quasi-totalité des modèles bayésiens complexes utilisés en apprentissage automatique, la distribution a posteriori n'est pas obtenue sous forme analytique, principalement parce que l'espace des paramètres peut être très vaste, ou parce que le modèle bayésien conserve une certaine structure hiérarchique formulée à partir des observations et du paramètre . Dans de telles situations, il est nécessaire de recourir à des techniques d'approximation.
- Cas général : Soit la distribution conditionnelle de sachant et soit la distribution de . La distribution conjointe est alors . La distribution conditionnelle de sachant est alors déterminée par
prédiction bayésienne
- La distribution prédictive a posteriori est la distribution d'un nouveau point de données, marginalisée sur la distribution a posteriori :
- La distribution prédictive a priori est la distribution d'un nouveau point de données, marginalisée par rapport à la distribution a priori :
La théorie bayésienne préconise l'utilisation de la distribution prédictive a posteriori pour effectuer des inférences prédictives , c'est-à-dire pour prédire la distribution d'une nouvelle donnée non observée. Autrement dit, au lieu d'une valeur fixe comme prédiction, on retourne une distribution sur les valeurs possibles. Seule cette méthode permet d'utiliser l'intégralité de la distribution a posteriori du ou des paramètres. En comparaison, la prédiction en statistique fréquentiste consiste souvent à trouver une estimation ponctuelle optimale du ou des paramètres (par exemple, par la méthode du maximum de vraisemblance ou du maximum a posteriori , MAP), puis à intégrer cette estimation dans la formule de la distribution d'une donnée. Cette approche présente l'inconvénient de ne pas tenir compte de l'incertitude liée à la valeur du paramètre et, par conséquent, de sous-estimer la variance de la distribution prédictive.
Dans certains cas, les statistiques fréquentistes permettent de contourner ce problème. Par exemple, les intervalles de confiance et les intervalles de prédiction, lorsqu'ils sont construits à partir d'une distribution normale de moyenne et de variance inconnues, utilisent une distribution t de Student . Cette méthode estime correctement la variance, car (1) la moyenne des variables aléatoires normalement distribuées suit également une loi normale, et (2) la distribution prédictive d'une donnée normalement distribuée, de moyenne et de variance inconnues, avec des lois a priori conjuguées ou non informatives, suit une loi t de Student. En revanche, en statistiques bayésiennes, la distribution prédictive a posteriori peut toujours être déterminée avec exactitude, ou du moins avec une précision arbitraire lorsque des méthodes numériques sont utilisées.
Les deux types de distributions prédictives ont la forme d'une distribution de probabilité composée (tout comme la vraisemblance marginale ). En effet, si la distribution a priori est une distribution a priori conjuguée , de sorte que les distributions a priori et a posteriori appartiennent à la même famille, on constate que les distributions prédictives a priori et a posteriori appartiennent également à la même famille de distributions composées. La seule différence réside dans le fait que la distribution prédictive a posteriori utilise les valeurs mises à jour des hyperparamètres (en appliquant les règles de mise à jour bayésiennes décrites dans l' article sur les distributions a priori conjuguées ), tandis que la distribution prédictive a priori utilise les valeurs des hyperparamètres qui figurent dans la distribution a priori.
propriétés mathématiques
Interprétation du facteur

La règle de Cromwell
Si alors . Si et , alors . Cela peut s'interpréter comme signifiant que les convictions profondes sont insensibles aux contre-preuves.
Le premier résultat découle directement du théorème de Bayes. Le second se déduit en appliquant la première règle à l'événement « non » au lieu de « », ce qui donne « si , alors », d'où le résultat s'impose immédiatement.
Comportement asymptotique de la partie postérieure
Considérons le comportement d'une distribution de croyances mise à jour un grand nombre de fois par des épreuves indépendantes et identiquement distribuées . Pour des probabilités a priori suffisamment régulières, le théorème de Bernstein-von Mises montre qu'à la limite d'un nombre infini d'épreuves, la distribution a posteriori converge vers une loi normale indépendante de la probabilité a priori initiale, sous certaines conditions initialement énoncées et rigoureusement démontrées par Joseph L. Doob en 1948, à savoir si la variable aléatoire considérée possède un espace de probabilité fini . Des résultats plus généraux ont été obtenus ultérieurement par le statisticien David A. Freedman, qui a publié deux articles de recherche fondamentaux en 1963 et 1965 , établissant les conditions et les circonstances dans lesquelles le comportement asymptotique de la distribution a posteriori est garanti. Son article de 1963 traite, comme celui de Doob (1949), le cas fini et aboutit à une conclusion satisfaisante. Cependant, si la variable aléatoire possède un espace de probabilité infini mais dénombrable (correspondant par exemple à un dé à une infinité de faces), l'article de 1965 démontre que, pour un sous-ensemble dense de lois a priori, le théorème de Bernstein-von Mises n'est pas applicable. Dans ce cas, la convergence asymptotique est quasi certaine . Plus tard, dans les années 1980 et 1990, Freedman et Persi Diaconis ont poursuivi leurs travaux sur le cas des espaces de probabilité infinis mais dénombrables. En résumé, le nombre d'essais peut être insuffisant pour supprimer les effets du choix initial, et la convergence peut être particulièrement lente pour les grands systèmes (mais finis).
Priors conjugués
Sous forme paramétrée, la distribution a priori est souvent supposée appartenir à une famille de distributions appelées distributions a priori conjuguées . L'intérêt d'une distribution a priori conjuguée réside dans le fait que la distribution a posteriori correspondante appartient à la même famille, et que le calcul peut être exprimé sous forme analytique .
Estimations des paramètres et prédictions
On souhaite souvent utiliser une distribution a posteriori pour estimer un paramètre ou une variable. Plusieurs méthodes d'estimation bayésienne sélectionnent des mesures de tendance centrale à partir de cette distribution.
Pour les problèmes unidimensionnels, il existe une médiane unique pour les problèmes continus pratiques. La médiane a posteriori est intéressante en tant qu'estimateur robuste .
S’il existe une moyenne finie pour la distribution a posteriori, alors la moyenne a posteriori est une méthode d’estimation.
Prendre une valeur avec la plus grande probabilité définit l' estimation a posteriori maximale (MAP) :
Il existe des exemples où aucun maximum n'est atteint, auquel cas l'ensemble des estimations MAP est vide .
Il existe d'autres méthodes d'estimation qui minimisent le risque postérieur (perte postérieure attendue) par rapport à une fonction de perte , et celles-ci présentent un intérêt pour la théorie statistique de la décision utilisant la distribution d'échantillonnage (statistiques fréquentistes).
La distribution prédictive postérieure d'une nouvelle observation (qui est indépendante des observations précédentes) est déterminée par
Exemples
Probabilité d'une hypothèse
Bol Cookie | #1 H 1 | #2 H 2 | Total | |
|---|---|---|---|---|
| Plaine, E | 30 | 20 | 50 | |
| Choc, ¬ E | 10 | 20 | 30 | |
| Total | 40 | 40 | 80 | |
| P ( H1 | E ) = 30/50 = 0,6 | ||||
Supposons qu'il y ait deux bols remplis de biscuits. Le bol n° 1 contient 10 biscuits aux pépites de chocolat et 30 biscuits nature, tandis que le bol n° 2 en contient 20 de chaque. Fred choisit un bol au hasard, puis un biscuit au hasard également. Autrement dit, rien ne permet de penser qu'il traite les deux bols différemment, ni les biscuits différemment. Le biscuit choisi est un biscuit nature. La probabilité que Fred l'ait pris dans le bol n° 1 est un exemple de problème pouvant être résolu par inférence bayésienne.
Intuitivement, il semble évident que la réponse devrait être supérieure à la moitié, puisqu'il y a plus de biscuits nature dans le bol n° 1. La réponse précise est donnée par le théorème de Bayes. Soit le bol n° 1 et le bol n° 2. On sait que les bols sont identiques du point de vue de Fred, donc et , et la somme des deux doit être égale à 1, donc et sont tous deux égaux à 0,5. L'événement est l'observation d'un biscuit nature. D'après le contenu des bols, on sait que et la formule de Bayes donne alors .
Avant que Fred ne voie son biscuit, la probabilité qu'il ait choisi le bol n° 1 était la probabilité a priori. En prenant connaissance du biscuit, l'estimation mieux informée de Fred (ou de tout observateur) est mise à jour.
Faire une prédiction
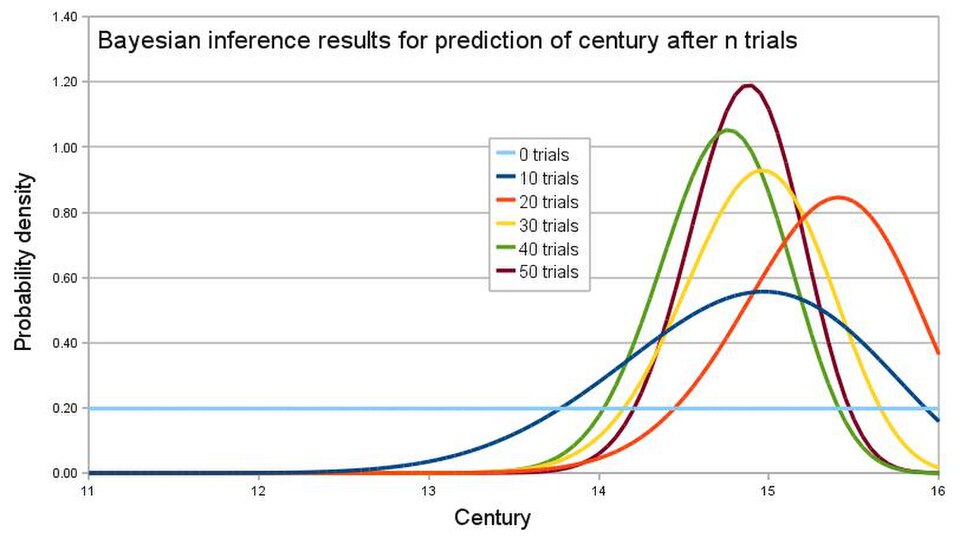
Un archéologue travaille sur un site que l'on pense être d'époque médiévale, entre le XIe et le XVIe siècle. Cependant, la période d'occupation du site reste incertaine. Des fragments de poterie ont été mis au jour, certains vernissés, d'autres décorés. On estime que si le site a été occupé au début du Moyen Âge, 1 % de la poterie serait vernissée et 50 % décorée, tandis que s'il a été occupé à la fin du Moyen Âge, 81 % de la poterie serait vernissée et 5 % décorée. Dans quelle mesure l'archéologue peut-il dater l'occupation du site au vu des fragments exhumés ?
Le degré de croyance en la variable continue (siècle) doit être calculé à partir de l'ensemble discret d'événements . Les informations du paragraphe précédent permettent d'obtenir la probabilité de l'émail et la probabilité du décor ; leurs compléments étant : En supposant une variation linéaire de l'émail et du décor au fil du temps et l'indépendance de ces variables, la probabilité de chaque événement s'écrit :
La découverte d'un nouveau fragment de ce type apporte davantage d'informations à l'enquête et, grâce au théorème de Bayes, permet une inférence bayésienne actualisée , renforçant ainsi la fiabilité de l'estimation des archéologues. En supposant une distribution a priori uniforme de et que les essais soient indépendants et identiquement distribués ,
La simulation informatique de l'évolution des croyances suite à la mise au jour de 50 fragments est présentée sur le graphique. Dans cette simulation, le site était habité vers 1420. En calculant l'aire sous la courbe pour la portion pertinente du graphique sur 50 essais, l'archéologue peut conclure qu'il est pratiquement impossible que le site ait été habité aux XIe et XIIe siècles, qu'il y a environ 1 % de chances qu'il l'ait été au XIIIe siècle, 63 % au XIVe siècle et 36 % au XVe siècle. Le théorème de Bernstein-von Mises démontre ici la convergence asymptotique vers la distribution « vraie », car l' espace de probabilité correspondant à l'ensemble discret d'événements est fini (voir la section précédente sur le comportement asymptotique de la distribution a posteriori).
En statistique fréquentiste et en théorie de la décision
Abraham Wald a fourni une justification décisionnelle de l'utilisation de l'inférence bayésienne en démontrant que toute procédure bayésienne unique est admissible . Réciproquement, toute procédure statistique admissible est soit une procédure bayésienne, soit une limite de procédures bayésiennes.
Wald a caractérisé les procédures admissibles comme des procédures bayésiennes (et des limites de procédures bayésiennes), faisant du formalisme bayésien une technique centrale dans des domaines de l'inférence fréquentiste tels que l'estimation de paramètres , les tests d'hypothèses et le calcul des intervalles de confiance . Par exemple :
- « Sous certaines conditions, toutes les procédures admissibles sont soit des procédures bayésiennes, soit des limites de procédures bayésiennes (au sens de divers termes). Ces résultats remarquables, du moins dans leur forme originale, sont essentiellement dus à Wald. Ils sont utiles car la propriété d’être bayésien est plus facile à analyser que l’admissibilité. »
- « En théorie de la décision, une méthode assez générale pour prouver l’admissibilité consiste à démontrer qu’une procédure est une solution bayésienne unique. »
- Dans les premiers chapitres de cet ouvrage, les distributions a priori à support fini et les procédures bayésiennes correspondantes ont été utilisées pour établir certains des principaux théorèmes relatifs à la comparaison d'expériences. Les procédures bayésiennes, appliquées à des distributions a priori plus générales, ont joué un rôle primordial dans le développement des statistiques, notamment dans sa théorie asymptotique. Dans de nombreux problèmes, un simple coup d'œil aux distributions a posteriori, pour des distributions a priori appropriées, fournit des informations immédiatement intéressantes. De plus, cette technique est quasiment incontournable en analyse séquentielle.
- "Un fait utile est que toute règle de décision bayésienne obtenue en prenant une distribution a priori appropriée sur l'ensemble de l'espace des paramètres doit être admissible"
- « Un domaine d’investigation important dans le développement des idées d’admissibilité a été celui des procédures de théorie d’échantillonnage conventionnelles, et de nombreux résultats intéressants ont été obtenus. »
Sélection du modèle
La méthodologie bayésienne intervient également dans la sélection de modèles, dont l'objectif est de choisir, parmi un ensemble de modèles concurrents, celui qui représente le mieux le processus sous-jacent ayant généré les données observées. Dans la comparaison bayésienne de modèles, on sélectionne le modèle ayant la plus forte probabilité a posteriori, compte tenu des données. Cette probabilité dépend de la vraisemblance marginale (ou évidence ), qui reflète la probabilité que les données soient générées par le modèle, et de la croyance a priori associée à ce modèle. Lorsque deux modèles concurrents sont considérés a priori comme équiprobables, le rapport de leurs probabilités a posteriori correspond au facteur de Bayes . Puisque la comparaison bayésienne de modèles vise à sélectionner le modèle ayant la plus forte probabilité a posteriori, cette méthodologie est également appelée règle de sélection du maximum a posteriori (MAP) ou règle de probabilité MAP
Programmation probabiliste
Bien que conceptuellement simples, les méthodes bayésiennes peuvent s'avérer complexes sur les plans mathématique et numérique. Les langages de programmation probabilistes (LPP) implémentent des fonctions permettant de construire facilement des modèles bayésiens, ainsi que des méthodes d'inférence automatiques efficaces. Ceci contribue à dissocier la construction du modèle de l'inférence, permettant ainsi aux praticiens de se concentrer sur leurs problèmes spécifiques, les LPP prenant en charge les détails de calcul.
Applications
Analyse statistique des données
Voir l'article Wikipédia distinct sur les statistiques bayésiennes , et plus particulièrement la section sur la modélisation statistique .
Applications informatiques
L'inférence bayésienne trouve des applications en intelligence artificielle et en systèmes experts . Les techniques d'inférence bayésienne constituent un élément fondamental des techniques de reconnaissance de formes informatisées depuis la fin des années 1950 . On observe également un lien croissant entre les méthodes bayésiennes et les techniques de simulation de Monte Carlo, car les modèles complexes ne peuvent être traités de manière analytique par une approche bayésienne, tandis qu'une structure de modèle graphique permet des algorithmes de simulation efficaces tels que l' échantillonnage de Gibbs et d'autres algorithmes de Metropolis-Hastings . Récemment, l'inférence bayésienne a gagné en popularité au sein de la communauté phylogénétique pour ces raisons ; de nombreuses applications permettent d'estimer simultanément de nombreux paramètres démographiques et évolutifs.
Appliquée à la classification statistique , l'inférence bayésienne a permis de développer des algorithmes d'identification des spams . Parmi les applications utilisant l'inférence bayésienne pour le filtrage des spams, on peut citer CRM114 , DSPAM , Bogofilter , SpamAssassin , SpamBayes , Mozilla , XEAMS, et bien d'autres. La classification des spams est traitée plus en détail dans l'article consacré au classificateur naïf de Bayes .
L'inférence inductive de Solomonoff est la théorie de la prédiction fondée sur l'observation ; par exemple, prédire le symbole suivant à partir d'une série de symboles donnée. La seule hypothèse est que l'environnement suit une distribution de probabilité inconnue mais calculable . Il s'agit d'un cadre inductif formel qui combine deux principes bien établis de l'inférence inductive : les statistiques bayésiennes et le rasoir d'Occam . La probabilité a priori universelle de Solomonoff pour tout préfixe p d'une séquence calculable x est la somme des probabilités de tous les programmes (pour un ordinateur universel) qui calculent une fonction commençant par p . Étant donné un préfixe p et une distribution de probabilité calculable mais inconnue à partir de laquelle x est échantillonné, la probabilité a priori universelle et le théorème de Bayes peuvent être utilisés pour prédire de manière optimale les parties encore inconnues de x .
Applications bioinformatiques et de santé
L’inférence bayésienne a été appliquée dans différentes applications bioinformatiques , notamment l’analyse de l’expression différentielle des gènes. Elle est également utilisée dans un modèle général de risque de cancer, appelé CIRI (Continuous Individualized Risk Index), où des mesures sérielles sont intégrées pour mettre à jour un modèle bayésien principalement construit à partir de connaissances a priori.
Cosmologie et applications astrophysiques
L'approche bayésienne a été au cœur des progrès récents en cosmologie et en applications astrophysiques, et s'étend à un large éventail de problèmes astrophysiques, notamment la caractérisation des exoplanètes (comme l'ajustement de l'atmosphère pour k2-18b ), les contraintes de paramètres avec des données cosmologiques, et l'étalonnage dans les expériences astrophysiques.
En cosmologie, cette approche est souvent employée conjointement avec des techniques de calcul telles que la méthode de Monte Carlo par chaînes de Markov (MCMC) et l'algorithme d'échantillonnage imbriqué pour analyser des ensembles de données complexes et explorer l'espace des paramètres de grande dimension. Une application notable concerne les données du fond diffus cosmologique (CMB) de Planck 2018 pour l'inférence des paramètres. Les six paramètres cosmologiques de base du modèle Lambda-CDM ne sont pas prédits par une théorie, mais plutôt ajustés à partir des données du fond diffus cosmologique (CMB) à un modèle cosmologique choisi (le modèle Lambda-CDM). Le code bayésien pour la cosmologie « cobaya » configure des simulations cosmologiques et interagit avec les vraisemblances cosmologiques et le code de Boltzmann, qui calcule les anisotropies du CMB prédites pour tout ensemble donné de paramètres cosmologiques, avec MCMC ou un échantillonneur imbriqué.
Ce cadre de calcul ne se limite pas au modèle standard ; il est également essentiel pour tester des théories cosmologiques alternatives ou étendues, telles que les théories intégrant l’énergie sombre primordiale ou les théories de la gravité modifiée introduisant des paramètres supplémentaires au-delà du modèle Lambda-CDM. La comparaison bayésienne de modèles peut alors être utilisée pour calculer la force probante des modèles concurrents, fournissant ainsi une base statistique pour évaluer si les données les soutiennent par rapport au modèle Lambda-CDM standard
Dans la salle d'audience
L'inférence bayésienne peut être utilisée par les jurés pour rassembler de manière cohérente les preuves à charge et à décharge, et pour déterminer si, dans leur ensemble, elles satisfont à leur propre critère de « doute raisonnable ». Le théorème de Bayes est appliqué successivement à toutes les preuves présentées, la probabilité a posteriori d'une étape devenant la probabilité a priori de la suivante. L'avantage d'une approche bayésienne est qu'elle offre au juré un mécanisme impartial et rationnel pour combiner les preuves. Il peut être judicieux d'expliquer le théorème de Bayes aux jurés sous forme de cotes , car les cotes de paris sont plus largement comprises que les probabilités. Une approche logarithmique , remplaçant la multiplication par l'addition, pourrait également être plus facile à appréhender pour un jury.
Si l'existence du crime n'est pas remise en question, mais seulement l'identité du coupable, il a été suggéré que la probabilité a priori soit uniforme sur l'ensemble de la population concernée. Par exemple, si 1 000 personnes auraient pu commettre le crime, la probabilité a priori de culpabilité serait de 1/1 000.
L'utilisation du théorème de Bayes par les jurés est controversée. Au Royaume-Uni, dans l'affaire R c. Adams , un expert de la défense a expliqué ce théorème au jury . Le jury a prononcé un verdict de culpabilité, mais l'affaire a été portée en appel au motif qu'aucun moyen de recueillir des preuves n'avait été fourni aux jurés qui ne souhaitaient pas utiliser le théorème de Bayes. La Cour d'appel a confirmé la condamnation, mais a également estimé que « l'introduction du théorème de Bayes, ou de toute méthode similaire, dans un procès pénal plonge le jury dans des domaines théoriques et complexes inappropriés et inutiles, le détournant ainsi de sa mission première ».
Gardner-Medwin soutient que le critère sur lequel un verdict dans un procès pénal devrait se fonder n'est pas la probabilité de culpabilité, mais plutôt la probabilité des preuves, étant donné que l'accusé est innocent (semblable à une p-valeur fréquentiste ). Il affirme que si la probabilité a posteriori de culpabilité doit être calculée par le théorème de Bayes, la probabilité a priori de culpabilité doit être connue. Celle-ci dépendra de la fréquence du crime, ce qui constitue un élément de preuve inhabituel dans un procès pénal. Considérons les trois propositions suivantes :
- A – les faits et témoignages connus auraient pu être établis si l’accusé était coupable.
- B – les faits et témoignages connus auraient pu être établis même si l’accusé était innocent.
- C – l’accusé est coupable.
Gardner-Medwin soutient que, pour prononcer une condamnation, le jury doit croire à la fois à A et à la négation de B. L'affirmation « A et non B » implique la vérité de C , mais la réciproque est fausse. Il est possible que B et C soient toutes deux vraies, mais dans ce cas, il soutient qu'un jury doit acquitter, même s'il sait qu'il laissera des coupables en liberté. Voir également le paradoxe de Lindley .
épistémologie bayésienne
L'épistémologie bayésienne est un mouvement qui prône l'inférence bayésienne comme moyen de justifier les règles de la logique inductive.
Karl Popper et David Miller ont rejeté l'idée de rationalisme bayésien, c'est-à-dire l'utilisation du théorème de Bayes pour formuler des inférences épistémologiques : Ce rationalisme est sujet au même cercle vicieux que toute autre épistémologie justificationniste , car il présuppose ce qu'il tente de justifier. Selon cette perspective, une interprétation rationnelle de l'inférence bayésienne la considérerait simplement comme une version probabiliste de la falsification , rejetant ainsi la croyance, communément admise par les bayésiens, selon laquelle une forte vraisemblance obtenue par une série de mises à jour bayésiennes prouverait l'hypothèse au-delà de tout doute raisonnable, voire avec une vraisemblance supérieure à 0.
Autre
- La méthode scientifique est parfois interprétée comme une application de l'inférence bayésienne. Dans cette perspective, la règle de Bayes guide (ou devrait guider) la mise à jour des probabilités relatives aux hypothèses , conditionnellement à de nouvelles observations ou expériences . L'inférence bayésienne a également été appliquée au traitement des problèmes d'ordonnancement stochastique à information incomplète par Cai et al. (2009).
- La théorie de la recherche bayésienne est utilisée pour rechercher des objets perdus.
- Inférence bayésienne en phylogénie
- Outil bayésien pour l'analyse de la méthylation
- Les approches bayésiennes de la fonction cérébrale étudient le cerveau comme un mécanisme bayésien.
- Inférence bayésienne dans les études écologiques
- L'inférence bayésienne est utilisée pour estimer les paramètres dans les modèles cinétiques chimiques stochastiques
- Inférence bayésienne en éconophysique pour les devises ou la prédiction des changements de tendance dans les cotations financières
- L'inférence bayésienne en marketing
- Inférence bayésienne dans l'apprentissage moteur
- L'inférence bayésienne est utilisée en modélisation numérique probabiliste pour résoudre des problèmes numériques.
Bayes et inférence bayésienne
Le problème considéré par Bayes dans la proposition 9 de son essai, « Un essai pour résoudre un problème dans la doctrine des chances », est la distribution postérieure du paramètre a (le taux de succès) de la distribution binomiale .
Histoire
Le terme « bayésien » fait référence à Thomas Bayes (1701-1761), qui a démontré qu'il était possible d'imposer des limites probabilistes à un événement inconnu. Cependant, c'est Pierre-Simon Laplace (1749-1827) qui a introduit (sous le nom de Principe VI) ce que l'on appelle aujourd'hui le théorème de Bayes et l'a utilisé pour résoudre des problèmes de mécanique céleste , de statistiques médicales, de fiabilité et de jurisprudence . Les premières méthodes d'inférence bayésienne, qui utilisaient des lois a priori uniformes conformément au principe de raison insuffisante de Laplace , étaient appelées probabilité inverse (car elles infèrent à rebours, des observations aux paramètres, ou des effets aux causes). Après les années 1920, la probabilité inverse a été largement supplantée par un ensemble de méthodes regroupées sous l'appellation de statistiques fréquentistes .
Au XXe siècle, les idées de Laplace ont été approfondies selon deux axes distincts, donnant naissance aux courants objectif et subjectif de la pratique bayésienne. Dans le courant objectif (ou « non informatif »), l'analyse statistique repose uniquement sur le modèle supposé, les données analysées et la méthode d'attribution de la distribution a priori, laquelle varie d'un praticien bayésien objectif à l'autre. Dans le courant subjectif (ou « informatif »), la spécification de la distribution a priori dépend des croyances – les propositions sur lesquelles l'analyse s'appuie – qui peuvent synthétiser des informations issues d'experts, d'études antérieures, etc.
Dans les années 1980, la recherche et les applications des méthodes bayésiennes ont connu un essor spectaculaire, principalement dû à la découverte des méthodes de Monte Carlo par chaînes de Markov , qui ont permis de résoudre de nombreux problèmes de calcul, et à un intérêt croissant pour les applications complexes et non standard. Malgré ce développement, l'enseignement universitaire de premier cycle reste majoritairement fondé sur les statistiques fréquentistes. Les méthodes bayésiennes sont néanmoins largement acceptées et utilisées, notamment dans le domaine de l'apprentissage automatique .