
L' unité centrale de traitement (CPU), également appelée processeur principal ou processeur , est le processeur principal d' un ordinateur donné . [ 1 électroniques exécutent les instructions d'un programme informatique , telles que les opérations arithmétiques , logiques, de contrôle et d'entrée/sortie (E/S). Ce rôle contraste avec celui des composants externes, tels que la mémoire principale et les circuits d'E/S, et des coprocesseurs spécialisés tels que les unités de traitement graphique (GPU).
La forme, la conception et la mise en œuvre des processeurs ont évolué au fil du temps, mais leur fonctionnement fondamental demeure quasiment inchangé. Les principaux composants d'un processeur comprennent l' unité arithmétique et logique (UAL), qui effectue les opérations arithmétiques et logiques ; les registres du processeur , qui fournissent les opérandes à l'UAL et stockent les résultats de ses opérations ; et une unité de contrôle , qui orchestre l' accès (en mémoire) , le décodage et l'exécution (des instructions) en coordonnant les opérations de l'UAL, des registres et des autres composants. Les processeurs modernes consacrent une part importante de leur surface de semi-conducteurs aux caches et au parallélisme au niveau des instructions afin d'accroître les performances, ainsi qu'aux modes de fonctionnement du processeur pour prendre en charge les systèmes d'exploitation et la virtualisation .
La plupart des processeurs modernes sont implémentés sur des microprocesseurs à circuits intégrés (CI) , avec un ou plusieurs processeurs sur une seule puce. Les puces de microprocesseur comportant plusieurs processeurs sont appelées processeurs multicœurs ( MCP ). Les processeurs physiques individuels, appelés cœurs de processeur , peuvent également être multithreadés pour prendre en charge le multithreading au niveau du processeur.
Un circuit intégré contenant un processeur peut également contenir de la mémoire , des interfaces périphériques et d'autres composants d'un ordinateur ; ces dispositifs intégrés sont appelés de diverses manières microcontrôleurs ou systèmes sur puce (SoC).
Les premiers ordinateurs, tels que l' ENIAC, devaient être physiquement recâblés pour effectuer différentes tâches, ce qui leur valut l'appellation d'« ordinateurs à programme fixe ». Le terme « unité centrale de traitement » est utilisé depuis au moins 1955. Étant donné que le terme « CPU » est généralement défini comme un dispositif d' exécution de logiciels (programmes informatiques), les premiers dispositifs pouvant être légitimement qualifiés de CPU sont apparus avec l'avènement de l' ordinateur à programme enregistré .
L'idée d'un ordinateur à programme enregistré était déjà présente dans la conception de l'ENIAC de John Presper Eckert et John William Mauchly , mais elle fut initialement omise afin d'accélérer sa réalisation. Le 30 juin 1945, avant même la fabrication de l'ENIAC, le mathématicien John von Neumann diffusa un document intitulé « Première ébauche d'un rapport sur l'EDVAC » . Il s'agissait des grandes lignes d'un ordinateur à programme enregistré qui serait finalement achevé en août 1949. L'EDVAC était conçu pour exécuter un certain nombre d'instructions (ou opérations) de différents types. Point important, les programmes écrits pour l'EDVAC devaient être stockés dans la mémoire vive de l'ordinateur, et non pas définis par le câblage physique de celui-ci. Ceci permettait de surmonter une limitation majeure de l'ENIAC : le temps et les efforts considérables nécessaires pour reconfigurer l'ordinateur afin d'effectuer une nouvelle tâche. Grâce à la conception de von Neumann, le programme exécuté par EDVAC pouvait être modifié simplement en changeant le contenu de la mémoire. EDVAC n'était pas le premier ordinateur à programme enregistré ; le Manchester Baby , un ordinateur expérimental à programme enregistré de petite taille, a exécuté son premier programme le 21 juin 1948 et le Manchester Mark 1 a exécuté son premier programme dans la nuit du 16 au 17 juin 1949.
Les premiers processeurs étaient des conceptions sur mesure utilisées au sein d'ordinateurs plus vastes et parfois spécifiques. Cependant, cette méthode de conception de processeurs personnalisés pour une application particulière a largement cédé la place au développement de processeurs polyvalents produits en grande série. Cette standardisation a débuté à l'époque des ordinateurs centraux et des mini-ordinateurs à transistors discrets et s'est rapidement accélérée avec la popularisation des circuits intégrés (CI). Les CI ont permis de concevoir et de fabriquer des processeurs de plus en plus complexes avec des tolérances de l'ordre du nanomètre . La miniaturisation et la standardisation des processeurs ont accru la présence des appareils numériques dans la vie moderne, bien au-delà de l'utilisation limitée des ordinateurs dédiés. Les microprocesseurs modernes sont présents dans des appareils électroniques allant des automobiles aux téléphones portables , et même parfois dans des jouets.
Bien que l'on attribue généralement à von Neumann la conception de l'ordinateur à programme enregistré grâce à son projet EDVAC, dont l'architecture est devenue célèbre sous le nom d' architecture von Neumann , d'autres avant lui, comme Konrad Zuse , avaient proposé et mis en œuvre des idées similaires. L' architecture dite Harvard du Harvard Mark I , achevée avant EDVAC, utilisait également une architecture à programme enregistré sur bande perforée plutôt que sur mémoire électronique. La principale différence entre les deux réside dans le fait que l'architecture Harvard sépare le stockage et le traitement des instructions et des données du processeur, tandis que l'architecture von Neumann utilise le même espace mémoire pour les deux. La plupart des processeurs modernes sont principalement conçus selon l'architecture von Neumann, mais on trouve également des processeurs à architecture Harvard, notamment dans les applications embarquées ; par exemple, les microcontrôleurs Atmel AVR sont des processeurs à architecture Harvard.
Avant l'invention du transistor, les relais et les tubes à vide (tubes thermoïoniques) étaient couramment utilisés comme éléments de commutation ; un ordinateur fonctionnel nécessite des milliers, voire des dizaines de milliers, de dispositifs de commutation. La vitesse globale d'un système dépend de la vitesse de ces commutateurs. Les ordinateurs à tubes à vide, tels que l'EDVAC, présentaient en moyenne un intervalle de huit heures entre les pannes, tandis que les ordinateurs à relais, comme le Harvard Mark I , plus lent mais antérieur , tombaient très rarement en panne. Finalement, les processeurs à tubes se sont imposés car les gains de vitesse significatifs qu'ils offraient compensaient généralement les problèmes de fiabilité. La plupart de ces premiers processeurs synchrones fonctionnaient à des fréquences d'horloge faibles comparées aux conceptions microélectroniques modernes. Les fréquences des signaux d'horloge, comprises entre 100 kHz et 4 MHz, étaient très courantes à cette époque, principalement limitées par la vitesse des dispositifs de commutation utilisés.
Processeurs à transistors

En 1964, IBM a lancé son architecture informatique IBM System/360 , utilisée dans une série d'ordinateurs capables d'exécuter les mêmes programmes à des vitesses et performances différentes. Cette innovation était majeure à une époque où la plupart des ordinateurs électroniques étaient incompatibles entre eux, même ceux du même constructeur. Pour faciliter cette amélioration, IBM a utilisé le concept de microprogramme (souvent appelé « microcode »), encore largement utilisé dans les processeurs modernes. L'architecture System/360 a connu un tel succès qu'elle a dominé le marché des ordinateurs centraux pendant des décennies, laissant un héritage perpétué par des ordinateurs modernes similaires comme l'IBM zSeries . En 1965, Digital Equipment Corporation (DEC) a lancé un autre ordinateur influent destiné aux marchés scientifiques et de la recherche : le PDP-8 .

Les ordinateurs à transistors présentaient plusieurs avantages distincts par rapport à leurs prédécesseurs. Outre une fiabilité accrue et une consommation d'énergie réduite, les transistors permettaient également aux processeurs de fonctionner à des vitesses beaucoup plus élevées grâce à leur temps de commutation très court, comparé à celui d'un tube ou d'un relais. L'amélioration de la fiabilité et l'augmentation spectaculaire de la vitesse des éléments de commutation, qui étaient alors presque exclusivement des transistors, ont permis d'atteindre facilement des fréquences d'horloge de plusieurs dizaines de mégahertz. Par ailleurs, tandis que les processeurs à transistors discrets et à circuits intégrés étaient largement utilisés, de nouvelles conceptions hautes performances, comme les processeurs vectoriels SIMD ( Single Instruction, Multiple Data ), ont commencé à apparaître. Ces premières conceptions expérimentales ont ensuite donné naissance à l'ère des supercalculateurs spécialisés , tels que ceux fabriqués par Cray Inc. et Fujitsu Ltd.
Processeurs à intégration à petite échelle

Durant cette période, une méthode de fabrication de nombreux transistors interconnectés dans un espace réduit a été mise au point. Le circuit intégré (CI) a permis de fabriquer un grand nombre de transistors sur une seule puce semi - conductrice . Au départ, seuls des circuits numériques très simples, comme les portes NOR, ont été miniaturisés en CI. Les processeurs basés sur ces CI « blocs de construction » sont généralement appelés dispositifs à « intégration à petite échelle » (SSI). Les CI SSI, tels que ceux utilisés dans l’ ordinateur de guidage Apollo , contenaient généralement jusqu’à quelques dizaines de transistors. La construction d’un processeur complet à partir de CI SSI nécessitait des milliers de puces individuelles, tout en consommant beaucoup moins d’espace et d’énergie que les conceptions à transistors discrets antérieures.
Le System/370 d'IBM , successeur du System/360, utilisait des circuits intégrés SSI plutôt que des modules à transistors discrets Solid Logic Technology . Les PDP-8 /I et KI10 PDP-10 de DEC sont également passés des transistors individuels utilisés par les PDP-8 et KA PDP-10 aux circuits intégrés SSI, et leur gamme PDP-11 , extrêmement populaire , était initialement construite avec des circuits intégrés SSI, mais a finalement été mise en œuvre avec des composants LSI une fois ceux-ci devenus pratiques.
Processeurs à intégration à grande échelle
Lee Boysel a publié des articles influents, dont un « manifeste » de 1967, décrivant comment construire l'équivalent d'un ordinateur central 32 bits à partir d'un nombre relativement restreint de circuits intégrés à grande échelle (LSI). La seule façon de fabriquer des puces LSI, c'est-à-dire des puces comportant une centaine de portes logiques ou plus, était d'utiliser un procédé de fabrication de semi-conducteurs métal-oxyde-semi-conducteur (MOS) ( logique PMOS , NMOS ou CMOS ). Cependant, certaines entreprises ont continué à fabriquer des processeurs à partir de puces logiques à transistors bipolaires (TTL) car les transistors bipolaires étaient plus rapides que les puces MOS jusque dans les années 1970 (quelques entreprises, comme Datapoint, ont continué à fabriquer des processeurs à partir de puces TTL jusqu'au début des années 1980). Dans les années 1960, les circuits intégrés MOS étaient plus lents et étaient initialement considérés comme utiles uniquement pour les applications nécessitant une faible consommation d'énergie. Suite au développement de la technologie MOS à grille de silicium par Federico Faggin chez Fairchild Semiconductor en 1968, les circuits intégrés MOS ont largement remplacé la technologie TTL bipolaire comme technologie de puce standard à la fin des années 1970.
Avec les progrès de la microélectronique , le nombre de transistors intégrés sur les circuits intégrés a augmenté, réduisant ainsi le nombre de circuits intégrés nécessaires à un processeur complet. Les circuits intégrés MSI et LSI ont permis d'intégrer des centaines, puis des milliers de transistors. En 1968, le nombre de circuits intégrés requis pour construire un processeur complet avait été réduit à 24 circuits intégrés de huit types différents, chaque circuit intégré contenant environ 1 000 MOSFET. À l'inverse de ses prédécesseurs SSI et MSI, la première implémentation LSI du PDP-11 comportait un processeur composé de seulement quatre circuits intégrés LSI.
Microprocesseurs



Depuis leur apparition, les microprocesseurs ont quasiment supplanté toutes les autres méthodes de conception d'unités centrales de traitement. Le premier microprocesseur commercialisé, l' Intel 4004 , sorti en 1971, fut l'un des premiers processeurs grand public à intégrer une unité arithmétique et logique , une unité de contrôle et une unité de registres sur une seule puce . Le premier microprocesseur largement répandu, l' Intel 8080 , sorti en 1974, vit le jour . À cette époque, les fabricants d'ordinateurs centraux et de mini-ordinateurs lancèrent des programmes de développement de circuits intégrés propriétaires pour moderniser leurs anciennes architectures informatiques et finirent par produire des microprocesseurs compatibles avec leur jeu d' instructions , et donc rétrocompatibles avec leurs anciens matériels et logiciels. Avec l'avènement et le succès de l' ordinateur personnel , le terme « processeur » est aujourd'hui presque exclusivement réservé aux microprocesseurs . Plusieurs processeurs (appelés cœurs ) peuvent être intégrés sur une seule puce
de composants discrets et de nombreux petits circuits intégrés (CI) sur une ou plusieurs cartes de circuit imprimé. Les microprocesseurs, quant à eux, sont des processeurs fabriqués sur un nombre très réduit de CI, généralement un seul. La taille globale réduite du processeur, grâce à son intégration sur une seule puce, permet un temps de commutation plus rapide grâce à des facteurs physiques tels que la diminution de la capacité parasite de grille . Ceci a permis aux microprocesseurs synchrones d'atteindre des fréquences d'horloge allant de quelques dizaines de mégahertz à plusieurs gigahertz. De plus, la possibilité de fabriquer des transistors extrêmement petits sur un CI a considérablement accru la complexité et le nombre de transistors dans un seul processeur. Cette tendance largement observée est décrite par la loi de Moore , qui s'est avérée être un prédicteur assez précis de la croissance de la complexité des processeurs (et autres CI) jusqu'en 2016.
Bien que la complexité, la taille, la construction et la forme générale des processeurs aient considérablement évolué depuis 1950 , leur conception et leur fonctionnement de base sont restés quasiment inchangés. Presque tous les processeurs courants actuels peuvent être décrits avec une grande précision comme des machines à programme enregistré de type von Neumann . La loi de Moore n'étant plus valable, des inquiétudes émergent quant aux limites de la technologie des transistors dans les circuits intégrés. L'extrême miniaturisation des portes électroniques accentue considérablement les effets de phénomènes tels que l'électromigration et les courants de fuite sous le seuil . Ces nouvelles préoccupations figurent parmi les nombreux facteurs qui incitent les chercheurs à explorer de nouvelles méthodes de calcul, comme l' ordinateur quantique , et à développer l'utilisation du parallélisme et d'autres méthodes qui étendent le champ d'application du modèle classique de von Neumann.
Opération
Le fonctionnement fondamental de la plupart des processeurs, quelle que soit leur forme physique, consiste à exécuter une séquence d' instructions stockées , appelée programme. Ces instructions sont conservées dans une mémoire informatique . Presque tous les processeurs suivent les étapes de lecture, de décodage et d'exécution, qui constituent le cycle d'instruction .
Après l'exécution d'une instruction, le processus se répète, le cycle d'instruction suivant chargeant normalement l'instruction suivante dans la séquence grâce à l'incrémentation du compteur de programme . Si une instruction de saut a été exécutée, le compteur de programme est modifié pour contenir l'adresse de l'instruction vers laquelle le saut a été effectué, et l'exécution du programme reprend normalement. Dans les processeurs plus complexes, plusieurs instructions peuvent être chargées, décodées et exécutées simultanément. Cette section décrit ce que l'on appelle généralement le « pipeline RISC classique », très répandu dans les processeurs simples utilisés dans de nombreux appareils électroniques (souvent appelés microcontrôleurs). Elle néglige en grande partie le rôle important du cache du processeur, et donc l'étape d'accès au pipeline.
Certaines instructions manipulent le compteur de programme au lieu de produire directement des données de résultat ; ces instructions sont généralement appelées « sauts » et facilitent des comportements de programme tels que les boucles , l’exécution conditionnelle (par le biais d’un saut conditionnel) et l’existence de fonctions . Sur certains processeurs, d’autres instructions modifient l’état des bits d’un registre de « flags » . Ces flags peuvent être utilisés pour influencer le comportement d’un programme, car ils indiquent souvent le résultat de diverses opérations. Par exemple, sur ces processeurs, une instruction de « comparaison » évalue deux valeurs et positionne ou efface les bits du registre de flags pour indiquer laquelle est supérieure ou si elles sont égales ; l’un de ces flags pourrait ensuite être utilisé par une instruction de saut ultérieure pour déterminer le flux d’exécution du programme.
Aller chercher
L'extraction consiste à récupérer une instruction (représentée par un nombre ou une séquence de nombres) depuis la mémoire programme. L'emplacement (adresse) de l'instruction en mémoire programme est déterminé par le compteur de programme (PC ; appelé « pointeur d'instruction » sur les microprocesseurs Intel x86 ), qui stocke un nombre identifiant l'adresse de la prochaine instruction à extraire. Une fois l'instruction extraite, le PC est incrémenté de la longueur de l'instruction afin de contenir l'adresse de l'instruction suivante dans la séquence. Souvent, l'instruction à extraire doit être récupérée depuis une mémoire relativement lente, ce qui provoque un blocage du processeur pendant l'attente du retour de l'instruction. Ce problème est largement résolu dans les processeurs modernes grâce aux caches et aux architectures pipeline (voir ci-dessous).
Décoder
La manière dont l'instruction est interprétée est définie par l'architecture du jeu d'instructions (ISA) du processeur. Souvent, un groupe de bits (appelé « champ ») au sein de l'instruction, appelé code opération ( opcode ), indique l'opération à effectuer, tandis que les champs restants fournissent généralement des informations supplémentaires nécessaires à l'opération, telles que les opérandes. Ces opérandes peuvent être spécifiés comme une valeur constante (appelée valeur immédiate) ou comme l'emplacement d'une valeur qui peut être un registre du processeur ou une adresse mémoire, selon un mode d'adressage donné .
Dans certaines architectures de processeurs, le décodeur d'instructions est implémenté sous la forme d'un circuit de décodage binaire câblé et non modifiable. Dans d'autres, un microprogramme est utilisé pour traduire les instructions en ensembles de signaux de configuration du processeur, appliqués séquentiellement sur plusieurs cycles d'horloge. Dans certains cas, la mémoire stockant le microprogramme est réinscriptible, ce qui permet de modifier le mode de décodage des instructions par le processeur.
Exécuter
Après les étapes de récupération et de décodage, l'étape d'exécution est effectuée. Selon l'architecture du processeur, il peut s'agir d'une action unique ou d'une séquence d'actions. Lors de chaque action, des signaux de contrôle activent ou désactivent électriquement différentes parties du processeur afin qu'elles puissent réaliser tout ou partie de l'opération souhaitée. L'action est ensuite terminée, généralement en réponse à une impulsion d'horloge. Très souvent, les résultats sont écrits dans un registre interne du processeur pour un accès rapide par les instructions suivantes. Dans d'autres cas, les résultats peuvent être écrits dans la mémoire principale, plus lente, mais moins coûteuse et de plus grande capacité .
Par exemple, lors de l'exécution d'une instruction d'addition, les registres contenant les opérandes (les nombres à additionner) sont activés, de même que les composants de l' unité arithmétique et logique (UAL) effectuant l'addition. À chaque impulsion d'horloge, les opérandes sont transférés des registres sources vers l'UAL, et la somme apparaît à sa sortie. Aux impulsions d'horloge suivantes, d'autres composants sont activés (ou désactivés) pour transférer le résultat (la somme de l'opération) vers un support de stockage (registre ou mémoire, par exemple). Si la somme résultante est trop grande (c'est-à-dire supérieure à la taille d'un mot de sortie de l'UAL), un indicateur de dépassement de capacité arithmétique est activé, ce qui affecte l'opération suivante.
Structure et mise en œuvre
L'ensemble des opérations de base qu'un processeur peut effectuer, appelé jeu d'instructions , est intégré à son circuit . Ces opérations peuvent consister, par exemple, à additionner ou soustraire deux nombres, à comparer deux nombres ou à exécuter une autre partie d'un programme. Chaque instruction est représentée par une combinaison unique de bits , appelée code opération (ou opcode) en langage machine . Lors du traitement d'une instruction, le processeur décode l'opcode (via un décodeur binaire ) en signaux de contrôle, qui pilotent son comportement. Une instruction complète en langage machine se compose d'un opcode et, dans de nombreux cas, de bits supplémentaires spécifiant les arguments de l'opération (par exemple, les nombres à additionner lors d'une addition). Plus complexe, un programme en langage machine est un ensemble d'instructions en langage machine exécutées par le processeur.
L'opération mathématique proprement dite de chaque instruction est réalisée par un circuit logique combinatoire au sein du processeur, appelé unité arithmétique et logique (UAL). En général, un processeur exécute une instruction en la récupérant en mémoire, en utilisant son UAL pour effectuer l'opération, puis en stockant le résultat en mémoire. Outre les instructions relatives aux calculs et opérations logiques sur les entiers, il existe diverses autres instructions machine, telles que celles permettant de charger des données depuis la mémoire et de les y stocker, les opérations de branchement et les opérations mathématiques sur les nombres à virgule flottante effectuées par l' unité de calcul en virgule flottante (FPU) du processeur.
unité de contrôle
unité arithmétique et logique
L'unité arithmétique et logique (UAL) est un circuit numérique intégré au processeur qui effectue des opérations arithmétiques sur les entiers et des opérations logiques bit à bit . Ses entrées sont les données à traiter (appelées opérandes ), les informations d'état des opérations précédentes et un code provenant de l'unité de contrôle indiquant l'opération à réaliser. Selon l'instruction exécutée, les opérandes peuvent provenir des registres internes du processeur , de la mémoire externe ou de constantes générées par l'UAL elle-même.
Une fois que tous les signaux d'entrée se sont stabilisés et propagés à travers le circuit de l'UAL, le résultat de l'opération effectuée apparaît aux sorties de l'UAL. Ce résultat comprend un mot de données, qui peut être stocké dans un registre ou en mémoire, et des informations d'état généralement stockées dans un registre interne du processeur dédié.
Les processeurs modernes contiennent généralement plusieurs unités arithmétiques et logiques (ALU) pour améliorer leurs performances.
unité de génération d'adresses
Lors de diverses opérations, les processeurs doivent calculer les adresses mémoire nécessaires à l'accès aux données. Par exemple, la position en mémoire des éléments d'un tableau doit être calculée avant que le processeur puisse extraire les données de leurs emplacements mémoire. Ces calculs de génération d'adresses impliquent différentes opérations arithmétiques sur les entiers , telles que l'addition, la soustraction, le modulo ou les décalages de bits . Souvent, le calcul d'une adresse mémoire requiert plusieurs instructions machine générales, dont le décodage et l'exécution ne sont pas nécessairement rapides. En intégrant une unité de génération d'adresses (UGA) dans la conception du processeur, et en introduisant des instructions spécialisées utilisant l'UGA, divers calculs de génération d'adresses peuvent être déchargés du reste du processeur et souvent exécutés rapidement en un seul cycle processeur.
Les capacités d'une unité de calcul d'adresse (AGU) dépendent du processeur et de son architecture . Ainsi, certaines AGU implémentent et exposent davantage d'opérations de calcul d'adresse, tandis que d'autres incluent des instructions spécialisées plus avancées, capables de traiter plusieurs opérandes simultanément. Certaines architectures de processeur intègrent plusieurs AGU, permettant ainsi l'exécution simultanée de plusieurs opérations de calcul d'adresse. Ceci améliore encore les performances grâce à la nature superscalaire des processeurs de pointe. Par exemple, Intel intègre plusieurs AGU dans ses microarchitectures Sandy Bridge et Haswell , ce qui accroît la bande passante du sous-système mémoire du processeur en autorisant l'exécution parallèle de plusieurs instructions d'accès mémoire.
unité de gestion de la mémoire (MMU)
Cache
Le cache du processeur est une mémoire utilisée par l'unité centrale de traitement (CPU) d'un ordinateur pour réduire le coût moyen (temps ou énergie) d'accès aux données de la mémoire principale . Il s'agit d'une mémoire plus petite et plus rapide, plus proche du cœur du processeur , qui stocke des copies des données provenant d'emplacements fréquemment utilisés en mémoire principale . La plupart des processeurs possèdent différents caches indépendants, généralement organisés de manière hiérarchique sur plusieurs niveaux (L1, L2, L3, L4, etc.). Chaque niveau de cache supérieur est généralement plus lent mais plus grand que le précédent, L1 étant le plus rapide et le plus proche du processeur. Au niveau L1, on trouve généralement des caches d'instructions et de données distincts .
La plupart des processeurs modernes (rapides), à quelques exceptions près , possèdent plusieurs niveaux de cache. Les premiers processeurs utilisant un cache n'en disposaient que d'un seul ; contrairement aux caches de niveau 1 ultérieurs, celui-ci n'était pas divisé en L1d (pour les données) et L1i (pour les instructions). Presque tous les processeurs actuels avec cache possèdent un cache L1 divisé. Ils disposent également de caches L2 et, pour les processeurs plus puissants, de caches L3. Le cache L2 n'est généralement pas divisé et sert de mémoire partagée pour le cache L1, lui-même divisé. Chaque cœur d'un processeur multicœur possède un cache L2 dédié, généralement non partagé entre les cœurs. Le cache L3, ainsi que les caches de niveau supérieur, sont partagés entre les cœurs et ne sont pas divisés. Le cache L4 est actuellement rare et se trouve généralement sur une mémoire vive dynamique (DRAM), plutôt que sur une mémoire vive statique (SRAM), sur une puce distincte. C'était également le cas historiquement pour le cache L1, tandis que les puces plus grandes ont permis son intégration, ainsi que celle de tous les niveaux de cache, à l'exception possible du dernier. Chaque niveau de cache supplémentaire est généralement plus volumineux et optimisé différemment.
Il existe d'autres types de caches (qui ne sont pas comptabilisés dans la « taille du cache » des caches les plus importants mentionnés ci-dessus), tels que le tampon de traduction (TLB) qui fait partie de l' unité de gestion de la mémoire (MMU) que possèdent la plupart des processeurs.
Les caches sont généralement dimensionnés en puissances de deux : 2, 8, 16, etc. KiB ou MiB (pour les tailles non-L1 plus grandes), bien que l' IBM z13 dispose d'un cache d'instructions L1 de 96 KiB.
Fréquence d'horloge
Pour garantir le bon fonctionnement du processeur, la période d'horloge est supérieure au temps maximal de propagation de tous les signaux à travers celui-ci. En fixant la période d'horloge à une valeur nettement supérieure au délai de propagation maximal , il est possible de concevoir l'ensemble du processeur et la manière dont il traite les données en contournant les transitions montantes et descendantes du signal d'horloge. Ceci présente l'avantage de simplifier considérablement le processeur, tant du point de vue de sa conception que du nombre de composants. Cependant, cela a également l'inconvénient d'obliger l'ensemble du processeur à attendre ses éléments les plus lents, même si certaines parties sont beaucoup plus rapides. Cette limitation a été largement compensée par diverses méthodes d'augmentation du parallélisme du processeur (voir ci-dessous).
Cependant, les améliorations architecturales ne suffisent pas à résoudre tous les inconvénients des processeurs synchrones. Par exemple, un signal d'horloge est soumis aux délais de tout autre signal électrique. Avec des fréquences d'horloge plus élevées dans des processeurs de plus en plus complexes, il devient plus difficile de maintenir la synchronisation du signal d'horloge sur l'ensemble du système. C'est pourquoi de nombreux processeurs modernes nécessitent plusieurs signaux d'horloge identiques afin d'éviter qu'un retard significatif d'un seul signal ne provoque un dysfonctionnement. Autre problème majeur : l'augmentation importante des fréquences d'horloge engendre une dissipation thermique accrue du processeur . La variation constante de l'horloge provoque la commutation de nombreux composants, qu'ils soient ou non utilisés. Or, un composant en fonctionnement consomme généralement plus d'énergie qu'un composant à l'arrêt. Par conséquent, l'augmentation de la fréquence d'horloge entraîne une hausse de la consommation d'énergie, ce qui impose au processeur un système de refroidissement plus performant pour dissiper la chaleur .
Une méthode permettant de gérer la mise hors tension des composants inutilisés est appelée « désactivation d'horloge », qui consiste à couper le signal d'horloge des composants inutiles (les désactivant ainsi). Cependant, cette technique est souvent considérée comme difficile à mettre en œuvre et n'est donc pas couramment utilisée en dehors des conceptions à très faible consommation. Un exemple notable de processeur utilisant largement la désactivation d'horloge est le Xenon basé sur IBM PowerPC , utilisé dans la Xbox 360 ; cela permet de réduire la consommation d'énergie de la Xbox 360.
Processeurs sans horloge
Une autre méthode pour résoudre certains problèmes liés à un signal d'horloge global consiste à le supprimer complètement. Bien que la suppression du signal d'horloge global complexifie considérablement le processus de conception à bien des égards, les conceptions asynchrones (ou sans horloge) présentent des avantages marqués en termes de consommation d'énergie et de dissipation thermique par rapport aux conceptions synchrones similaires. Bien que relativement rares, des processeurs entièrement asynchrones ont été construits sans utiliser de signal d'horloge global. Deux exemples notables sont l' AMULET, compatible ARM , et le MiniMIPS, compatible MIPS R3000.
Plutôt que de supprimer totalement le signal d'horloge, certaines conceptions de processeurs permettent à certaines parties du dispositif d'être asynchrones, par exemple en utilisant des unités arithmétiques et logiques asynchrones ( UAL) associées à un pipeline superscalaire pour améliorer les performances arithmétiques. Bien qu'il ne soit pas tout à fait clair si les conceptions totalement asynchrones peuvent atteindre un niveau de performance comparable ou supérieur à celui de leurs homologues synchrones, il est évident qu'elles excellent au moins dans les opérations mathématiques les plus simples. Ceci, combiné à leurs excellentes propriétés de consommation d'énergie et de dissipation thermique, les rend particulièrement adaptées aux ordinateurs embarqués .
module régulateur de tension
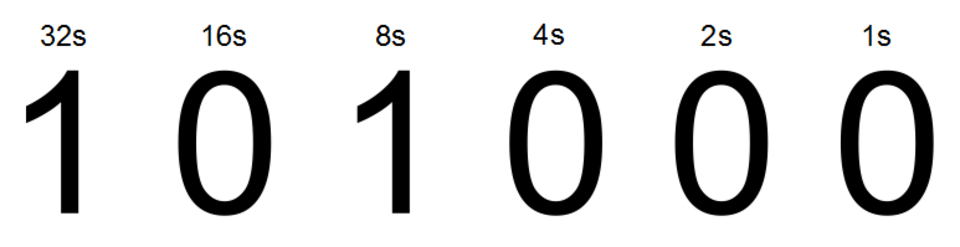
La représentation numérique est liée à la taille et à la précision des nombres entiers qu'un processeur peut représenter. Dans le cas d'un processeur binaire, cette précision est mesurée par le nombre de bits (chiffres significatifs d'un entier codé en binaire) que le processeur peut traiter en une seule opération. On parle alors de taille de mot , de largeur de bits , de largeur du chemin de données , de précision entière ou de taille entière . La taille entière d'un processeur détermine la plage de valeurs entières sur lesquelles il peut opérer directement. , un processeur 8 bits peut manipuler directement des entiers représentés par huit bits, ce qui correspond une plage de 2⁵⁶ (2⁸ ) valeurs entières discrètes.
La plage d'entiers peut également affecter le nombre d'emplacements mémoire que le processeur peut adresser directement (une adresse est une valeur entière représentant un emplacement mémoire spécifique). Par exemple, si un processeur binaire utilise 32 bits pour représenter une adresse mémoire, il peut adresser directement 2<sup> 32</sup> emplacements mémoire. Pour contourner cette limitation et pour diverses autres raisons, certains processeurs utilisent des mécanismes (tels que la gestion de la mémoire ou la commutation de banque ) permettant d'adresser davantage de mémoire.
Les processeurs à grande taille de mots nécessitent davantage de circuits et sont donc physiquement plus volumineux, plus coûteux et consomment plus d'énergie (générant ainsi plus de chaleur). C'est pourquoi les microcontrôleurs 4 ou 8 bits, plus petits , sont couramment utilisés dans les applications modernes, même si des processeurs à taille de mots beaucoup plus importante (16, 32, 64, voire 128 bits) sont disponibles. Cependant, lorsque des performances supérieures sont requises, les avantages d'une taille de mots plus importante (plages de données et espaces d'adressage plus étendus) peuvent compenser les inconvénients. Un processeur peut avoir des chemins de données internes plus courts que la taille d'un mot afin de réduire sa taille et son coût. Par exemple, bien que l' architecture du jeu d'instructions IBM System/360 soit un jeu d'instructions 32 bits, les modèles System/360 30 et 40 disposaient de chemins de données 8 bits dans l'unité arithmétique et logique, de sorte qu'une addition 32 bits nécessitait quatre cycles, un pour chaque groupe de 8 bits des opérandes. De même, bien que le jeu d'instructions de la série Motorola 68000 soit un jeu d'instructions 32 bits, les modèles Motorola 68000 et Motorola 68010 disposaient de chemins de données 16 bits dans l'unité arithmétique et logique, de sorte qu'une addition 32 bits nécessitait deux cycles.
Pour tirer parti des avantages offerts par les différentes longueurs de bits, de nombreux jeux d'instructions utilisent des largeurs de bits différentes pour les données entières et à virgule flottante, permettant ainsi aux processeurs implémentant ce jeu d'instructions d'avoir des largeurs de bits différentes pour différentes parties du dispositif. Par exemple, le jeu d'instructions IBM System/360 était principalement sur 32 bits, mais prenait en charge les valeurs à virgule flottante 64 bits afin d'offrir une plus grande précision et une plage de valeurs plus étendue pour les nombres à virgule flottante. Le System/360 Modèle 65 disposait d'un additionneur 8 bits pour l'arithmétique décimale et binaire à virgule fixe, et d'un additionneur 60 bits pour l'arithmétique à virgule flottante. De nombreuses conceptions de processeurs ultérieures utilisent une largeur de bits mixte similaire, en particulier lorsque le processeur est destiné à un usage général nécessitant un équilibre raisonnable entre les capacités de calcul sur les entiers et les nombres à virgule flottante.
Parallélisme
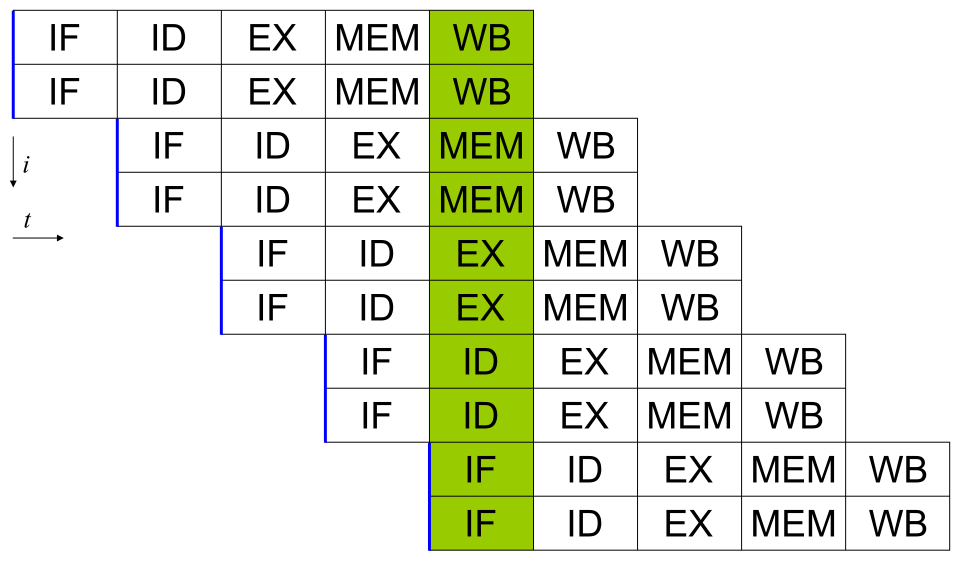
La description du fonctionnement de base d'un processeur présentée dans la section précédente décrit sa forme la plus simple. Ce type de processeur, généralement appelé sous-scalaire , traite et exécute une instruction sur une ou deux données à la fois, soit moins d'une instruction par cycle d'horloge ( unité d'exécution (voir ci-dessous) n'améliore que très peu les performances ; au lieu d'un seul chemin d'exécution bloqué, ce sont désormais deux chemins qui le sont, et le nombre de transistors inutilisés augmente. Cette conception, dans laquelle les ressources d'exécution du processeur ne peuvent traiter qu'une seule instruction à la fois, ne peut atteindre que des performances scalaires (une instruction par cycle d'horloge, le parallélisme au niveau des instructions (ILP), qui vise à augmenter la vitesse à laquelle les instructions sont exécutées au sein d'un processeur (c'est-à-dire à augmenter l'utilisation des ressources d'exécution sur la puce) ; Chaque méthodologie diffère à la fois par sa mise en œuvre et par son efficacité relative à améliorer les performances du processeur pour une application. L'une des méthodes les plus simples pour accroître le parallélisme consiste à entamer les premières étapes de récupération et de décodage des instructions avant même la fin de l'exécution de l'instruction précédente. Cette technique, appelée pipeline d'instructions , est utilisée dans la quasi-totalité des processeurs modernes à usage général. Le pipeline permet l'exécution simultanée de plusieurs instructions en décomposant le chemin d'exécution en étapes distinctes. Cette séparation peut être comparée à une chaîne de montage, où une instruction est complétée à chaque étape jusqu'à sa sortie du pipeline d'exécution et sa mise hors service. Le pipeline introduit cependant la possibilité d'une situation où le résultat de l'opération précédente est nécessaire à l'exécution de l'opération suivante ; une situation souvent qualifiée de conflit de dépendance de données. Par conséquent, les processeurs pipelinés doivent vérifier ce type de situation et retarder une partie du pipeline si nécessaire. Un processeur pipeliné peut se comporter comme un processeur scalaire, son comportement n'étant limité que par les blocages du pipeline (une instruction passant plus d'un cycle d'horloge dans une étape). Les améliorations apportées au pipeline d'instructions ont permis de réduire encore davantage le temps d'inactivité des composants du processeur. Les architectures dites superscalaires comprennent un long pipeline d'instructions et de multiples unités d'exécution identiques , telles que les unités de chargement/stockage , les unités arithmétiques et logiques , les unités de calcul en virgule flottante et les unités de génération d'adresses . Dans un pipeline superscalaire, les instructions sont lues et transmises à un répartiteur, qui détermine si elles peuvent être exécutées en parallèle (simultanément). Le cas échéant, elles sont distribuées aux unités d'exécution, ce qui permet leur exécution simultanée. En général, le nombre d'instructions qu'un processeur superscalaire exécute par cycle dépend du nombre d'instructions qu'il est capable de distribuer simultanément aux unités d'exécution. La principale difficulté de la conception d'une architecture de processeur superscalaire réside dans la création d'un répartiteur efficace. Ce dernier doit pouvoir déterminer rapidement si les instructions peuvent être exécutées en parallèle et les répartir de manière à occuper un maximum d'unités d'exécution. Cela implique un remplissage fréquent du pipeline d'instructions et une importante capacité de cache CPU . Les techniques d'évitement des aléas , telles que la prédiction de branchement , l'exécution spéculative , le renommage de registres , l'exécution hors séquence et la mémoire transactionnelle, sont donc cruciales pour maintenir des performances élevées. En tentant de prédire le branchement (ou chemin) emprunté par une instruction conditionnelle, le processeur minimise le nombre d'attentes du pipeline jusqu'à la fin de son exécution. L'exécution spéculative offre souvent de modestes gains de performance en exécutant des portions de code potentiellement inutiles après la fin d'une opération conditionnelle. L'exécution hors séquence réorganise l'ordre d'exécution des instructions afin de réduire les délais dus aux dépendances de données. De même, dans le cas d' un flux d'instructions unique et de flux de données multiples (un cas où une grande quantité de données du même type doit être traitée), les processeurs modernes peuvent désactiver des parties du pipeline afin que, lorsqu'une seule instruction est exécutée plusieurs fois, le processeur saute les phases de récupération et de décodage, ce qui augmente considérablement les performances dans certains cas, notamment dans les moteurs de programmes très monotones tels que les logiciels de création vidéo et de traitement de photos. Lorsqu'une partie du processeur est superscalaire, la partie non superscalaire subit une perte de performance due aux temps d'attente liés à l'ordonnancement. Le Pentium P5 d'Intel disposait de deux unités arithmétiques et logiques (UAL) superscalaires, chacune capable de traiter une instruction par cycle d'horloge, contrairement à son unité de calcul en virgule flottante (FPU). Le P5 était donc superscalaire pour les entiers, mais pas pour les nombres à virgule flottante. L'architecture P6 , qui a succédé au P5 , a intégré les capacités superscalaires à ses fonctionnalités de calcul en virgule flottante. Le pipeline simple et l'architecture superscalaire augmentent le parallélisme des instructions (ILP) d'un processeur en lui permettant d'exécuter des instructions à un rythme supérieur à une instruction par cycle d'horloge. La plupart des processeurs modernes sont au moins partiellement superscalaires, et la quasi-totalité des processeurs généralistes conçus au cours des dix dernières années le sont. Plus récemment, la conception d'ordinateurs à ILP élevé s'est davantage concentrée sur l'interface logicielle du processeur, ou architecture du jeu d'instructions (ISA), que sur son matériel. La stratégie des mots d'instruction très longs (VLIW) permet au logiciel d'intégrer directement une partie de l'ILP, réduisant ainsi la charge de travail du processeur pour l'améliorer et, par conséquent, la complexité de conception.Parallélisme au niveau des instructions
Parallélisme au niveau des tâches
L'une des technologies utilisées à cette fin est le multiprocesseur (MP) . Le premier type de cette technologie est connu sous le nom de multiprocesseur symétrique (SMP), où un petit nombre de processeurs partagent une vue cohérente de leur système de mémoire. Dans ce schéma, chaque processeur dispose de matériel supplémentaire pour maintenir une vue constamment à jour de la mémoire. En évitant les vues obsolètes de la mémoire, les processeurs peuvent coopérer sur un même programme et les programmes peuvent migrer d'un processeur à l'autre. Pour augmenter le nombre de processeurs coopérants au-delà de quelques-uns, des schémas tels que l'accès mémoire non uniforme (NUMA) et les protocoles de cohérence basés sur un répertoire ont été introduits dans les années 1990. Les systèmes SMP sont limités à un petit nombre de processeurs, tandis que les systèmes NUMA ont été construits avec des milliers de processeurs. Initialement, le multiprocesseur était construit à l'aide de plusieurs processeurs discrets et de cartes pour implémenter l'interconnexion entre les processeurs. Lorsque les processeurs et leur interconnexion sont tous implémentés sur une seule puce, la technologie est connue sous le nom de multiprocesseur au niveau de la puce (CMP) et la puce unique sous le nom de processeur multicœur .
On a découvert par la suite qu'un parallélisme plus fin était possible au sein d'un même programme. Un programme unique pouvait comporter plusieurs threads (ou fonctions) exécutables séparément ou en parallèle. Parmi les premiers exemples de cette technologie, on trouve l'implémentation du traitement des entrées/sorties , comme l'accès direct à la mémoire , dans un thread distinct du thread de calcul. Une approche plus générale a été introduite dans les années 1970, avec la conception de systèmes capables d'exécuter plusieurs threads de calcul en parallèle. Cette technologie est connue sous le nom de multithreading (MT). Cette approche est considérée comme plus économique que le multiprocesseur, car seul un petit nombre de composants du processeur sont dupliqués pour prendre en charge le MT, contrairement au multiprocesseur qui duplique l'intégralité du processeur. En MT, les unités d'exécution et le système de mémoire, y compris les caches, sont partagés entre plusieurs threads. L'inconvénient du MT réside dans le fait que le support matériel du multithreading est plus visible pour le logiciel que celui du multiprocesseur ; par conséquent, les logiciels superviseurs, tels que les systèmes d'exploitation, doivent subir des modifications plus importantes pour prendre en charge le MT. Un type de multithreading implémenté est le multithreading temporel , où un thread s'exécute jusqu'à ce qu'il soit bloqué en attente de données provenant de la mémoire externe. Dans ce cas, le processeur effectue rapidement un changement de contexte vers un autre thread prêt à s'exécuter, ce changement étant souvent réalisé en un seul cycle d'horloge, comme sur l' UltraSPARC T1 . Un autre type de multithreading est le multithreading simultané , où les instructions de plusieurs threads sont exécutées en parallèle au cours d'un même cycle d'horloge.
Pendant plusieurs décennies, des années 1970 au début des années 2000, la conception des processeurs à usage général hautes performances s'est principalement concentrée sur l'obtention d'un parallélisme d'instructions (ILP) élevé grâce à des technologies telles que le pipeline, les caches, l'exécution superscalaire, l'exécution hors séquence, etc. Cette tendance a abouti à des processeurs volumineux et énergivores comme l'Intel Pentium 4. Au début des années 2000, les concepteurs de processeurs ont été confrontés à des difficultés pour obtenir des performances encore meilleures grâce aux techniques d'ILP, en raison de l'écart croissant entre les fréquences de fonctionnement du processeur et celles de la mémoire principale, ainsi que de l'augmentation de la dissipation de puissance du processeur due à des techniques d'ILP plus complexes.
Les concepteurs de processeurs ont ensuite emprunté des idées aux marchés de l'informatique commerciale, comme le traitement transactionnel , où les performances globales de plusieurs programmes, également connues sous le nom de calcul à débit élevé , étaient plus importantes que les performances d'un seul thread ou processus.
Ce changement d'orientation est illustré par la prolifération des processeurs à double cœur et à plus de cœurs, notamment par les nouvelles conceptions d'Intel qui rappellent son architecture P6 moins superscalaire . Les modèles récents de plusieurs familles de processeurs intègrent le multiprocesseur au niveau de la puce, comme les x86-64 Opteron et Athlon 64 X2 , le SPARC UltraSPARC T1 , les IBM POWER4 et POWER5 , ainsi que plusieurs processeurs de consoles de jeux vidéo , tels que le PowerPC triple cœur de la Xbox 360 et le microprocesseur Cell à 7 cœurs de la PlayStation 3 .
Parallélisme des données
La plupart des premiers processeurs vectoriels, comme le Cray-1 , étaient presque exclusivement associés à la recherche scientifique et aux applications de cryptographie . Cependant, avec le passage massif du multimédia au numérique, le besoin d'une forme ou d'une autre de SIMD dans les processeurs à usage général est devenu crucial. Peu après la généralisation des unités de calcul en virgule flottante dans ces processeurs, les spécifications et les implémentations d'unités d'exécution SIMD ont commencé à apparaître au milieu des années 1990. Certaines de ces premières spécifications SIMD, comme MAX ( Multimedia Acceleration eXtensions ) de HP et MMX d'Intel , ne prenaient en charge que les entiers. Cela s'est avéré un obstacle majeur pour certains développeurs, car de nombreuses applications tirant parti du SIMD manipulent principalement des nombres à virgule flottante . Progressivement, les développeurs ont perfectionné et repensé ces premières conceptions pour aboutir aux spécifications SIMD modernes courantes, généralement associées à une architecture de jeu d'instructions (ISA). Parmi les exemples modernes notables, citons SSE ( Streaming SIMD Extensions ) d'Intel et AltiVec (également connu sous le nom de VMX), associé à PowerPC .
compteur de performances matérielles
De nombreux grands fournisseurs (tels qu'IBM , Intel , AMD et Arm ) proposent des interfaces logicielles (généralement écrites en C/C++) permettant de collecter des données à partir des registres du processeur afin d'obtenir des métriques. Les fournisseurs de systèmes d'exploitation fournissent également des logiciels comme perf(Linux) pour enregistrer, évaluer ou tracer les événements du processeur lors de l'exécution de noyaux et d'applications.
Les compteurs matériels constituent une méthode peu gourmande en ressources pour collecter des métriques de performance complètes relatives aux éléments essentiels d'un processeur (unités fonctionnelles, caches, mémoire principale, etc.) – un avantage considérable par rapport aux profileurs logiciels. De plus, ils permettent généralement de s'affranchir de la modification du code source d'un programme. Les types et interprétations des compteurs matériels varient selon les architectures.
Modes privilégiés
La plupart des processeurs modernes disposent de modes privilégiés pour prendre en charge les systèmes d'exploitation et la virtualisation.
Le cloud computing peut utiliser la virtualisation pour fournir une unité centrale de traitement virtuelle ( vCPU ) pour des utilisateurs distincts ; la vCPU ne doit pas être confondue avec un serveur privé virtuel (VPS).
Un hôte est l'équivalent virtuel d'une machine physique sur laquelle s'exécute un système virtuel. Lorsque plusieurs machines physiques fonctionnent en tandem et sont gérées comme un tout, leurs ressources de calcul et de mémoire regroupées forment un cluster . Dans certains systèmes, il est possible d'ajouter ou de retirer dynamiquement des éléments d'un cluster. Les ressources disponibles au niveau de l'hôte et du cluster peuvent être partitionnées en pools de ressources avec une granularité fine .
Performance
Grâce aux capacités spécifiques des processeurs modernes, telles que le multithreading simultané et l'uncore , qui impliquent le partage des ressources du processeur tout en visant une utilisation accrue, la surveillance des performances et de l'utilisation du matériel est devenue progressivement plus complexe. En réponse, certains processeurs intègrent une logique matérielle supplémentaire qui surveille l'utilisation réelle des différentes parties du processeur et fournit divers compteurs accessibles aux logiciels ; la technologie Performance Counter Monitor d'Intel en est un exemple .