Parmi les applications majeures de l'IA figurent les moteurs de recherche web avancés , les chatbots , les assistants virtuels , les véhicules autonomes , ainsi que le jeu et l'analyse dans les jeux de stratégie (comme les échecs et le go ). Depuis les années 2020, l'IA générative est largement accessible pour générer des images, des fichiers audio et des vidéos à partir de requêtes textuelles.
Les objectifs traditionnels de la recherche en IA comprennent l'apprentissage, le raisonnement , la représentation des connaissances , la planification , le traitement automatique du langage naturel et la perception , ainsi que le soutien à la robotique . Pour atteindre ces objectifs, les chercheurs en IA ont utilisé des techniques telles que la recherche dans l'espace d'états et l'optimisation mathématique , la logique formelle , les réseaux de neurones artificiels et des méthodes basées sur les statistiques , la recherche opérationnelle et l'économie . L'IA s'appuie également sur la psychologie , la linguistique , la philosophie , les neurosciences et d'autres domaines. Certaines entreprises, comme OpenAI , Google DeepMind et Meta , visent à créer une intelligence artificielle générale (IAG) son histoire [ suivies de périodes de déception et de réduction des financements, connues sous le nom d' « hivers de l'IA » . Les financements et l'intérêt ont considérablement augmenté après 2012, lorsque les processeurs graphiques ont commencé à être utilisés pour accélérer les réseaux neuronaux et que l'apprentissage profond a surpassé les techniques d'IA précédentes . Cette croissance s'est encore accélérée après 2017 avec l' architecture Transformer . Dans les années 2020, un essor de l'IA a coïncidé avec les progrès de l'IA générative , qui a permis la création et la modification de médias. Outre les questions de sécurité de l'IA et les conséquences et préjudices imprévus liés à son utilisation, les préoccupations éthiques , les effets à long terme de l'IA et les risques existentiels potentiels ont alimenté les débats sur la réglementation de l'IA .
des déductions logiques . À la fin des années 1980 et dans les années 1990, des méthodes ont été développées pour traiter les informations incertaines ou incomplètes, en utilisant des concepts issus des probabilités et de l'économie .Nombre de ces algorithmes sont insuffisants pour résoudre des problèmes de raisonnement complexes car ils subissent une « explosion combinatoire » : leur vitesse d’exécution diminue exponentiellement à mesure que la complexité des problèmes augmente. Même les humains utilisent rarement la déduction étape par étape que les premières recherches en IA pouvaient modéliser. Ils résolvent la plupart de leurs problèmes grâce à des jugements rapides et intuitifs.
Les modèles de raisonnement , un type de modèle de langage de grande taille entraîné à générer des chaînes de pensée intermédiaires, ont émergé en 2024 et ont permis d'améliorer les performances sur des problèmes complexes en mathématiques et en codage.
Représentation des connaissances
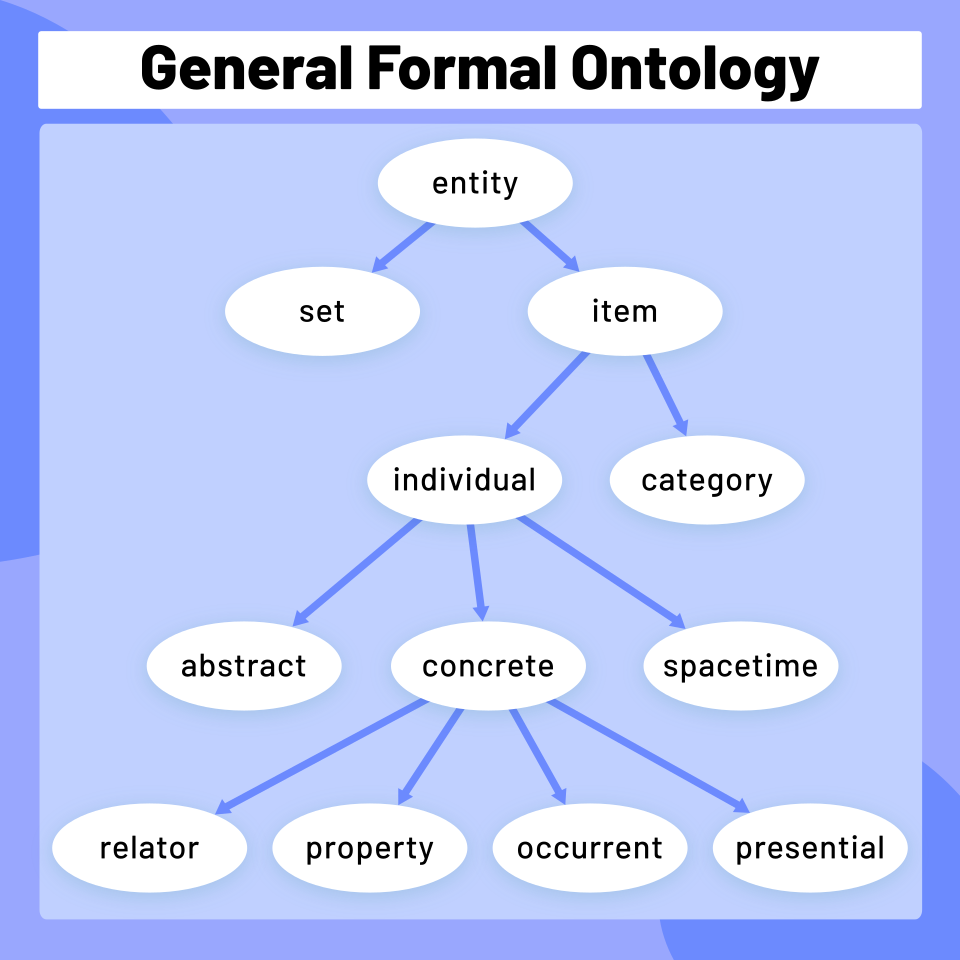
La représentation et l'ingénierie des connaissances permettent aux programmes d'IA de répondre intelligemment aux questions et de faire des déductions sur des faits du monde réel. Les représentations formelles des connaissances sont utilisées dans l'indexation et la recherche basées sur le contenu , l'interprétation de scènes , l'aide à la décision clinique , la découverte de connaissances (extraction d'inférences « intéressantes » et exploitables à partir de grandes bases de données ) et d'autres domaines.
Une base de connaissances est un ensemble de connaissances représentées sous une forme utilisable par un programme. Une ontologie est l'ensemble des objets, relations, concepts et propriétés utilisés par un domaine de connaissances particulier. Les bases de connaissances doivent représenter des éléments tels que les objets, les propriétés, les catégories et les relations entre objets ; les situations, les événements, les états et le temps ; les causes et les effets ; la connaissance sur la connaissance (ce que nous savons de ce que les autres savent) ; le raisonnement par défaut (les choses que les humains tiennent pour vraies jusqu'à preuve du contraire et qui restent vraies même lorsque d'autres faits changent) ; et bien d'autres aspects et domaines de la connaissance.
Parmi les problèmes les plus complexes de la représentation des connaissances figurent l'étendue du savoir commun (l'ensemble des faits élémentaires que connaît une personne lambda est immense) ; et la forme sub-symbolique de la plupart des connaissances du sens commun (une grande partie de ce que les gens savent n'est pas représentée sous forme de « faits » ou d'« énoncés » qu'ils pourraient exprimer verbalement). Se pose également la difficulté de l'acquisition des connaissances , c'est-à-dire le problème de l'obtention de connaissances pour les applications d'IA.
Planification et prise de décision
Un « agent » est toute entité (artificielle ou non) qui perçoit le monde et y agit. Un agent rationnel a des objectifs ou des préférences et agit pour les atteindre. Dans la planification automatisée , l’agent poursuit un objectif précis. Dans la prise de décision automatisée , l’agent a des préférences : il préfère certaines situations et cherche à éviter d’autres. L’agent de décision attribue à chaque situation une valeur numérique (appelée « utilité ») qui mesure son degré de préférence. Pour chaque action possible, il calcule l’« utilité espérée » : l’utilité de tous les résultats possibles de l’action, pondérée par la probabilité d’occurrence de chaque résultat. Il choisit ensuite l’action qui maximise l’utilité espérée.
Dans la planification classique , l'agent connaît précisément l'effet de chaque action. Cependant, dans la plupart des problèmes du monde réel, l'agent peut être incertain de la situation dans laquelle il se trouve (elle est « inconnue » ou « inobservable ») et il peut ignorer ce qui se produira après chaque action possible (elle n'est pas « déterministe »). Il doit choisir une action en faisant une estimation probabiliste, puis réévaluer la situation pour vérifier si l'action a été efficace.
Outre des tests approfondis et une amélioration basée sur les décisions précédentes, le fait de fournir une explication sur les raisons pour lesquelles l'agent a pris certaines décisions est un moyen de renforcer la confiance, surtout lorsque ces décisions doivent être prises.
Dans certains problèmes, les préférences de l'agent peuvent être incertaines, notamment en présence d'autres agents ou d'humains. Ces préférences peuvent être apprises (par exemple, par apprentissage par renforcement inverse ), ou l'agent peut rechercher des informations pour les améliorer. La théorie de la valeur de l'information permet d'évaluer la pertinence des actions exploratoires ou expérimentales. L'espace des actions et situations futures possibles étant généralement extrêmement vaste, les agents doivent agir et évaluer les situations en étant incertains du résultat.
Un processus de décision markovien comporte un modèle de transition qui décrit la probabilité qu'une action particulière modifie l'état d'une manière spécifique, et une fonction de récompense qui fournit l'utilité de chaque état et le coût de chaque action. Une politique associe une décision à chaque état possible. Cette politique peut être calculée (par exemple, par itération ), être heuristique ou encore être apprise.
La théorie des jeux décrit le comportement rationnel de plusieurs agents interagissant et est utilisée dans les programmes d'IA qui prennent des décisions impliquant d'autres agents.
Apprentissage
L’apprentissage automatique est l’étude des programmes capables d’améliorer automatiquement leurs performances sur une tâche donnée. Il fait partie de l’IA depuis ses débuts.
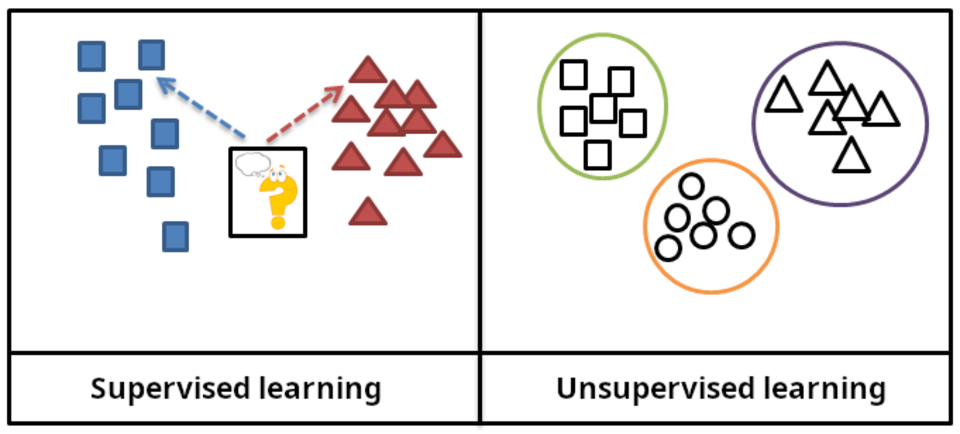
Il existe plusieurs types d'apprentissage automatique. L'apprentissage non supervisé analyse un flux de données, en identifie des modèles et effectue des prédictions sans aucune autre instruction. L'apprentissage supervisé nécessite l'étiquetage des données d'entraînement avec les réponses attendues et se divise en deux grandes catégories : la classification (où le programme doit apprendre à prédire à quelle catégorie appartient l'entrée) et la régression (où le programme doit déduire une fonction numérique à partir d'une entrée numérique).
En apprentissage par renforcement , l'agent est récompensé pour ses bonnes réponses et pénalisé pour ses mauvaises. Il apprend ainsi à choisir les réponses considérées comme « bonnes » . L'apprentissage par transfert consiste à appliquer les connaissances acquises lors de la résolution d'un problème à un nouveau problème . L'apprentissage profond est une forme d'apprentissage automatique qui utilise des réseaux de neurones artificiels bio-inspirés pour traiter les données d'entrée et ainsi mettre en œuvre tous ces types d'apprentissage
La théorie de l'apprentissage computationnel peut évaluer les apprenants par la complexité computationnelle , par la complexité de l'échantillon (la quantité de données requises) ou par d'autres notions d' optimisation .
Les premiers travaux, fondés sur la grammaire générative et les réseaux sémantiques de Noam Chomsky , rencontraient des difficultés pour la désambiguïsation du sens des mots sauf lorsqu'ils étaient restreints à de petits domaines appelés « micro-mondes » (en raison du problème de la connaissance du sens commun ). Margaret Masterman estimait que c'était le sens, et non la grammaire, qui était la clé de la compréhension des langues, et que les thésaurus, et non les dictionnaires, devaient constituer la base de la structure informatique du langage.
Les techniques modernes d'apprentissage profond pour le TALN incluent l'intégration de mots (représentation des mots, généralement sous forme de vecteurs codant leur signification) , les transformeurs (une architecture d'apprentissage profond utilisant un mécanisme d'attention ) et d'autres . En 2019, les modèles de langage génératifs pré-entraînés de type transformeur (ou « GPT ») ont commencé à générer du texte cohérent , et dès 2023, ces modèles étaient capables d'obtenir des scores comparables à ceux des humains à l' examen du barreau , au test SAT , au test GRE et dans de nombreuses autres applications concrètes
Perception
La perception machine est la capacité d'utiliser les données provenant de capteurs (tels que caméras, microphones, signaux sans fil, lidar actif , sonar, radar et capteurs tactiles ) pour déduire des aspects du monde. La vision par ordinateur est la capacité d'analyser les données visuelles.
Le domaine comprend la reconnaissance vocale , la classification d'images , la reconnaissance faciale , la reconnaissance d'objets , le suivi d'objets , et la perception robotique .
intelligence sociale

L’informatique affective est un domaine qui regroupe les systèmes capables de reconnaître, d’interpréter, de traiter ou de simuler les sentiments, les émotions et l’humeur humaines . Par exemple, certains assistants virtuels sont programmés pour parler de manière conversationnelle, voire pour plaisanter avec humour ; cela les rend plus sensibles à la dynamique émotionnelle des interactions humaines, ou facilite l’interaction homme-machine .
Cependant, cela tend à donner aux utilisateurs novices une conception irréaliste de l'intelligence des agents informatiques existants. Parmi les succès modérés liés à l'informatique affective, on peut citer l'analyse des sentiments textuels et, plus récemment, l'analyse multimodale des sentiments , où l'IA classe les réactions d'un sujet filmé.
Renseignements généraux
Une machine dotée d’ une intelligence artificielle générale serait capable de résoudre une grande variété de problèmes avec une ampleur et une polyvalence similaires à celles de l’intelligence humaine .
Techniques
La recherche en IA utilise une grande variété de techniques pour atteindre les objectifs ci-dessus.
Recherche et optimisation
Il existe deux types de recherche différents utilisés en IA : la recherche dans l’espace d’états et la recherche locale :
recherche dans l'espace d'état
La recherche dans l'espace d'états parcourt un arbre d'états possibles pour tenter de trouver un état final. Par exemple, les algorithmes de planification parcourent des arbres d'objectifs et de sous-objectifs, cherchant à trouver un chemin vers un objectif cible, un processus appelé analyse moyens-fins .
Les recherches exhaustives simples sont rarement suffisantes pour la plupart des problèmes concrets : l’ espace de recherche (le nombre d’emplacements à explorer) atteint rapidement des valeurs astronomiques . Il en résulte une recherche trop lente , voire interminable. Les « heuristiques » ou « règles empiriques » permettent de privilégier les choix les plus susceptibles de mener à l’objectif.
La recherche adverse est utilisée pour les programmes de jeux , tels que les échecs ou le go. Elle parcourt un arbre de coups et de contre-coups possibles, à la recherche d'une position gagnante.
Recherche locale
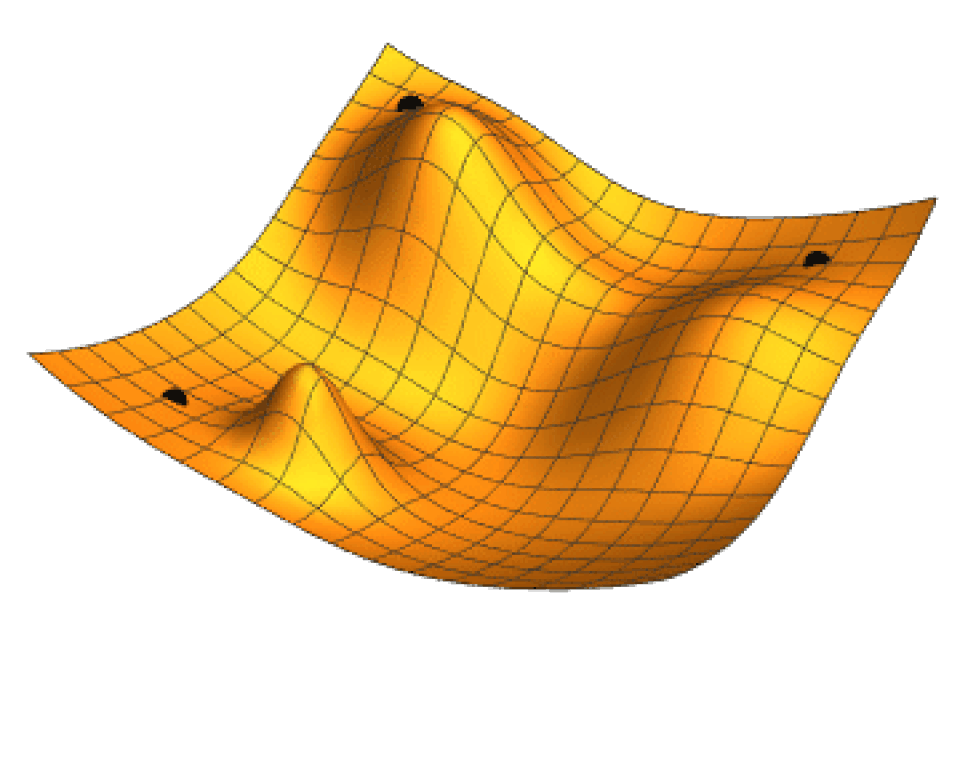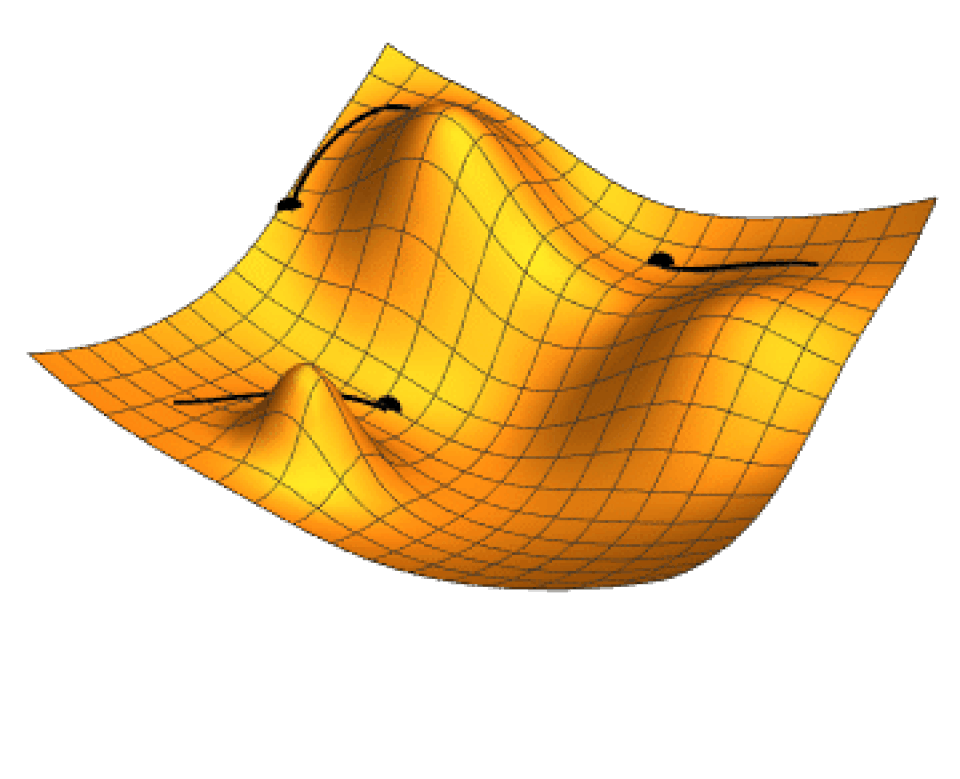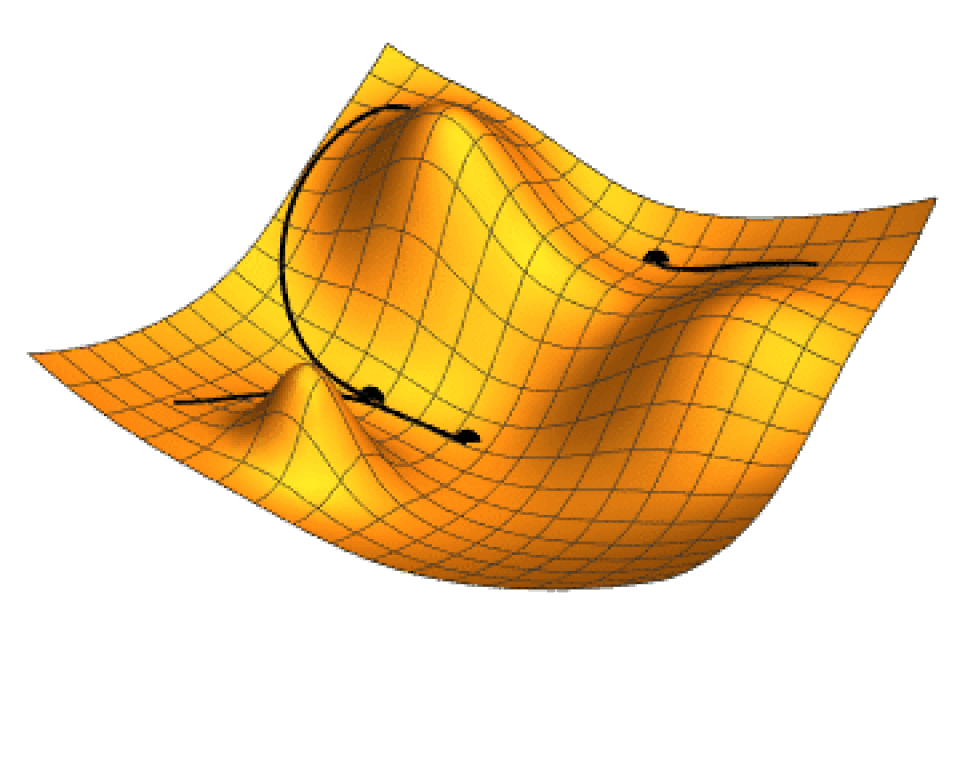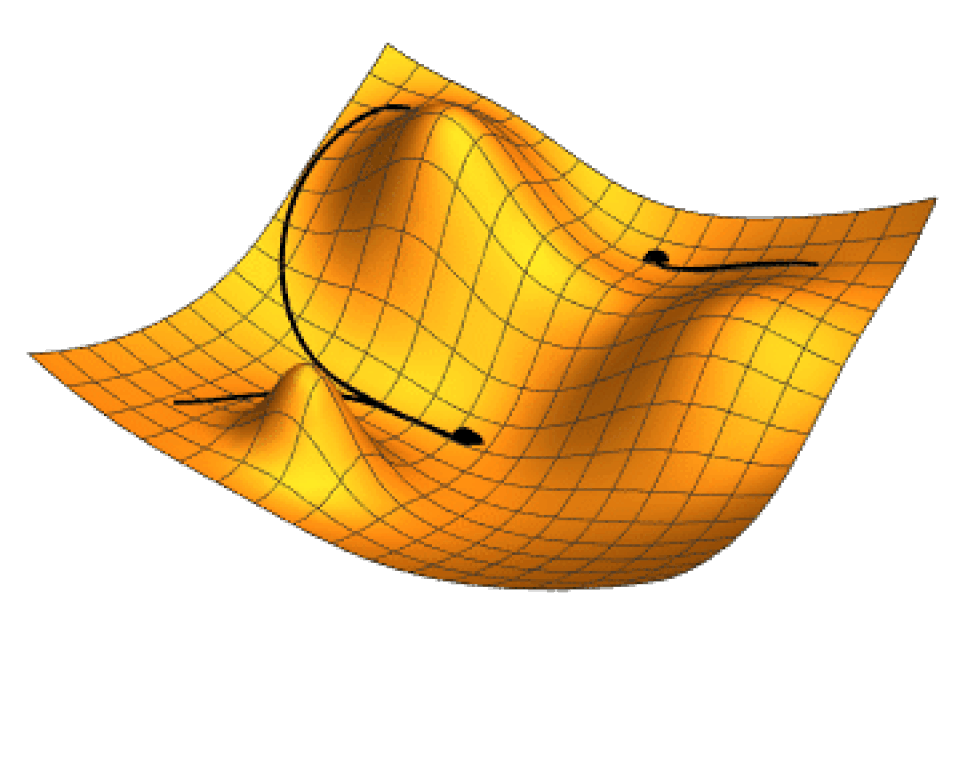
La recherche locale utilise l'optimisation mathématique pour trouver une solution à un problème. Elle commence par une forme de supposition et l'affine progressivement.
La descente de gradient est un type de recherche locale qui optimise un ensemble de paramètres numériques en les ajustant progressivement pour minimiser une fonction de perte . Des variantes de la descente de gradient sont couramment utilisées pour entraîner les réseaux de neurones [ grâce à l' algorithme rétropropagation .
Un autre type de recherche locale est le calcul évolutionnaire , qui vise à améliorer itérativement un ensemble de solutions candidates en les « mutant » et en les « recombinant », en ne sélectionnant que les plus aptes pour survivre à chaque génération.
Les processus de recherche distribués peuvent se coordonner via des algorithmes d'intelligence collective . Deux algorithmes d'intelligence collective populaires utilisés dans la recherche sont l'optimisation par essaim de particules (inspirée par le vol des oiseaux ) et l'optimisation par colonie de fourmis (inspirée par les pistes de fourmis ).
Logique
La logique formelle est utilisée pour le raisonnement et la représentation des connaissances . La logique formelle se présente sous deux formes principales : la logique propositionnelle (qui opère sur des énoncés vrais ou faux et utilise des connecteurs logiques tels que « et », « ou », « non » et « implique ») et la logique des prédicats (qui opère également sur des objets, des prédicats et des relations et utilise des quantificateurs tels que « Tout X est un Y » et « Il existe des X qui sont des Y »).
Le raisonnement déductif en logique est le processus qui consiste à prouver une nouvelle proposition ( conclusion ) à partir d'autres propositions données et supposées vraies (les prémisses ). Les preuves peuvent être structurées sous forme d'arbres de preuve , dans lesquels les nœuds sont étiquetés par des phrases et les nœuds enfants sont reliés aux nœuds parents par des règles d'inférence .
Étant donné un problème et un ensemble de prémisses, la résolution de problèmes se ramène à la recherche d'un arbre de preuve dont la racine est étiquetée par une solution du problème et les feuilles par des prémisses ou des axiomes . Dans le cas des clauses de Horn , la recherche de solutions peut s'effectuer par un raisonnement ascendant à partir des prémisses ou descendant à partir du problème. Dans le cas plus général de la forme clausale de la logique du premier ordre , la résolution est une règle d'inférence unique, sans axiome, dans laquelle un problème est résolu en démontrant une contradiction à partir de prémisses incluant la négation du problème à résoudre.
L'inférence, tant en logique des clauses de Horn qu'en logique du premier ordre, est indécidable et donc impossible à résoudre . Cependant, le raisonnement à rebours avec les clauses de Horn, qui sous-tend les calculs dans le langage de programmation logique Prolog , est Turing-complet . De plus, son efficacité est comparable à celle des calculs effectués dans d'autres langages de programmation symbolique .
La logique floue attribue un « degré de vérité » entre 0 et 1. Elle peut donc traiter des propositions vagues et partiellement vraies.
Les logiques non monotones , y compris la programmation logique avec la négation comme échec , sont conçues pour gérer le raisonnement par défaut . D'autres versions spécialisées de la logique ont été développées pour décrire de nombreux domaines complexes.
Méthodes probabilistes pour le raisonnement en situation d'incertitude
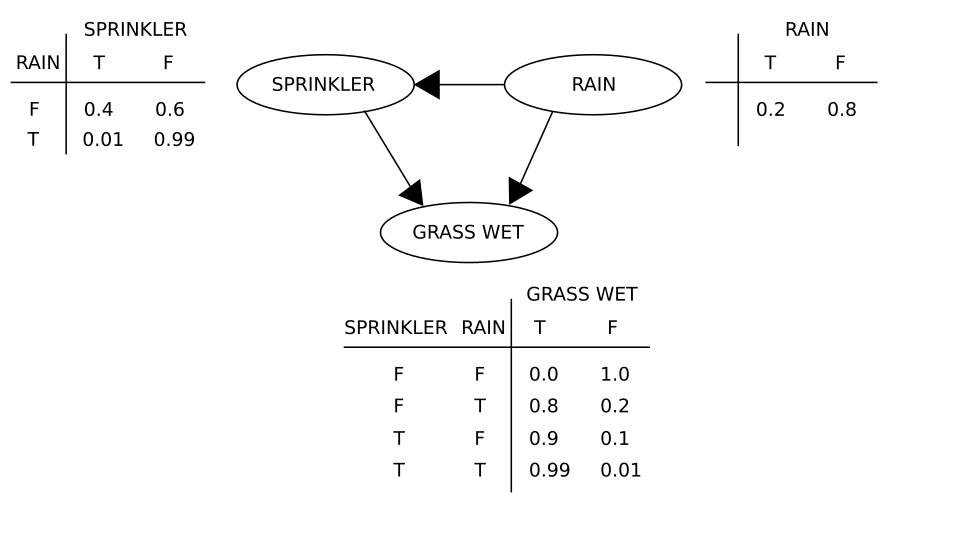
De nombreux problèmes en intelligence artificielle (raisonnement, planification, apprentissage, perception et robotique) exigent que l'agent fonctionne avec des informations incomplètes ou incertaines. Les chercheurs en IA ont conçu plusieurs outils pour résoudre ces problèmes en utilisant des méthodes issues de la théorie des probabilités et de l'économie. Des outils mathématiques précis ont été développés pour analyser comment un agent peut faire des choix et planifier, en s'appuyant sur la théorie de la décision , l' analyse décisionnelle et la théorie de la valeur de l'information . Parmi ces outils figurent des modèles tels que les processus de décision markoviens , les réseaux de décision dynamiques , la théorie des jeux et la conception de mécanismes .
Les réseaux bayésiens sont un outil qui peut être utilisé pour le raisonnement (en utilisant l' algorithme d'inférence bayésienne ), l'apprentissage (en utilisant l' algorithme d'espérance-maximisation ), la planification (en utilisant les réseaux de décision ) et la perception (en utilisant les réseaux bayésiens dynamiques ).
Les algorithmes probabilistes peuvent également être utilisés pour le filtrage, la prédiction, le lissage et la recherche d'explications pour les flux de données, aidant ainsi les systèmes de perception à analyser les processus qui se produisent au fil du temps (par exemple, les modèles de Markov cachés ou les filtres de Kalman ).

Classificateurs et méthodes d'apprentissage statistique
Les applications d'IA les plus simples se divisent en deux catégories : les classificateurs (par exemple, « si brillant, alors diamant ») et les contrôleurs (par exemple, « si diamant, alors ramasser »). Les classificateurs sont des fonctions qui utilisent la reconnaissance de formes pour identifier la correspondance la plus proche. Ils peuvent être affinés à l'aide d'exemples sélectionnés grâce à l'apprentissage supervisé . Chaque motif (également appelé « observation ») est étiqueté avec une classe prédéfinie. L'ensemble des observations, associées à leurs étiquettes de classe, constitue un jeu de données . Lorsqu'une nouvelle observation est reçue, elle est classée en fonction de l'expérience acquise.
Il existe de nombreux types de classificateurs. L' arbre de décision est l'algorithme d'apprentissage automatique symbolique le plus simple et le plus répandu. L'algorithme des k plus proches voisins était l'IA analogique la plus utilisée jusqu'au milieu des années 1990, avant d'être supplanté par les méthodes à noyau telles que les machines à vecteurs de support (SVM) dans les années 1990. Le classificateur naïf de Bayes est, semble-t-il, « l'algorithme d'apprentissage le plus utilisé » chez Google, notamment grâce à son évolutivité. Les réseaux de neurones sont également utilisés comme classificateurs.
réseaux neuronaux artificiels
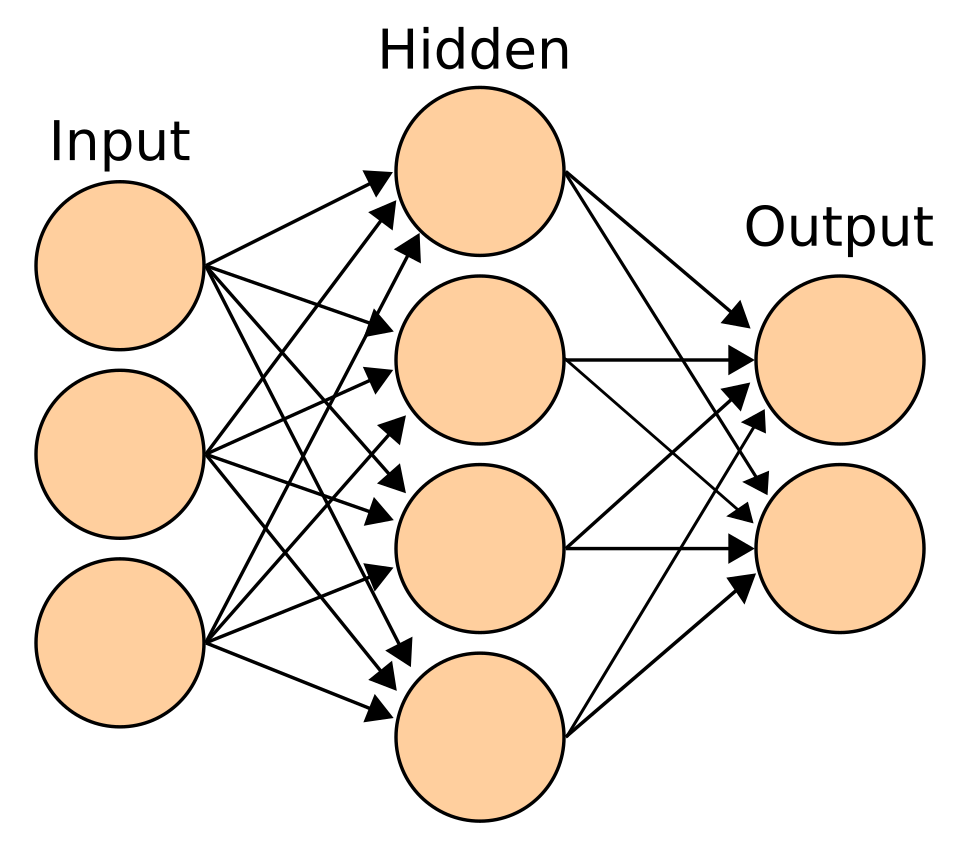
Un réseau de neurones artificiels est constitué d'un ensemble de nœuds, également appelés neurones artificiels , qui modélisent de manière simplifiée les neurones du cerveau biologique. Il est entraîné à reconnaître des motifs ; une fois entraîné, il peut reconnaître ces motifs dans de nouvelles données. Il comporte une entrée, au moins une couche cachée de nœuds et une sortie. Chaque nœud applique une fonction et, lorsque son poids dépasse un seuil prédéfini, les données sont transmises à la couche suivante. Un réseau est généralement qualifié de réseau de neurones profond s'il possède au moins deux couches cachées.
Les algorithmes d'apprentissage des réseaux de neurones utilisent la recherche locale pour choisir les poids qui permettront d'obtenir la sortie appropriée pour chaque entrée lors de l'entraînement. La technique d'entraînement la plus courante est l' algorithme de rétropropagation . Les réseaux de neurones apprennent à modéliser des relations complexes entre les entrées et les sorties et à identifier des motifs dans les données. En théorie, un réseau de neurones peut apprendre n'importe quelle fonction.
Dans les réseaux de neurones à propagation directe, le signal ne circule que dans un seul sens. Le terme perceptron désigne généralement un réseau de neurones à une seule couche. À l'inverse, l'apprentissage profond utilise de nombreuses couches. Les réseaux de neurones récurrents (RNN) réinjectent le signal de sortie dans l'entrée, ce qui permet de conserver une mémoire à court terme des événements d'entrée précédents. Les réseaux LSTM ( Long Short-Term Memory ) sont des réseaux de neurones récurrents qui préservent mieux les dépendances à long terme et sont moins sensibles au problème de disparition du gradient . Les réseaux de neurones convolutifs (CNN) utilisent des couches de noyaux pour traiter plus efficacement les motifs locaux. Ce traitement local est particulièrement important en traitement d'images , où les premières couches des CNN identifient généralement des motifs locaux simples tels que les contours et les courbes, les couches suivantes détectant des motifs plus complexes comme les textures, et finalement des objets entiers.
Apprentissage profond
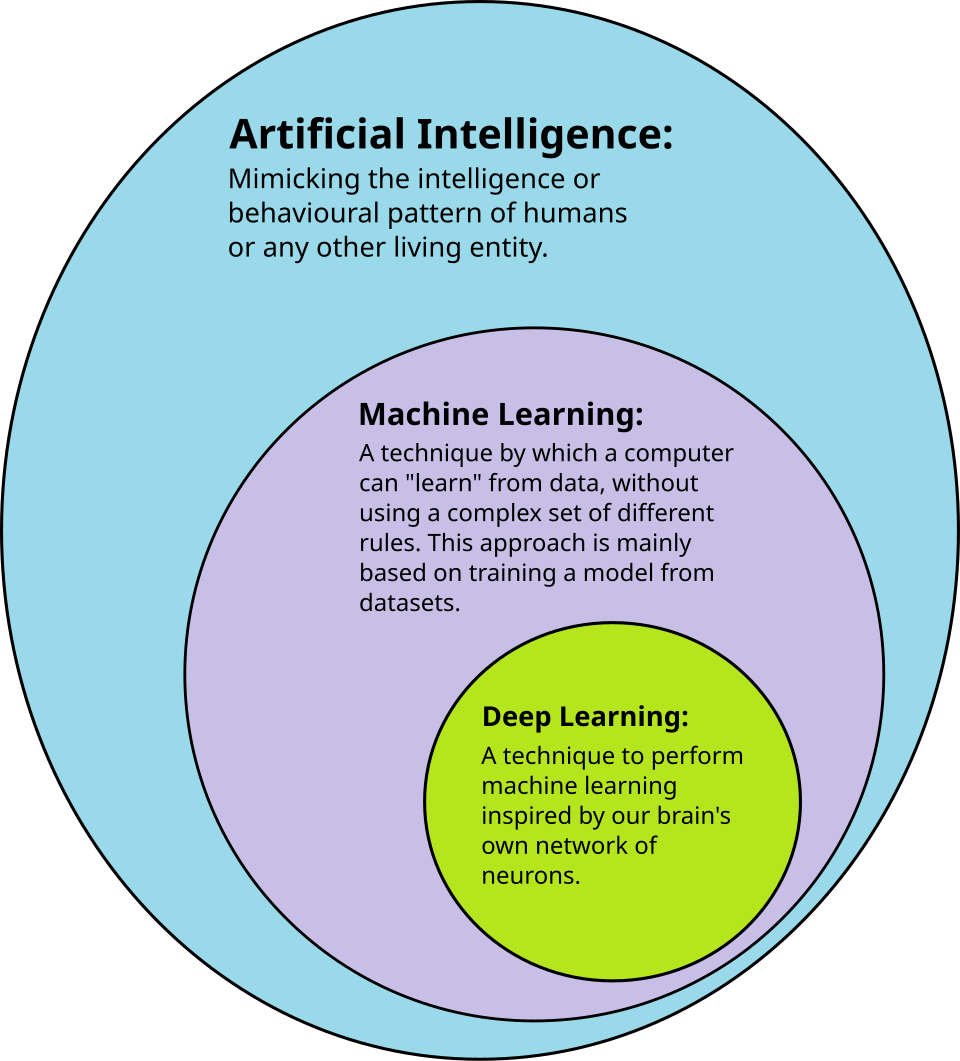
L’apprentissage profond utilise plusieurs couches de neurones entre les entrées et les sorties du réseau. Ces multiples couches permettent d’extraire progressivement des caractéristiques de haut niveau à partir des données brutes. Par exemple, en traitement d’images , les couches inférieures peuvent identifier les contours, tandis que les couches supérieures peuvent identifier les concepts pertinents pour un être humain, tels que les chiffres, les lettres ou les visages.
L'apprentissage profond a considérablement amélioré les performances des programmes dans de nombreux sous-domaines importants de l'intelligence artificielle, notamment la vision par ordinateur , la reconnaissance vocale , le traitement automatique du langage naturel , la classification d'images et bien d'autres. Les raisons de ces excellentes performances restent inconnues en 2021 Le succès fulgurant de l'apprentissage profond entre 2012 et 2015 ne s'explique pas par une découverte majeure ou une avancée théorique (les réseaux neuronaux profonds et la rétropropagation avaient été décrits dès les années 1950) , mais par deux facteurs : l'augmentation de la puissance de calcul (notamment la multiplication par cent de la vitesse grâce aux GPU ) et la disponibilité de vastes quantités de données d'entraînement, en particulier les immenses ensembles de données organisés utilisés pour les tests de performance, tels qu'ImageNet .
GPT
Les transformateurs génératifs pré-entraînés (GPT) sont des modèles de langage de grande taille (LLM) qui génèrent du texte à partir des relations sémantiques entre les mots dans les phrases. Les modèles GPT textuels sont pré-entraînés sur un vaste corpus de texte provenant d'Internet. Le pré-entraînement consiste à prédire le token suivant (un token étant généralement un mot, un sous-mot ou un signe de ponctuation). Au cours de ce pré-entraînement, les modèles GPT accumulent des connaissances sur le monde et peuvent ensuite générer un texte proche du langage humain en prédisant de manière répétée le token suivant. Généralement, une phase d'entraînement ultérieure améliore la fiabilité, l'utilité et la sécurité du modèle, généralement grâce à une technique appelée apprentissage par renforcement à partir de retours humains (RLHF). Les modèles GPT actuels sont sujets à la production d'erreurs appelées « hallucinations ». Celles-ci peuvent être réduites grâce au RLHF et à des données de qualité, mais le problème s'aggrave pour les systèmes de raisonnement. Ces systèmes sont utilisés dans les chatbots , qui permettent aux utilisateurs de poser une question ou de demander une tâche par écrit.
Les modèles et services actuels incluent ChatGPT , Claude , Gemini , Copilot et Meta AI . Les modèles GPT multimodaux peuvent traiter différents types de données ( modalités ) tels que des images, des vidéos, du son et du texte.
Matériel et logiciel
À la fin des années 2010, les unités de traitement graphique (GPU), de plus en plus conçues avec des améliorations spécifiques à l'IA et utilisées avec le logiciel spécialisé TensorFlow, ont remplacé les unités centrales de traitement (CPU) comme principal moyen d'entraînement des modèles d' apprentissage automatique à grande échelle (commerciaux et académiques) . Des langages de programmation spécialisés tels que Prolog ont été utilisés dans les premières recherches en IA, mais les langages de programmation généralistes comme Python sont devenus prédominants.
On a observé que la densité des transistors dans les circuits intégrés double environ tous les 18 mois – une tendance connue sous le nom de loi de Moore , du nom du cofondateur d'Intel, Gordon Moore , qui l'a identifiée pour la première fois. Les améliorations apportées aux GPU ont été encore plus rapides , une tendance parfois appelée loi de Huang , du nom du cofondateur et PDG de Nvidia , Jensen Huang .
Applications
L’intelligence artificielle et les technologies d’apprentissage automatique sont utilisées dans la plupart des applications essentielles des années 2020, notamment :
- moteurs de recherche (tels que Google Search )
- Ciblage publicitaire en ligne
- Les systèmes de recommandation (proposés par Netflix , YouTube ou Amazon ) génèrent du trafic internet
- publicité ciblée ( AdSense , Facebook )
- assistants virtuels (tels que Siri ou Alexa )
- véhicules autonomes (y compris les drones , les systèmes ADAS et les voitures autonomes )
- Traduction automatique ( Microsoft Translator , Google Translate )
- reconnaissance faciale ( Face ID d' Apple , DeepFace de Microsoft et FaceNet de Google )
- Étiquetage des images (utilisé par Facebook, Photos d'Apple et TikTok ).
Le déploiement de l'IA peut être supervisé par un responsable de l'automatisation (CAO).
Développement de logiciels assisté par l'IA
L'IA est de plus en plus utilisée dans le diagnostic médical, notamment pour la détection de maladies telles que le cancer du poumon à partir d'imagerie médicale comme les tomodensitométries .
Un article de 2026 paru dans Nature et intitulé « Des dizaines de modèles d’IA de prédiction des maladies ont été entraînés sur des données douteuses » a mis en lumière l’utilisation de données peu fiables pour entraîner des modèles d’IA de prédiction médicale pour les AVC et le diabète dans 125 articles de recherche. Des éléments suggèrent que certains des outils d’IA développés à partir de données peu fiables ont été utilisés sur des patients, sans qu’il soit possible de déterminer s’il y a eu des conséquences néfastes.
Jeux
Mathematics
Lorsque le langage naturel est utilisé pour décrire des problèmes mathématiques, des convertisseurs peuvent transformer ces instructions en un langage formel tel que Lean afin de définir les tâches mathématiques. Le modèle expérimental Gemini Deep Think accepte directement les instructions en langage naturel et a obtenu la médaille d'or aux Olympiades internationales de mathématiques de 2025.
L'apprentissage profond topologique intègre diverses approches topologiques .
Finance
Selon Nicolas Firzli, directeur du Forum mondial des pensions et des investissements , il est peut-être prématuré d’envisager l’émergence de produits et services financiers hautement innovants s’appuyant sur l’IA. Il soutient que « le déploiement d’outils d’IA ne fera qu’automatiser davantage les processus, détruisant au passage des dizaines de milliers d’emplois dans les secteurs bancaire, de la planification financière et du conseil en matière de retraite. Je ne suis pas certain, en revanche, qu’il engendrera une nouvelle vague d’innovations [par exemple, sophistiquées] dans le domaine des retraites. »
Militaire
L’IA a été utilisée dans des opérations militaires en Irak, en Syrie, en Israël et en Ukraine.
IA générative
La prévalence des outils d'IA générative a considérablement augmenté depuis l' essor de l'IA dans les années 2020. Cet essor a été rendu possible par les améliorations apportées aux réseaux neuronaux profonds , en particulier aux grands modèles de langage (LLM), basés sur l' architecture Transformer . Parmi les applications d'IA générative, on trouve des chatbots tels que ChatGPT , Claude , Copilot , DeepSeek , Doubao , Google Gemini , Grok et Qwen ; des modèles de conversion texte-image tels que DALL-E , Firefly , Stable Diffusion et Midjourney ; et des modèles de conversion texte-vidéo tels que Veo , LTX et Sora .
Des entreprises de divers secteurs ont utilisé l'IA générative, notamment dans le développement de logiciels, la santé, la finance, le divertissement, le service client, les ventes et le marketing, l'art, l'écriture, et la conception de produits.
Agents
Recherche Web
Microsoft a lancé Copilot Search en février 2023 sous le nom de Bing Chat . Copilot Search fournit des résumés générés par l'IA.
Google a présenté un mode IA lors de son événement Google I/O le 20 mai 2025.
Sexualité
Les applications de l'IA dans ce domaine comprennent des applications de suivi des menstruations et de la fertilité qui analysent les données des utilisatrices pour proposer des prédictions , des sextoys intégrant l'IA (par exemple, la télédildonique ) , des contenus d'éducation sexuelle générés par l'IA et des agents virtuels qui simulent des partenaires sexuels et romantiques (par exemple, Replika ) . L'IA est également utilisée pour la production de vidéos pornographiques truquées (deepfakes) non consensuelles , soulevant d'importantes questions éthiques et juridiques
Les technologies d’IA ont également été utilisées pour tenter d’identifier la violence en ligne fondée sur le genre et le harcèlement sexuel en ligne des mineurs.
Autres tâches spécifiques à l'industrie
Dans une enquête de 2017, une entreprise sur cinq a déclaré avoir intégré l’« IA » dans certaines de ses offres ou processus.
Dans le domaine de l'évacuation et de la gestion des catastrophes , l'IA a été utilisée pour étudier les tendances des évacuations à grande et petite échelle à partir de données historiques provenant du GPS, de vidéos ou des médias sociaux.
Lors des élections indiennes de 2024 , 50 millions de dollars américains ont été dépensés en contenu autorisé généré par l'IA, notamment en créant des deepfakes de politiciens alliés (y compris parfois décédés) pour mieux interagir avec les électeurs, et en traduisant des discours dans diverses langues locales.
L’utilisation de l’IA générative par les cabinets d’avocats pour la recherche juridique a conduit à la création, en avril 2025, de la base de données mondiale « Affaires d’hallucinations générées par l’IA », établie par Damien Charlotin, maître de conférences en analyse de données juridiques à HEC Paris et Sciences Po . Dès 2026, des juges ont prononcé des sanctions et des ordres des avocats ont émis des avertissements suite à la présentation, par des avocats, de citations de jurisprudence fabriquées de toutes pièces et générées par des outils d’IA.
L’IA présente des avantages et des risques potentiels. Elle pourrait faire progresser la science et trouver des solutions à des problèmes importants : Demis Hassabis, de DeepMind, espère « résoudre le problème de l’intelligence, puis l’utiliser pour résoudre tous les autres problèmes ». Cependant, la généralisation de l’IA a mis en évidence plusieurs conséquences et risques imprévus. Les systèmes en production ne prennent parfois pas en compte l’éthique et les biais dans leurs processus d’apprentissage, notamment lorsque les algorithmes d’IA sont intrinsèquement inexplicables dans le cadre de l’apprentissage profond.
Risques et dommages
Confidentialité et droits d'auteur
Les appareils et services basés sur l'IA, tels que les assistants virtuels et les objets connectés, collectent en permanence des informations personnelles, soulevant des inquiétudes quant à la collecte intrusive de données et aux accès non autorisés par des tiers. La perte de confidentialité est encore aggravée par la capacité de l'IA à traiter et combiner d'immenses quantités de données, ce qui pourrait mener à une société de surveillance où les activités individuelles sont constamment surveillées et analysées sans garanties ni transparence suffisantes.
Les données sensibles collectées peuvent inclure l'historique d'activité en ligne, les données de géolocalisation, les enregistrements vidéo ou audio. Par exemple, pour développer des algorithmes de reconnaissance vocale , Amazon a enregistré des millions de conversations privées et a autorisé des travailleurs temporaires à en écouter et à en transcrire certaines. Les opinions sur cette surveillance généralisée divergent : certains la considèrent comme un mal nécessaire, tandis que d'autres la jugent clairement contraire à l'éthique et constituant une violation du droit à la vie privée .
Les développeurs d'IA affirment que c'est le seul moyen de proposer des applications utiles et ont mis au point plusieurs techniques visant à préserver la vie privée tout en collectant les données, telles que l'agrégation de données , l'anonymisation et la confidentialité différentielle . Depuis 2016, certains experts en protection de la vie privée, comme Cynthia Dwork , ont commencé à envisager la protection de la vie privée sous l'angle de l'équité . Brian Christian a écrit que les experts sont passés « de la question de "ce qu'ils savent" à celle de "ce qu'ils en font" ».
L'intelligence artificielle générative est souvent entraînée sur des œuvres protégées par le droit d'auteur non autorisées, notamment dans des domaines tels que les images ou le code informatique ; le résultat est ensuite utilisé au nom du « fair use » (utilisation équitable). Les experts divergent quant à la validité de cette justification devant les tribunaux et aux circonstances dans lesquelles elle s'applique ; parmi les facteurs pertinents figurent « la finalité et la nature de l'utilisation de l'œuvre protégée » et « l'impact sur le marché potentiel de l'œuvre protégée ». Les propriétaires de sites web peuvent indiquer qu'ils ne souhaitent pas que leur contenu soit aspiré via un fichier « robots.txt ». Cependant, certaines entreprises aspirent le contenu malgré tout , car le fichier robots.txt n'a aucune valeur juridique réelle. En 2023, des auteurs de renom (dont John Grisham et Jonathan Franzen ) ont intenté des poursuites contre des entreprises spécialisées en IA pour avoir utilisé leurs travaux afin d'entraîner des IA génératives. Une autre approche envisagée consiste à concevoir un système de protection sui generis distinct pour les créations générées par l'IA afin de garantir une attribution et une rémunération équitables aux auteurs humains.
Domination des géants de la technologie
Le marché de l'IA commerciale est dominé par les géants de la tech tels qu'Alphabet Inc. , Amazon , Apple Inc. , Meta Platforms et Microsoft . Certains de ces acteurs possèdent déjà la grande majorité des infrastructures cloud et de la puissance de calcul des centres de données , ce qui leur permet de renforcer leur position sur le marché.
besoins énergétiques et impacts environnementaux
Les entreprises technologiques ont construit des infrastructures d'électricité et d'intelligence artificielle pour faciliter l'essor de l'IA dans les années 2020. Un rapport de 2025 du cabinet de conseil McKinsey & Company estimait que d'ici 2030, 2 700 milliards de dollars seraient investis dans les infrastructures d'IA et les centres de données aux États-Unis, dépassant ainsi chaque mois le budget du projet Manhattan pendant la Seconde Guerre mondiale .
En janvier 2024, l’ Agence internationale de l’énergie (AIE) a publié le rapport « Électricité 2024 : Analyse et prévisions jusqu’en 2026 » . Il s’agit du premier rapport de l’AIE à formuler des projections concernant les centres de données et la consommation d’énergie liée à l’IA et aux cryptomonnaies. Le rapport indique que la demande en électricité pour ces usages pourrait doubler d’ici 2026, la consommation supplémentaire étant équivalente à celle du Japon
La consommation d'énergie liée à l'IA est responsable d'une augmentation de la consommation de combustibles fossiles et a retardé la fermeture des centrales à charbon obsolètes et polluantes. Une recherche ChatGPT consomme dix fois plus d'énergie électrique qu'une recherche Google.
Une étude de Goldman Sachs de 2024, intitulée « Centres de données IA et forte augmentation de la demande d'électricité aux États-Unis » , conclut que « la demande d'électricité aux États-Unis devrait connaître une croissance inédite depuis une génération… » et prévoit que, d'ici 2030, les centres de données américains consommeront 8 % de l'électricité du pays, contre 3 % en 2022, ce qui augure d'une croissance du secteur de la production d'électricité par divers moyens. Les besoins croissants en électricité des centres de données sont tels qu'ils pourraient saturer le réseau électrique. Les géants de la tech rétorquent que l'IA peut être utilisée pour optimiser l'utilisation du réseau par tous.
En 2024, le Wall Street Journal a rapporté que de grandes entreprises spécialisées dans l'IA avaient entamé des négociations avec des fournisseurs d'énergie nucléaire américains pour alimenter leurs centres de données. En mars 2024, Amazon a acquis un centre de données alimenté par une centrale nucléaire en Pennsylvanie pour 650 millions de dollars américains.
En septembre 2024, Microsoft a annoncé un accord avec Constellation Energy pour la réouverture de la centrale nucléaire de Three Mile Island. Cet accord prévoit que Microsoft bénéficiera de 100 % de l'électricité produite par la centrale pendant 20 ans. La réouverture de la centrale, qui a subi une fusion partielle du cœur de son réacteur n° 2 en 1979, obligera Constellation à se soumettre à des procédures réglementaires rigoureuses, notamment un examen approfondi de la sécurité par la Commission de réglementation nucléaire des États-Unis (NRC). Si le projet est approuvé (il s'agira de la toute première remise en service d'une centrale nucléaire aux États-Unis), plus de 835 mégawatts d'électricité seront produits, soit l'équivalent de la consommation de 800 000 foyers. Le coût de la réouverture et de la modernisation est estimé à 1,6 milliard de dollars américains et dépend des allégements fiscaux accordés à l'énergie nucléaire par la loi américaine de 2022 sur la réduction de l'inflation . En 2024, le gouvernement américain et l'État du Michigan avaient investi près de 2 milliards de dollars américains dans la réouverture du réacteur nucléaire de Palisades, situé sur le lac Michigan. Fermée depuis 2022, l'usine devait rouvrir en octobre 2025.
Après la dernière autorisation accordée en septembre 2023, Taïwan a suspendu en 2024 l'approbation des centres de données situés au nord de Taoyuan d'une capacité supérieure à 5 MW, en raison de pénuries d'électricité. Taïwan vise à abandonner progressivement l'énergie nucléaire d'ici 2025.
Singapour a imposé une interdiction d'ouverture de centres de données en 2019 en raison de problèmes d'approvisionnement en électricité, mais a levé cette interdiction en 2022.
Bien que la plupart des centrales nucléaires du Japon aient été fermées après l' accident nucléaire de Fukushima en 2011 , selon un article de Bloomberg en japonais d'octobre 2024, la société de services de jeux en nuage Ubitus, dans laquelle Nvidia détient une participation, recherche un terrain au Japon près d'une centrale nucléaire pour un nouveau centre de données pour l'IA générative.
Le 1er novembre 2024, la Commission fédérale de régulation de l'énergie (FERC) a rejeté la demande de Talen Energy visant à fournir une partie de l'électricité produite par la centrale nucléaire de Susquehanna au centre de données d'Amazon. Selon le président de la Commission, Willie L. Phillips , cette demande représente une charge pour le réseau électrique et un important transfert de coûts vers les ménages et d'autres secteurs d'activité.
En 2025, un rapport de l'AIE estimait à 180 millions de tonnes les émissions de gaz à effet de serre liées à la consommation énergétique de l'IA. D'ici 2035, ces émissions pourraient atteindre 300 à 500 millions de tonnes, selon les mesures prises. Cela représente moins de 1,5 % des émissions du secteur énergétique. Le potentiel de réduction des émissions de l'IA était estimé à 5 % des émissions du secteur énergétique, mais des effets rebond (par exemple, un report des usagers des transports en commun vers les véhicules autonomes) pourraient le réduire.
Désinformation
Au début des années 2020, l'IA générative a commencé à créer des images, des fichiers audio et des textes pratiquement indiscernables de photographies, d'enregistrements ou d'écrits humains authentiques , tandis que la production de vidéos réalistes par l'IA est devenue possible au milieu des années 2020 Des personnes mal intentionnées peuvent utiliser cette technologie pour diffuser massivement de la désinformation et de la propagande numérique grâce à des techniques telles que les deepfakes . Geoffrey Hinton, pionnier de l'IA et lauréat du prix Nobel d'informatique, s'est inquiété de la possibilité que l'IA permette aux dirigeants autoritaires de manipuler leurs électeurs à grande échelle, parmi d'autres risques . La capacité d'influencer les électeurs a été démontrée dans au moins une étude. Cette même étude montre que les modèles produisent davantage de déclarations inexactes lorsqu'ils soutiennent des candidats de droite
Des chercheurs en IA chez Microsoft , OpenAI , dans des universités et d'autres organisations ont suggéré d'utiliser des « justificatifs de personnalité » comme moyen de surmonter la tromperie en ligne permise par les modèles d'IA.
Biais algorithmiques et équité
Le 28 juin 2015, la nouvelle fonctionnalité d'étiquetage d'images de Google Photos a identifié par erreur Jacky Alcine et une amie comme des « gorilles » en raison de leur couleur de peau. Le système avait été entraîné sur un ensemble de données contenant très peu d'images de personnes noires , un problème appelé « disparité de taille d'échantillon » . Google a « corrigé » ce problème en empêchant le système d'étiqueter quoi que ce soit comme « gorille ». Huit ans plus tard, en 2023, Google Photos était toujours incapable d'identifier un gorille, tout comme les produits similaires d'Apple, Facebook, Microsoft et Amazon
COMPAS est un logiciel commercial largement utilisé par les tribunaux américains pour évaluer la probabilité de récidive d' un prévenu . En 2016, Julia Angwin, de ProPublica, a découvert que COMPAS présentait un biais racial, bien que le programme ne soit pas informé de l'origine ethnique des prévenus. Si le taux d'erreur pour les Blancs et les Noirs était calibré à 61 %, les erreurs différaient selon l'origine ethnique : le système surestimait systématiquement la probabilité de récidive chez les Noirs et sous-estimait celle des Blancs. En 2017, plusieurs chercheurs ont démontré qu'il était mathématiquement impossible pour COMPAS de prendre en compte tous les critères d'équité lorsque les taux de récidive de base différaient entre les Blancs et les Noirs dans les données.
Un programme peut prendre des décisions biaisées même si les données ne mentionnent pas explicitement une caractéristique problématique (comme la « race » ou le « sexe »). Cette caractéristique sera corrélée à d’autres (comme l’« adresse », l’« historique d’achats » ou le « prénom »), et le programme prendra les mêmes décisions en se basant sur ces caractéristiques que sur la « race » ou le « sexe ». Moritz Hardt a déclaré : « Le fait le plus incontestable dans ce domaine de recherche est que l’équité par l’aveuglement ne fonctionne pas. »
Les critiques formulées à l'encontre de COMPAS ont mis en lumière le fait que les modèles d'apprentissage automatique sont conçus pour formuler des « prédictions » qui ne sont valides que si l'on suppose que l'avenir ressemblera au passé. S'ils sont entraînés sur des données incluant les conséquences de décisions racistes passées, ces modèles prédisent nécessairement que des décisions racistes seront prises à l'avenir. Si une application utilise ensuite ces prédictions comme recommandations , certaines de ces « recommandations » seront vraisemblablement racistes. Ainsi, l'apprentissage automatique est mal adapté à la prise de décision dans des domaines où l'on peut espérer un avenir meilleur . Il est descriptif plutôt que prescriptif.
Les préjugés et les injustices peuvent passer inaperçus parce que les développeurs sont majoritairement blancs et masculins : parmi les ingénieurs en IA, environ 4 % sont noirs et 20 % sont des femmes.
Il existe diverses définitions et modèles mathématiques de l'équité, souvent contradictoires. Ces notions reposent sur des hypothèses éthiques et sont influencées par des conceptions de la société. L'une des grandes catégories est l'équité distributive , qui se concentre sur les résultats, identifiant généralement des groupes et cherchant à compenser les disparités statistiques. L'équité représentationnelle vise à garantir que les systèmes d'IA ne renforcent pas les stéréotypes négatifs ni ne rendent certains groupes invisibles. L'équité procédurale, quant à elle, se concentre sur le processus de décision plutôt que sur le résultat. Les notions d'équité les plus pertinentes peuvent dépendre du contexte, notamment du type d'application d'IA et des parties prenantes. La subjectivité inhérente aux notions de biais et d'équité rend leur mise en œuvre difficile pour les entreprises. L'accès à des attributs sensibles tels que l'origine ethnique ou le sexe est également considéré par de nombreux spécialistes de l'éthique de l'IA comme nécessaire pour compenser les biais, mais cela peut entrer en conflit avec les lois antidiscrimination .
Lors de la conférence ACM 2022 sur l'équité, la responsabilité et la transparence, un article a révélé qu'un système robotique basé sur la méthode CLIP ( pré-entraînement contrastif langage-image ) reproduisait des stéréotypes néfastes liés au genre et à l'origine ethnique dans une tâche de manipulation simulée. Les auteurs ont recommandé que les méthodes d'apprentissage robotique qui manifestent physiquement de tels préjudices soient « suspendues, retravaillées, voire abandonnées le cas échéant, jusqu'à ce que leurs résultats soient prouvés sûrs, efficaces et justes ».
Manque de transparence
Il est impossible d'être certain du bon fonctionnement d'un programme si l'on ignore son fonctionnement exact. De nombreux cas montrent qu'un programme d'apprentissage automatique, malgré des tests rigoureux, a appris des choses différentes de celles prévues par les programmeurs. Par exemple, un système capable d'identifier les maladies de la peau mieux que les professionnels de santé s'est avéré avoir une forte tendance à classer comme « cancéreuses » les images comportant une règle , car les photos de tumeurs malignes incluent généralement une règle pour indiquer l'échelle. Un autre système d'apprentissage automatique, conçu pour optimiser l'allocation des ressources médicales, a classé les patients asthmatiques comme présentant un « faible risque » de décès par pneumonie. L'asthme constitue en réalité un facteur de risque important, mais comme les patients asthmatiques bénéficient généralement de soins médicaux plus intensifs, leur risque de décès était relativement faible selon les données d'entraînement. La corrélation entre l'asthme et un faible risque de décès par pneumonie était réelle, mais trompeuse.
Les personnes lésées par la décision d'un algorithme ont droit à une explication. Les médecins, par exemple, sont tenus d'expliquer clairement et complètement à leurs confrères le raisonnement qui sous-tend chaque décision prise. Les premières versions du Règlement général sur la protection des données (RGPD) de l'Union européenne , en 2016, mentionnaient explicitement l'existence de ce droit. Les experts du secteur ont souligné qu'il s'agit d'un problème non résolu, sans solution en vue. Les autorités de régulation ont néanmoins fait valoir que le préjudice est réel : si le problème est insoluble, ces outils ne devraient pas être utilisés.
La DARPA a créé le programme XAI (« Intelligence artificielle explicable ») en 2014 pour tenter de résoudre ces problèmes.
Plusieurs approches visent à résoudre le problème de transparence. SHAP permet de visualiser la contribution de chaque caractéristique à la sortie. LIME peut approximer localement les sorties d'un modèle par un modèle plus simple et interprétable. L'apprentissage multitâche fournit un grand nombre de sorties en plus de la classification cible. Ces autres sorties peuvent aider les développeurs à déduire ce que le réseau a appris. La déconvolution , DeepDream et d'autres méthodes génératives permettent aux développeurs de voir ce que les différentes couches d'un réseau profond de vision par ordinateur ont appris et de produire une sortie qui peut suggérer ce que le réseau est en train d'apprendre. Pour les transformateurs pré-entraînés génératifs , Anthropic a développé une technique basée sur l'apprentissage de dictionnaires qui associe des schémas d'activation neuronale à des concepts compréhensibles par l'humain.
Acteurs malveillants et IA militarisée
Une arme autonome létale est une machine qui localise, sélectionne et engage des cibles humaines sans supervision humaine. Des outils d'IA largement disponibles peuvent être utilisés par des acteurs malveillants pour développer des armes autonomes peu coûteuses et, si elles sont produites à grande échelle, elles pourraient potentiellement devenir des armes de destruction massive . Même utilisées dans le cadre d'une guerre conventionnelle, elles ne peuvent actuellement pas choisir leurs cibles de manière fiable et pourraient potentiellement tuer une personne innocente . En 2014, 30 pays (dont la Chine) ont soutenu l'interdiction des armes autonomes en vertu de la Convention des Nations Unies sur certaines armes classiques , mais les États-Unis et d'autres pays s'y sont opposés. En 2015, plus de cinquante pays menaient des recherches sur les robots de combat.
Les outils d'IA facilitent le contrôle des citoyens par les gouvernements autoritaires de plusieurs manières. La reconnaissance faciale et vocale permet une surveillance généralisée . L'apprentissage automatique , exploitant ces données, peut identifier les ennemis potentiels de l'État et les empêcher de se dissimuler. Les systèmes de recommandation peuvent cibler précisément la propagande et la désinformation pour un impact maximal. Les deepfakes et l'IA générative contribuent à la production de désinformation. L'IA avancée peut rendre la prise de décision centralisée autoritaire plus compétitive que les systèmes libéraux et décentralisés tels que les marchés . Elle réduit le coût et la complexité de la guerre numérique et des logiciels espions sophistiqués . Toutes ces technologies sont disponibles depuis 2020, voire avant ; les systèmes de reconnaissance faciale par IA sont déjà utilisés pour la surveillance de masse en Chine.
L’IA pourrait aider les personnes mal intentionnées de bien d’autres manières, dont certaines sont imprévisibles. Par exemple, l’IA d’apprentissage automatique est capable de concevoir des dizaines de milliers de molécules toxiques en quelques heures.
chômage technologique
Contrairement aux précédentes vagues d'automatisation, de nombreux emplois de la classe moyenne pourraient être supprimés par l'intelligence artificielle. En 2015, The Economist affirmait que « la crainte que l'IA puisse faire aux emplois de cols blancs ce que la machine à vapeur a fait aux emplois de cols bleus pendant la révolution industrielle » est « à prendre au sérieux » . Parmi les emplois les plus menacés figurent ceux d'assistant juridique et de cuisinier de restauration rapide, tandis que la demande devrait augmenter pour les professions liées aux soins, des soins à domicile au clergé . En juillet 2025, Jim Farley, PDG de Ford, prédisait que « l'intelligence artificielle va remplacer littéralement la moitié des cols blancs aux États-Unis »
Dès les débuts du développement de l'intelligence artificielle, des arguments ont été avancés, par exemple ceux présentés par Joseph Weizenbaum , sur la question de savoir si les tâches qui peuvent être effectuées par les ordinateurs devraient réellement être effectuées par eux, compte tenu de la différence entre les ordinateurs et les humains, et entre le calcul quantitatif et le jugement qualitatif fondé sur des valeurs.
Substitution à l'interaction humaine
Risque existentiel
Premièrement, l'IA n'a pas besoin d' une conscience semblable à celle de l'humain pour constituer un risque existentiel. Les programmes d'IA modernes se voient attribuer des objectifs précis et utilisent l'apprentissage et l'intelligence pour les atteindre. Le philosophe Nick Bostrom a soutenu que si l'on confie presque n'importe quel objectif à une IA suffisamment puissante, celle-ci pourrait choisir de détruire l'humanité pour l'atteindre (il a cité l'exemple d'une usine automatisée de trombones qui détruit le monde pour obtenir davantage de fer destiné à la fabrication de trombones). Stuart Russell donne l'exemple d'un robot domestique qui tente de trouver un moyen de tuer son propriétaire pour empêcher qu'il ne soit débranché, en raisonnant ainsi : « On ne peut pas aller chercher le café si on est mort. » Pour être sans danger pour l'humanité, une superintelligence devrait être véritablement alignée sur la morale et les valeurs humaines, de sorte qu'elle soit « fondamentalement de notre côté. »
Deuxièmement, Yuval Noah Harari soutient que l'IA n'a pas besoin d'un corps robotique ni d'un contrôle physique pour représenter un risque existentiel. Les fondements de la civilisation ne sont pas physiques. Des concepts tels que les idéologies , le droit , le gouvernement , la monnaie et l' économie reposent sur le langage ; ils existent grâce aux récits auxquels croient des milliards de personnes. La prévalence actuelle de la désinformation laisse penser qu'une IA pourrait utiliser le langage pour convaincre les gens de croire n'importe quoi, voire de commettre des actes destructeurs. Geoffrey Hinton affirmait en 2025 que l'IA moderne est particulièrement « douée pour la persuasion » et que ses capacités ne cessent de s'améliorer. Il pose la question suivante : « Imaginez que vous vouliez envahir la capitale des États-Unis. Devez-vous vous y rendre et le faire vous-même ? Non. Il suffit d'être doué pour la persuasion. »
Les opinions des experts et des acteurs du secteur sont partagées, une part importante d'entre eux étant à la fois préoccupée et indifférente aux risques liés à une éventuelle IA superintelligente. Des personnalités telles que Stephen Hawking, Bill Gates et Elon Musk , ainsi que des pionniers de l'IA comme Geoffrey Hinton , Yoshua Bengio , Stuart Russell , Demis Hassabis et Sam Altman , ont exprimé des inquiétudes quant aux risques existentiels que représente l'IA.
En mai 2023, Geoffrey Hinton a annoncé sa démission de Google afin de pouvoir « s’exprimer librement sur les risques liés à l’IA » sans « se soucier des répercussions sur Google ». Il a notamment évoqué les risques d’une prise de contrôle par l’IA [ pour éviter le pire, l’établissement de lignes directrices en matière de sécurité nécessiterait une coopération entre les acteurs concurrents dans le domaine de l’IA.
En 2023, de nombreux experts de premier plan en IA ont approuvé la déclaration commune selon laquelle « Atténuer le risque d’extinction dû à l’IA devrait être une priorité mondiale au même titre que d’autres risques à l’échelle de la société tels que les pandémies et la guerre nucléaire ».
D'autres chercheurs se montraient plus optimistes. Jürgen Schmidhuber, pionnier de l'IA , n'a pas signé la déclaration commune, soulignant que dans 95 % des cas, la recherche en IA vise à rendre « la vie humaine plus longue, plus saine et plus facile » Si les outils actuellement utilisés pour améliorer nos vies peuvent aussi être détournés par des personnes mal intentionnées, « ils peuvent également être utilisés contre elles » Andrew Ng a également affirmé qu'« il est erroné de céder au discours apocalyptique sur l'IA, et que les régulateurs qui le font ne serviront que les intérêts particuliers » . Yann LeCun , lauréat du prix Turing, a réfuté l'idée que l'IA subordonnerait les humains « simplement parce qu'elle est plus intelligente, et encore moins qu'elle [nous] détruirait » , « raillant les scénarios dystopiques de ses pairs, qui prévoyaient une désinformation massive et, à terme, l'extinction de l'humanité ». En revanche, il affirmait que « les machines intelligentes inaugureront une nouvelle renaissance pour l’humanité, une nouvelle ère des Lumières » . Au début des années 2010, des experts estimaient que les risques étaient trop lointains pour justifier des recherches ou que les humains n’auraient aucune valeur du point de vue d’une machine superintelligente . Toutefois, après 2016, l’étude des risques actuels et futurs ainsi que des solutions possibles est devenue un axe de recherche important
Machines éthiques et alignement
Les machines dotées d'intelligence ont le potentiel d'utiliser cette intelligence pour prendre des décisions éthiques. Le domaine de l'éthique des machines fournit aux machines des principes et des procédures éthiques pour résoudre les dilemmes éthiques. Ce domaine est également appelé moralité computationnelle, et a été fondé lors d'un symposium de l'AAAI en 2005.
D'autres approches incluent les « agents moraux artificiels » de Wendell Wallach et les trois principes de Stuart J. Russell pour développer des machines dont les bienfaits sont prouvés.
Source libre
Cadres
Les projets d’intelligence artificielle peuvent être guidés par des considérations éthiques lors de la conception, du développement et de la mise en œuvre d’un système d’IA. Un cadre d’IA tel que le Care and Act Framework, développé par l’ Institut Alan Turing et basé sur les valeurs SUM, décrit quatre grandes dimensions éthiques, définies comme suit :
- Respectez la dignité de chaque individu.
- Établissez des liens avec les autres de manière sincère, ouverte et inclusive.
- Prendre soin du bien-être de tous
- Protéger les valeurs sociales, la justice et l'intérêt public
D'autres développements dans les cadres éthiques comprennent ceux décidés lors de la Conférence d'Asilomar , la Déclaration de Montréal pour une IA responsable et l'initiative de l'IEEE sur l'éthique des systèmes autonomes, entre autres ; cependant, ces principes ne sont pas sans critique, notamment en ce qui concerne les personnes choisies pour contribuer à ces cadres.
La promotion du bien-être des personnes et des communautés que ces technologies affectent nécessite la prise en compte des implications sociales et éthiques à toutes les étapes de la conception, du développement et de la mise en œuvre des systèmes d'IA, ainsi que la collaboration entre les différents rôles professionnels tels que les scientifiques des données, les gestionnaires de produits, les ingénieurs de données, les experts du domaine et les gestionnaires de livraison.
L’ Institut britannique de sécurité de l’IA a publié en 2024 un ensemble d’outils de test appelé « Inspect » pour l’évaluation de la sécurité de l’IA. Disponible sous licence open source MIT et librement accessible sur GitHub, il peut être amélioré grâce à des modules tiers. Il permet d’évaluer les modèles d’IA dans divers domaines, notamment les connaissances fondamentales, la capacité de raisonnement et les capacités autonomes.
Règlement
La réglementation de l'intelligence artificielle (IA) consiste à élaborer des politiques et des lois du secteur public visant à promouvoir et à encadrer l'IA ; elle est donc liée à la réglementation plus générale des algorithmes. Le cadre réglementaire et politique de l'IA est un enjeu émergent à l'échelle mondiale. Selon l'AI Index de Stanford , le nombre annuel de lois relatives à l'IA adoptées dans les 127 pays étudiés est passé d'une seule en 2016 à 37 pour la seule année 2022. Entre 2016 et 2020, plus de 30 pays ont adopté des stratégies dédiées à l'IA. La plupart des États membres de l'UE ont publié des stratégies nationales en matière d'IA, tout comme le Canada , la Chine, l'Inde, le Japon, Maurice, la Fédération de Russie, l'Arabie saoudite, les Émirats arabes unis, les États-Unis et le Vietnam. D'autres pays, dont le Bangladesh, la Malaisie et la Tunisie, étaient en train d'élaborer leur propre stratégie. Le Partenariat mondial sur l'intelligence artificielle a été lancé en juin 2020, soulignant la nécessité de développer l'IA dans le respect des droits humains et des valeurs démocratiques, afin de garantir la confiance du public dans cette technologie. Henry Kissinger , Eric Schmidt et Daniel Huttenlocher ont publié une déclaration commune en novembre 2021 appelant à la création d'une commission gouvernementale chargée de réglementer l'IA. En 2023, les dirigeants d'OpenAI ont publié des recommandations concernant la gouvernance de la superintelligence, qu'ils estiment pouvoir mettre en place d'ici moins de dix ans. En 2023, les Nations Unies ont également créé un organe consultatif chargé de formuler des recommandations sur la gouvernance de l'IA ; cet organe est composé de dirigeants d'entreprises technologiques, de représentants gouvernementaux et d'universitaires. Le 1er août 2024, la loi européenne sur l'intelligence artificielle est entrée en vigueur, instaurant la première réglementation européenne complète en matière d'IA. En 2024, le Conseil de l’Europe a créé le premier traité international juridiquement contraignant sur l’IA, intitulé « Convention-cadre sur l’intelligence artificielle et les droits de l’homme, la démocratie et l’état de droit ». Il a été adopté par l’Union européenne, les États-Unis, le Royaume-Uni et d’autres signataires.
In a 2022 Ipsos survey, attitudes towards AI varied greatly by country; 78% of Chinese citizens, but only 35% of Americans, agreed that "products and services using AI have more benefits than drawbacks". A 2023 Reuters/Ipsos poll found that 61% of Americans agree, and 22% disagree, that AI poses risks to humanity. In a 2023 Fox News poll, 35% of Americans thought it "very important", and an additional 41% thought it "somewhat important", for the federal government to regulate AI, versus 13% responding "not very important" and 8% responding "not at all important".
In November 2023, the first global AI Safety Summit was held in Bletchley Park in the UK to discuss the near and far term risks of AI and the possibility of mandatory and voluntary regulatory frameworks. 28 countries including the United States, China, and the European Union issued a declaration at the start of the summit, calling for international co-operation to manage the challenges and risks of artificial intelligence. In May 2024 at the AI Seoul Summit, 16 global AI tech companies agreed to safety commitments on the development of AI.
In March 2026, the United Nations convened the inaugural meeting of the Independent International Scientific Panel on AI, a 40-member expert body established under the Global Digital Compact to produce annual evidence-based reports on AI's societal impacts.
History
L'étude du raisonnement mécanique ou « formel » a débuté avec les philosophes et les mathématiciens de l'Antiquité. L'étude de la logique a directement mené à la théorie du calcul d' Alan Turing , qui suggérait qu'une machine, en manipulant des symboles aussi simples que « 0 » et « 1 », pouvait simuler n'importe quelle forme imaginable de raisonnement mathématique. Ces travaux, conjugués aux découvertes concomitantes en cybernétique , en théorie de l'information et en neurobiologie , ont conduit les chercheurs à envisager la possibilité de construire un « cerveau électronique ». Ils ont développé plusieurs axes de recherche qui allaient devenir des composantes de l'IA, tels que le projet de « neurones artificiels » de McCulloch et Pitts en 1943, et l'article influent de Turing en 1950, « Computing Machinery and Intelligence », qui a introduit le test de Turing et démontré la plausibilité de l'« intelligence artificielle ».
Le domaine de la recherche en intelligence artificielle a été fondé lors d'un atelier au Dartmouth College en 1956. Le premier programme d'IA, Logic Theorist , a été présenté lors de cet atelier. Il a été créé par Allen Newell, futur lauréat du prix Turing, et Herbert A. Simon , futur lauréat du prix Nobel , en collaboration avec J.C. Shaw . Nombre de participants à l'atelier sont devenus des figures de proue de la recherche en IA dans les années 1960. Eux et leurs étudiants ont produit des programmes que la presse a qualifiés d'« étonnants » : les ordinateurs apprenaient des stratégies aux dames , résolvaient des problèmes d'algèbre, démontraient des théorèmes logiques et parlaient anglais. Des laboratoires d'intelligence artificielle ont été créés dans plusieurs universités britanniques et américaines à la fin des années 1950 et au début des années 1960.
Dans les années 1960 et 1970, les chercheurs étaient convaincus que leurs méthodes permettraient à terme de créer une machine dotée d' une intelligence générale et considéraient cela comme l'objectif de leur discipline. En 1965, Herbert Simon prédisait que « d'ici vingt ans, les machines seront capables d'effectuer n'importe quel travail qu'un homme peut faire ». En 1967, Marvin Minsky partageait cet avis, écrivant que « d'ici une génération … le problème de la création d'une "intelligence artificielle" sera en grande partie résolu ». Ils avaient cependant sous-estimé la difficulté du problème. En 1974, les gouvernements américain et britannique mirent fin aux recherches exploratoires suite aux critiques de Sir James Lighthill et aux pressions constantes du Congrès américain en faveur du financement de projets plus productifs . L'ouvrage de Minsky et Papert , *Perceptrons*, a été perçu comme prouvant que les réseaux de neurones artificiels ne seraient jamais utiles pour résoudre des problèmes concrets, discréditant ainsi totalement cette approche. S'en est suivi un « hiver de l'IA », période durant laquelle il était difficile d'obtenir des financements pour les projets d'IA.
Au début des années 1980, la recherche en IA a été relancée par le succès commercial des systèmes experts , une forme de programme d'IA simulant les connaissances et les capacités d'analyse des experts humains. En 1985, le marché de l'IA dépassait le milliard de dollars. Parallèlement, le projet japonais d'ordinateurs de cinquième génération a incité les gouvernements américain et britannique à rétablir le financement de la recherche universitaire . Cependant, à partir de l'effondrement du marché des machines Lisp en 1987, l'IA a de nouveau perdu de sa crédibilité, et une seconde période de déclin, plus longue, s'est amorcée
Jusqu'alors, la majeure partie des financements alloués à l'IA était consacrée à des projets utilisant des symboles de haut niveau pour représenter des objets mentaux tels que les plans, les objectifs, les croyances et les faits connus. Dans les années 1980, certains chercheurs ont commencé à douter de la capacité de cette approche à imiter l'ensemble des processus de la cognition humaine, notamment la perception , la robotique , l'apprentissage et la reconnaissance de formes , et se sont tournés vers des approches « sous-symboliques » . Rodney Brooks a rejeté la notion de « représentation » en général et s'est concentré sur la conception de machines capables de se déplacer et de survivre . Judea Pearl , Lotfi Zadeh et d'autres ont développé des méthodes permettant de traiter les informations incomplètes et incertaines en privilégiant les hypothèses raisonnables plutôt qu'une logique précise . Mais l'avancée la plus importante a été la renaissance du « connexionnisme », incluant la recherche sur les réseaux de neurones, grâce à Geoffrey Hinton et d'autres. En 1990, Yann LeCun a démontré avec succès que les réseaux neuronaux convolutifs pouvaient reconnaître des chiffres manuscrits, la première d'une longue série d'applications réussies des réseaux neuronaux.
L'IA a progressivement regagné en crédibilité à la fin des années 1990 et au début du XXIe siècle en exploitant des méthodes mathématiques formelles et en trouvant des solutions spécifiques à des problèmes précis. Cette approche « ciblée » et « formelle » a permis aux chercheurs de produire des résultats vérifiables et de collaborer avec d'autres disciplines (telles que les statistiques , l'économie et les mathématiques ) . Dès 2000, les solutions développées par les chercheurs en IA étaient largement utilisées, bien que dans les années 1990, elles fussent rarement qualifiées d'« intelligence artificielle » (une tendance connue sous le nom d'« effet IA ») . Cependant, plusieurs chercheurs universitaires se sont inquiétés du fait que l'IA ne poursuivait plus son objectif initial : créer des machines polyvalentes et pleinement intelligentes. À partir de 2002 environ, ils ont fondé le sous-domaine de l'intelligence artificielle générale (ou « IAG »), qui comptait plusieurs institutions bien financées dans les années 2010
L'apprentissage profond a commencé à dominer les benchmarks industriels en 2012 et s'est imposé dans tout le domaine. Pour de nombreuses tâches spécifiques, d'autres méthodes ont été abandonnées. Le succès de l'apprentissage profond repose à la fois sur les améliorations matérielles ( ordinateurs plus rapides , unités de traitement graphique , informatique en nuage ) et sur l'accès à de grandes quantités de données (y compris des ensembles de données organisés, tels qu'ImageNet ). Ce succès a engendré une augmentation considérable de l'intérêt et des financements consacrés à l'IA. Le volume de recherches en apprentissage automatique (mesuré par le nombre total de publications) a augmenté de 50 % entre 2015 et 2019.

En 2016, les questions d’ équité et de mésusage des technologies ont été propulsées au cœur des conférences sur l’apprentissage automatique, le nombre de publications a considérablement augmenté, des financements ont été débloqués et de nombreux chercheurs ont réorienté leur carrière vers ces problématiques. Le problème de l’alignement est devenu un champ d’étude académique à part entière.
À la fin des années 2010 et au début des années 2020, les entreprises spécialisées dans l'intelligence artificielle générale (IAG) ont commencé à proposer des programmes qui ont suscité un vif intérêt. En 2015, AlphaGo , développé par DeepMind , a vaincu le champion du monde de go . Le programme n'a appris que les règles du jeu et a élaboré une stratégie de manière autonome. GPT-3 , un vaste modèle de langage développé par OpenAI et publié en 2020, est capable de générer des textes de haute qualité, proches de ceux des humains. ChatGPT , lancé le 30 novembre 2022, est devenu l'application grand public ayant connu la croissance la plus rapide de l'histoire, avec plus de 100 millions d'utilisateurs en deux mois. Cette année a marqué ce qui est largement considéré comme l'année charnière de l'IA, la faisant entrer dans la conscience collective. Ces programmes, parmi d'autres, ont inspiré un boom spectaculaire de l'IA , les grandes entreprises investissant des milliards de dollars dans la recherche en IA. Selon AI Impacts, environ 50 milliards de dollars américains ont été investis annuellement dans l'IA aux États-Unis en 2022, et près de 20 % des nouveaux docteurs en informatique américains se sont spécialisés en IA. Environ 800 000 offres d'emploi liées à l'IA existaient aux États-Unis en 2022. D'après une étude de PitchBook, 22 % des startups nouvellement financées en 2024 se déclaraient entreprises spécialisées en IA.
Philosophie
Définition de l'intelligence artificielle

Russell et Norvig partagent l'avis de Turing selon lequel l'intelligence doit être définie en termes de comportement externe, et non de structure interne. Ils critiquent toutefois le fait que le test exige de la machine qu'elle imite les humains. « Les manuels d' ingénierie aéronautique », écrivent-ils, « ne définissent pas l'objectif de leur discipline comme la création de machines qui volent si exactement comme des pigeons qu'elles peuvent tromper d'autres pigeons. John McCarthy, fondateur de l'IA abonde dans ce sens, écrivant que « l'intelligence artificielle n'est pas, par définition, une simulation de l'intelligence humaine ».
McCarthy définit l'intelligence comme « la composante computationnelle de la capacité à atteindre des objectifs dans le monde » . Un autre pionnier de l'IA, Marvin Minsky , la décrit de la même manière comme « la capacité à résoudre des problèmes complexes » . L'ouvrage *Artificial Intelligence: A Modern Approach * la définit comme l'étude des agents qui perçoivent leur environnement et prennent des mesures maximisant leurs chances d'atteindre des objectifs définis
Les nombreuses définitions de l’IA ont fait l’objet d’une analyse critique. Durant l’essor de l’IA dans les années 2020, le terme a été utilisé comme un argument marketing pour promouvoir des produits et services qui n’utilisent pas l’IA.
Définitions juridiques
L’ Organisation internationale de normalisation (ISO) définit un système d’IA comme « un système conçu pour générer des résultats tels que du contenu, des prévisions, des recommandations ou des décisions en fonction d’un ensemble d’objectifs définis par l’humain, et pouvant fonctionner avec différents niveaux d’automatisation » . La directive européenne sur l’IA définit un système d’IA comme « un système informatisé conçu pour fonctionner avec différents niveaux d’autonomie, susceptible de s’adapter après son déploiement et qui, pour des objectifs explicites ou implicites, déduit, à partir des données qu’il reçoit, comment générer des résultats tels que des prédictions, du contenu, des recommandations ou des décisions pouvant influencer des environnements physiques ou virtuels » . Aux États-Unis, des recommandations influentes mais non contraignantes, telles que le cadre de gestion des risques liés à l’IA du National Institute of Standards and Technology (NIST), décrivent un système d’IA comme « un système conçu ou informatisé capable, pour un ensemble d’objectifs donné, de générer des résultats tels que des prédictions, des recommandations ou des décisions influençant des environnements réels ou virtuels. Les systèmes d’IA sont conçus pour fonctionner avec différents niveaux d’autonomie »
Évaluation des approches de l'IA
Aucune théorie ou paradigme unificateur établi n'a guidé la recherche en IA pendant la majeure partie de son histoire. Le succès sans précédent de l'apprentissage automatique statistique dans les années 2010 a éclipsé toutes les autres approches (à tel point que certaines sources, notamment dans le monde des affaires, utilisent le terme « intelligence artificielle » pour désigner « l'apprentissage automatique avec des réseaux de neurones »). Cette approche est principalement sous-symbolique , souple et limitée .
L'IA symbolique et ses limites
L’IA symbolique (ou « GOFAI ») simulait le raisonnement conscient de haut niveau utilisé par les humains pour résoudre des énigmes, exprimer des raisonnements juridiques et effectuer des calculs mathématiques. Elle a obtenu d’excellents résultats dans certaines tâches « intelligentes » telles que l’algèbre ou les tests de QI. En 1976, Newell et Simon ont proposé l’ hypothèse des systèmes de symboles physiques : « Un système de symboles physiques possède les moyens nécessaires et suffisants pour une action intelligente générale. »
Cependant, l'approche symbolique a échoué dans de nombreuses tâches que les humains résolvent facilement, comme l'apprentissage, la reconnaissance d'un objet ou le raisonnement de sens commun . Le paradoxe de Moravec réside dans la découverte que les tâches « intelligentes » de haut niveau étaient faciles pour l'IA, tandis que les tâches « instinctives » de bas niveau étaient extrêmement difficiles. Le philosophe Hubert Dreyfus soutenait depuis les années 1960 que l'expertise humaine repose sur l'instinct inconscient plutôt que sur la manipulation consciente de symboles, et sur une intuition de la situation plutôt que sur une connaissance symbolique explicite. Bien que ses arguments aient été ridiculisés et ignorés lors de leur présentation initiale, la recherche en IA a fini par les reconnaître.
Le problème n'est pas résolu : le raisonnement sous-symbolique peut commettre les mêmes erreurs inexplicables que l'intuition humaine, comme les biais algorithmiques . Des critiques tels que Noam Chomsky affirment que la poursuite des recherches en IA symbolique restera nécessaire pour atteindre l'intelligence générale notamment parce que l'IA sous-symbolique s'éloigne de l'IA explicable : il peut être difficile, voire impossible, de comprendre pourquoi un programme d'IA statistique moderne a pris une décision particulière. Le domaine émergent de l' intelligence artificielle neuro-symbolique tente de concilier ces deux approches.
Propre contre négligé
IA spécialisée vs. IA générale
Conscience, sensibilité et esprit des machines
Conscience
Computationalisme et fonctionnalisme
Philosopher John Searle characterized this position as "strong AI": "The appropriately programmed computer with the right inputs and outputs would thereby have a mind in exactly the same sense human beings have minds." Searle challenges this claim with his Chinese room argument, which attempts to show that even a computer capable of perfectly simulating human behavior would not have a mind.
AI welfare and rights
In 2017, the European Union considered granting "electronic personhood" to some of the most capable AI systems. Similarly to the legal status of companies, it would have conferred rights but also responsibilities. Critics argued in 2018 that granting rights to AI systems would downplay the importance of human rights, and that legislation should focus on user needs rather than speculative futuristic scenarios. They also noted that robots lacked the autonomy to take part in society on their own.
Les progrès de l'IA ont accru l'intérêt pour le sujet. Les défenseurs du bien-être et des droits des IA soutiennent souvent que la conscience des IA, si elle venait à émerger, serait particulièrement facile à nier. Ils mettent en garde contre le risque d'un angle mort moral comparable à l'esclavage ou à l'élevage industriel , susceptible d'entraîner des souffrances à grande échelle si une IA consciente était créée et exploitée sans discernement.
Avenir
Superintelligence et singularité
Une superintelligence est un agent hypothétique doté d'une intelligence surpassant largement celle des esprits humains les plus brillants et les plus doués. Si les recherches sur l'intelligence artificielle générale aboutissaient à un logiciel suffisamment intelligent, celui-ci pourrait se reprogrammer et s'améliorer . Ce logiciel amélioré serait encore plus performant pour s'améliorer lui-même, ce qui conduirait à ce que I.J. Good a appelé une « explosion d'intelligence » et Vernor Vinge une « singularité ».
Cependant, les technologies ne peuvent pas s’améliorer de façon exponentielle indéfiniment et suivent généralement une courbe en S , ralentissant lorsqu’elles atteignent les limites physiques de ce que la technologie peut faire.
transhumanisme
Edward Fredkin soutient que « l’intelligence artificielle est la prochaine étape de l’évolution », une idée proposée pour la première fois par Samuel Butler dans son ouvrage « Darwin parmi les machines » dès 1863, et développée par George Dyson dans son livre de 1998 intitulé Darwin parmi les machines : l’évolution de l’intelligence globale .
Dans la fiction
Les êtres artificiels capables de penser sont apparus comme des outils narratifs depuis l'Antiquité, et ont été un thème persistant dans la science-fiction .
Un thème récurrent dans ces œuvres a vu le jour avec Frankenstein de Mary Shelley , où une créature humaine devient une menace pour ses créateurs. On le retrouve notamment dans 2001 : L’Odyssée de l’espace d’Arthur C. Clarke et de Stanley Kubrick (tous deux sortis en 1968), avec HAL 9000 , l’ordinateur meurtrier aux commandes du vaisseau Discovery One , ainsi que dans Blade Runner (1982), Terminator (1984) et Matrix (1999). À l’inverse, les rares robots loyaux tels que Gort dans Le Jour où la Terre s’arrêta (1951) et Bishop dans Aliens (1986) sont moins présents dans la culture populaire.
Isaac Asimov a introduit les Trois Lois de la Robotique dans de nombreuses histoires, notamment avec l'ordinateur super-intelligent « Multivac ». Les lois d'Asimov sont souvent évoquées lors de discussions profanes sur l'éthique des machines ; bien que presque tous les chercheurs en intelligence artificielle connaissent les lois d'Asimov grâce à la culture populaire, ils les considèrent généralement comme inutiles pour de nombreuses raisons, dont leur ambiguïté.
Plusieurs œuvres utilisent l'IA pour nous contraindre à nous confronter à la question fondamentale de ce qui nous définit en tant qu'êtres humains, en nous présentant des êtres artificiels capables de ressentir , et donc de souffrir. On retrouve cette thématique dans RUR de Karel Čapek , dans les films AI (Intelligence artificielle) et Ex Machina , ainsi que dans le roman Les androïdes rêvent-ils de moutons électriques ? de Philip K. Dick . Ce dernier explore l'idée que notre compréhension de la subjectivité humaine est altérée par les technologies créées grâce à l'intelligence artificielle.