
Le neurone artificiel et le réseau neuronal artificiel ont été inventés en 1943 par Warren McCulloch et Walter Pitts dans leur article fondateur « A Logical Calculus of the Ideas Immanent in Nervous Activity ».
En 1957, Frank Rosenblatt travaillait au Laboratoire aéronautique de Cornell . Il simula le perceptron sur un IBM 704. S'intéressant davantage aux implémentations matérielles , il obtint des fonds de la Division des systèmes d'information du Bureau de la recherche navale des États-Unis et du Centre de développement aérien de Rome pour construire un ordinateur analogique sur mesure, le perceptron Mark I. L'équipe de Rosenblatt l'assembla et le testa au Laboratoire aéronautique de Cornell (CAL) à Buffalo, dans l'État de New York, entre juin et le 14 décembre 1959 . Sa première démonstration publique eut lieu le 23 juin 1960. La machine s'inscrivait dans le cadre d'un projet secret de quatre ans mené par le NPIC ( Centre national d'interprétation photographique des États-Unis ) de 1963 à 1966, visant à transformer cet algorithme en un outil utile pour les photo-interprètes.
Rosenblatt a décrit en détail le perceptron dans un article de 1958. Son modèle de perceptron est composé de trois types de cellules (« unités ») : S, A et R, qui signifient respectivement « sensorielle », « association » et « réponse ». Il a présenté ses travaux lors du premier symposium international sur l’IA, intitulé « Mécanisation des processus de pensée », qui s’est tenu en novembre 1958.
Le projet de Rosenblatt a été financé par le contrat Nonr-401(40) « Programme de recherche sur les systèmes cognitifs », qui a duré de 1959 à 1970, et par le contrat Nonr-2381(00) « Projet PARA » (« PARA » signifie « Automates de perception et de reconnaissance »), qui a duré de 1957 à 1963.
En 1959, l'Institute for Defense Analysis a octroyé à son groupe un contrat de 10 000 $. En septembre 1961, l'ONR a octroyé d'autres contrats d'une valeur de 153 000 $, dont 108 000 $ étaient engagés pour 1962.
Le responsable de la recherche à l'ONR, Marvin Denicoff, a déclaré que l'ONR, et non l'ARPA , avait financé le projet Perceptron car il était peu probable que celui-ci produise des résultats technologiques à court ou moyen terme. Les financements de l'ARPA peuvent atteindre plusieurs millions de dollars, tandis que ceux de l'ONR sont de l'ordre de 10 000 dollars. Parallèlement, le directeur de l'IPTO à l'ARPA, JCR Licklider , s'intéressait aux méthodes « auto-organisées », « adaptatives » et autres méthodes bio-inspirées dans les années 1950 ; mais au milieu des années 1960, il les critiquait ouvertement, y compris le perceptron. Il privilégiait en revanche l'approche de l'intelligence artificielle logique de Simon et Newell .
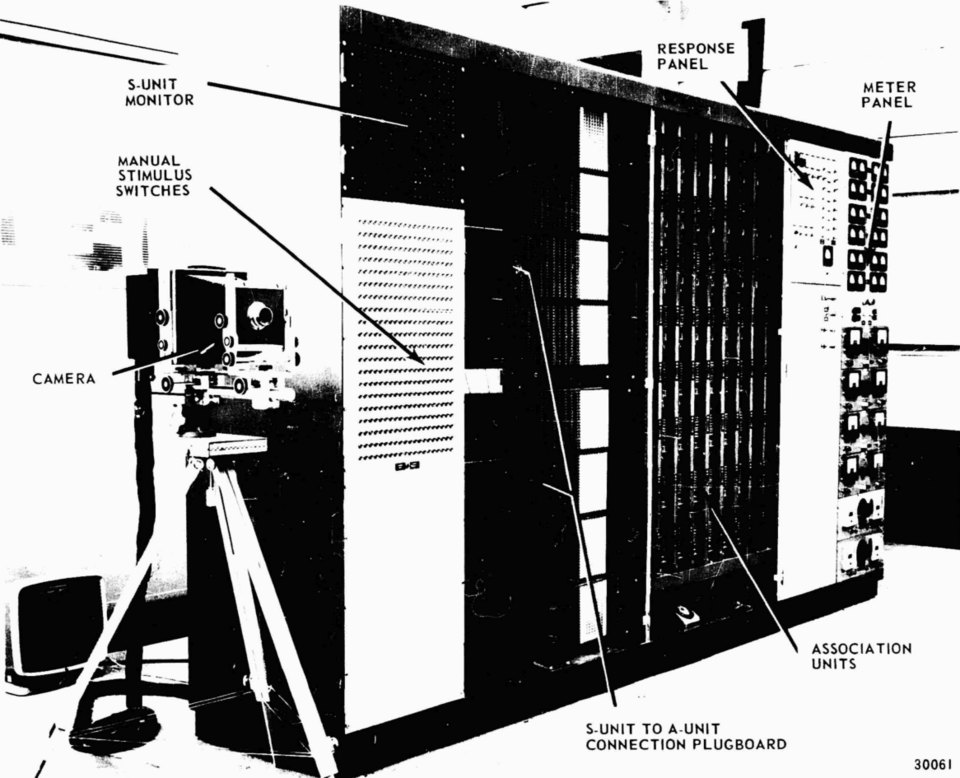
Machine à perceptron Mark I
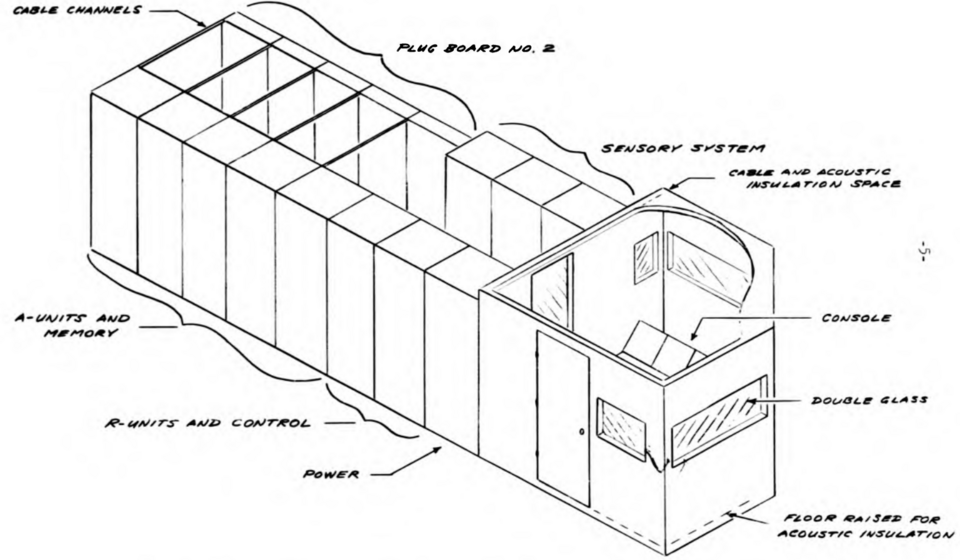
Le perceptron était conçu comme une machine, et non comme un programme. Bien que sa première implémentation ait été logicielle pour l' IBM 704 , il a ensuite été implémenté dans un matériel conçu sur mesure, le perceptron Mark I, dans le cadre du projet « PARA » , destiné à la reconnaissance d'images . Cette machine est actuellement exposée au Musée national d'histoire américaine de la Smithsonian Institution .
Le perceptron Mark I comportait trois couches. Une version a été implémentée comme suit :
- Un ensemble de 400 photocellules disposées en une grille 20x20, appelées « unités sensorielles » (unités S) ou « rétine d’entrée ». Chaque unité S peut être connectée à un maximum de 40 unités A.
- Une couche cachée de 512 perceptrons, appelée « unités d'association » (unités A).
- Une couche de sortie de huit perceptrons, appelée « unités de réponse » (unités R).
Rosenblatt a appelé ce réseau de perceptrons à trois couches l' alpha-perceptron , pour le distinguer des autres modèles de perceptrons avec lesquels il a expérimenté.
Les unités S sont connectées aux unités A de manière aléatoire (selon une table de nombres aléatoires) via un tableau de connexion (voir photo), afin d'« éliminer tout biais intentionnel du perceptron ». Les poids de connexion sont fixes et non appris. Rosenblatt insistait sur l'aléatoire des connexions, car il pensait que la rétine était connectée aléatoirement au cortex visuel et souhaitait que son perceptron reproduise la perception visuelle humaine.
Les unités A sont connectées aux unités R, avec des poids réglables codés dans des potentiomètres , et les mises à jour des poids pendant l'apprentissage ont été effectuées par des moteurs électriques. Les détails matériels sont dans un manuel d'utilisation.
Lors d'une conférence de presse organisée par la marine américaine en 1958, Rosenblatt fit des déclarations sur le perceptron qui provoquèrent une vive controverse au sein de la communauté naissante de l'IA ; se basant sur les déclarations de Rosenblatt, le New York Times rapporta que le perceptron était « l'embryon d'un ordinateur électronique qui [la marine] espère qu'il sera capable de marcher, de parler, de voir, d'écrire, de se reproduire et d'être conscient de son existence ».
La division photographique de la Central Intelligence Agency a étudié, de 1960 à 1964, l'utilisation de la machine Mark I Perceptron pour la reconnaissance de cibles en silhouette d'intérêt militaire (telles que des avions et des navires) dans des photos aériennes .
Principes de neurodynamique (1962)
Rosenblatt a décrit ses expériences avec de nombreuses variantes de la machine Perceptron dans un livre intitulé Principles of Neurodynamics (1962). Ce livre est une version publiée du rapport de 1961.
Parmi les variantes, on trouve :
- « Couplage croisé » (connexions entre unités au sein d'une même couche) avec éventuellement des boucles fermées,
- « rétrocouplage » (connexions d'unités d'une couche ultérieure à des unités d'une couche précédente),
- perceptrons à quatre couches où les deux dernières couches ont des poids ajustables (et donc un véritable perceptron multicouche),
- en intégrant des délais aux unités perceptron, afin de permettre le traitement de données séquentielles,
- analyser l'audio (au lieu des images).
La machine a été expédiée de Cornell au Smithsonian en 1967, dans le cadre d'un transfert gouvernemental administré par l'Office of Naval Research.
Perceptrons (1969)
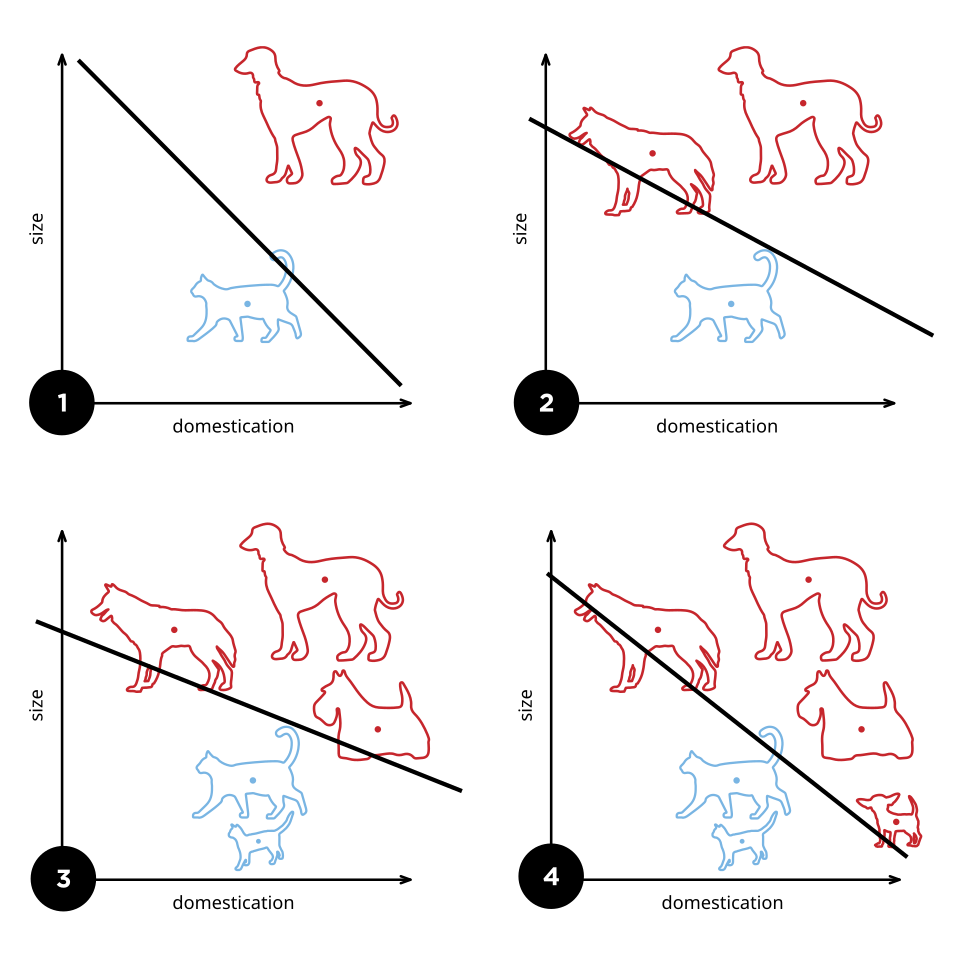
Les perceptrons monocouches ne peuvent apprendre que des motifs linéairement séparables . Pour une tâche de classification avec une fonction d'activation en escalier, un nœud unique possède une seule ligne divisant les points de données qui forment les motifs. Davantage de nœuds peuvent créer davantage de lignes de séparation, mais ces lignes doivent être combinées pour former des classifications plus complexes. Une seconde couche de perceptrons, voire des nœuds linéaires, suffit à résoudre de nombreux problèmes autrement non séparables.
En 1969, un ouvrage célèbre intitulé « Perceptrons » , de Marvin Minsky et Seymour Papert, a démontré l'impossibilité pour ces types de réseaux d'apprendre la fonction XOR . On croit souvent, à tort, qu'ils ont également conjecturé qu'un résultat similaire s'appliquerait aux réseaux de perceptrons multicouches. Or, cela est faux, car Minsky et Papert savaient déjà que les perceptrons multicouches étaient capables de générer une fonction XOR. (Pour plus d'informations, voir la page consacrée aux perceptrons dans l'ouvrage. ) Néanmoins, ce texte de Minsky et Papert, souvent mal interprété, a entraîné un net déclin de l'intérêt et du financement de la recherche sur les réseaux de neurones. Il a fallu attendre dix ans de plus pour que cette recherche connaisse un regain d'intérêt dans les années 1980. Cet ouvrage a été réédité en 1987 sous le titre « Perceptrons - Édition augmentée », où certaines erreurs de la version originale sont corrigées.des noyaux magnétiques toroïdaux . À l'époque de son achèvement, la simulation sur ordinateurs numériques était devenue plus rapide que les machines à perceptrons conçues spécifiquement à cet effet. Il mourut dans un accident de bateau en 1971.
Un programme de simulation pour réseaux neuronaux a été écrit pour IBM 7090/7094 et a été utilisé pour étudier diverses applications de reconnaissance de formes, telles que la reconnaissance de caractères , les trajectoires de particules dans les photographies de chambres à bulles ; la reconnaissance de phonèmes, de mots isolés et de la parole continue ; la vérification du locuteur ; et les mécanismes de centre d'attention pour le traitement d'images .
L' algorithme du perceptron à noyau a été introduit dès 1964 par Aizerman et al. Des garanties de marge ont été fournies pour l'algorithme du perceptron dans le cas général non séparable, d'abord par Freund et Schapire (1998) , puis plus récemment par Mohri et Rostamizadeh (2013), qui ont étendu les résultats précédents et proposé de nouvelles bornes L1 plus favorables.
Le perceptron est un modèle simplifié d'un neurone biologique . Bien que la complexité des modèles de neurones biologiques soit souvent nécessaire pour comprendre pleinement le comportement neuronal, la recherche suggère qu'un modèle linéaire de type perceptron peut produire certains comportements observés dans les neurones réels.
Les espaces de solutions des frontières de décision pour toutes les fonctions binaires et les comportements d'apprentissage sont étudiés dans
Définition
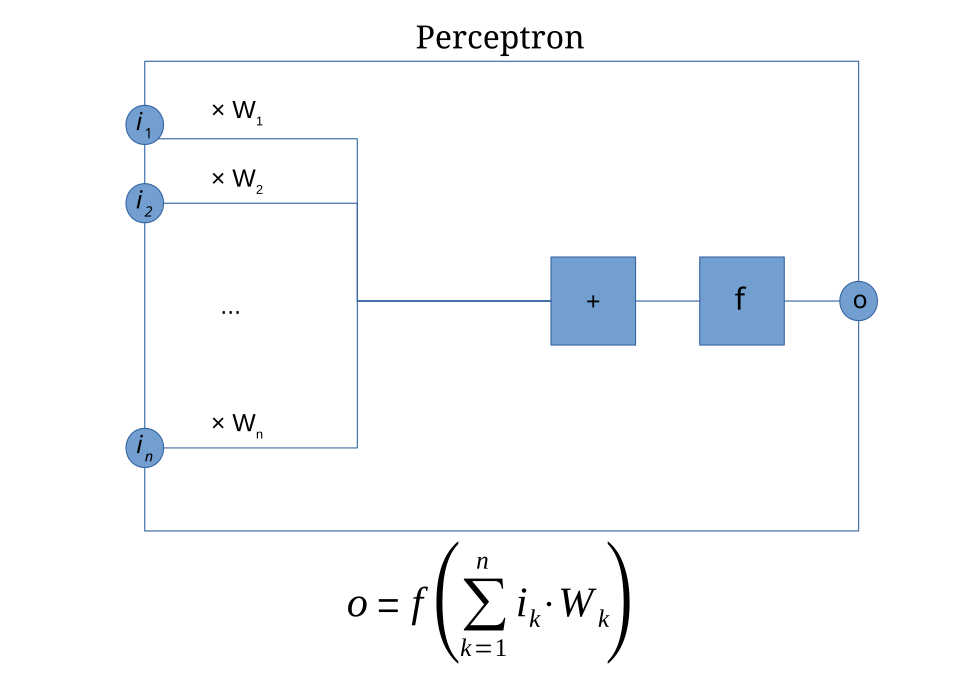
Au sens moderne, le perceptron est un algorithme permettant d'apprendre un classificateur binaire appelé fonction de seuil : une fonction qui associe à son entrée (un vecteur à valeurs réelles ) une valeur de sortie (une seule valeur binaire ) :
où est la fonction de Heaviside (où une entrée vaut 1, la sortie 0 sinon), est un vecteur de poids réels, est le produit scalaire , où
 0
0 La valeur binaire (0 ou 1) est utilisée pour effectuer une classification binaire, l'instance étant considérée comme positive ou négative. Spatialement, le biais modifie la position (mais pas l'orientation) de la frontière de décision plane .
Dans le contexte des réseaux de neurones, un perceptron est un neurone artificiel utilisant la fonction de Heaviside comme fonction d'activation. L'algorithme du perceptron est également appelé perceptron monocouche , afin de le distinguer du perceptron multicouche , terme impropre désignant un réseau de neurones plus complexe. En tant que classificateur linéaire, le perceptron monocouche est le réseau de neurones à propagation directe le plus simple .
Le pouvoir de la représentation
théorie de l'information
Du point de vue de la théorie de l'information , un perceptron unique avec K entrées a une capacité de 2K bits d'information. Ce résultat est dû à Thomas Cover .
Soit le nombre de façons de séparer linéairement N points dans un espace à K dimensions. Lorsque K est grand, ce nombre est très proche de 1 lorsque K ≠ 1 , mais très proche de 0 lorsque K ≠ 0. Autrement dit, une unité de perceptron peut presque certainement mémoriser une attribution aléatoire d'étiquettes binaires à N points lorsque K ≠ 1 , mais presque certainement pas lorsque K ≠ 0 .
 2K
2K fonction booléenne
Lorsqu'il fonctionne uniquement avec des entrées binaires, un perceptron est appelé fonction booléenne linéairement séparable , ou fonction booléenne à seuil. La séquence des nombres de fonctions booléennes à seuil sur n entrées est OEIS A000609 . La valeur n'est connue avec précision qu'à un cas près, mais l'ordre de grandeur est connu avec une grande exactitude : elle possède une borne supérieure et une borne inférieure .
Toute fonction de seuil linéaire booléenne peut être implémentée avec uniquement des poids entiers. De plus, le nombre de bits nécessaires et suffisants pour représenter un seul paramètre de poids entier est de .
théorème d'approximation universelle
Un réseau perceptron à une seule couche cachée peut apprendre à classifier avec une précision arbitraire tout sous-ensemble compact. De même, il peut également approximer avec une précision arbitraire toute fonction continue à support compact . Il s'agit essentiellement d'un cas particulier des théorèmes de George Cybenko et Kurt Hornik .
perceptron local conjonctif
Algorithme d'apprentissage pour un perceptron monocouche
Voici un exemple d'algorithme d'apprentissage pour un perceptron monocouche à une seule unité de sortie. Pour un perceptron monocouche à plusieurs unités de sortie, les poids de chaque unité étant indépendants, le même algorithme peut être appliqué à chacune d'elles.
Pour les perceptrons multicouches , qui comportent une couche cachée, des algorithmes plus sophistiqués, tels que la rétropropagation, doivent être utilisés. Si la fonction d'activation ou le processus sous-jacent modélisé par le perceptron est non linéaire , des algorithmes d'apprentissage alternatifs, comme la règle delta, peuvent être employés à condition que la fonction d'activation soit différentiable . Néanmoins, l'algorithme d'apprentissage décrit ci-dessous fonctionne souvent, même pour les perceptrons multicouches avec des fonctions d'activation non linéaires.
Lorsqu'on combine plusieurs perceptrons dans un réseau neuronal artificiel, chaque neurone de sortie fonctionne indépendamment des autres ; ainsi, l'apprentissage de chaque sortie peut être considéré isolément.
Définitions
Nous définissons d'abord quelques variables :
Nous présentons les valeurs des caractéristiques comme suit :
Pour représenter les poids :
- Parce que , il s'agit effectivement d'un biais que nous utilisons à la place de la constante de biais .
Pour illustrer la dépendance temporelle de , nous utilisons :
Mesures
Pour l'apprentissage hors ligne , la deuxième étape peut être répétée jusqu'à ce que l'erreur d'itération soit inférieure à un seuil d'erreur spécifié par l'utilisateur , ou jusqu'à ce qu'un nombre prédéterminé d'itérations ait été effectué, où s représente à nouveau la taille de l'ensemble d'échantillons.
L'algorithme met à jour les poids après chaque échantillon d'entraînement à l'étape 2b, bien que l'on puisse noter que les poids restent inchangés chaque fois que .
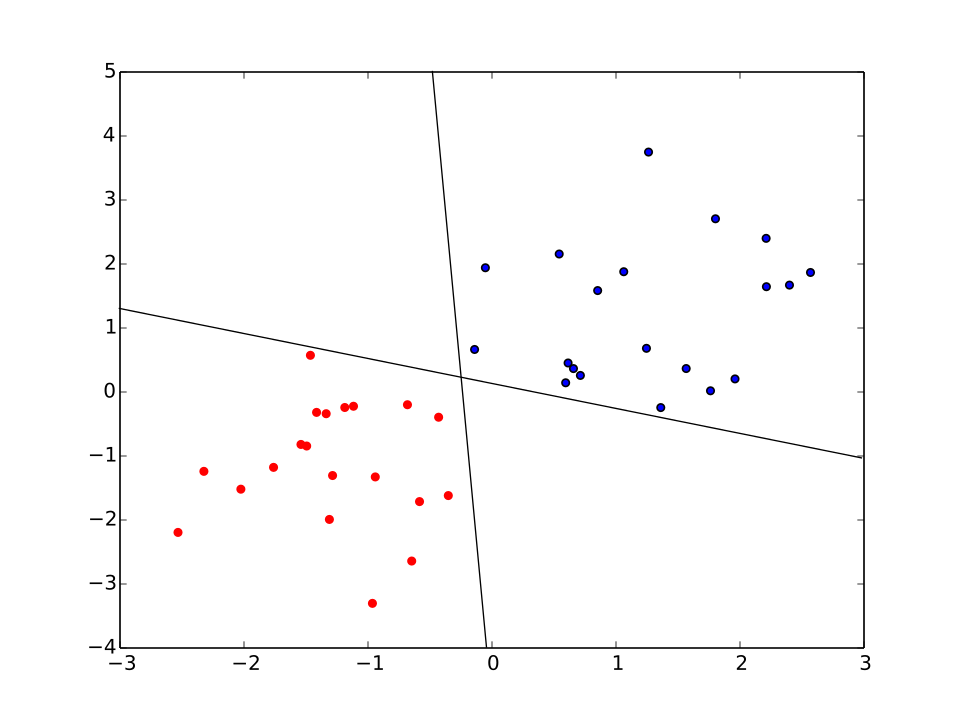
Convergence d'un perceptron sur un ensemble de données linéairement séparables
Un perceptron simple est un classificateur linéaire . Il ne peut atteindre un état stable que si tous les vecteurs d'entrée sont correctement classés. Si l'ensemble d'apprentissage linéairement séparable , c'est-à-dire si les exemples positifs ne peuvent être séparés des exemples négatifs par un hyperplan, l'algorithme ne converge pas puisqu'il n'existe pas de solution. Par conséquent, si la séparabilité linéaire de l'ensemble d'apprentissage n'est pas connue a priori, il convient d'utiliser l'une des variantes d'apprentissage ci-dessous. Une analyse détaillée et des extensions du théorème de convergence sont présentées au chapitre 11 de *Perceptrons* (1969).
La séparabilité linéaire est testable en temps , où est le nombre de points de données et est la dimension de chaque point.
Si l'ensemble d'entraînement est linéairement séparable, alors le perceptron convergera après avoir commis un nombre fini d'erreurs. Le théorème est démontré par Rosenblatt et al.
La démonstration simple qui suit est due à Novikoff (1962). Elle repose sur le fait que le vecteur de pondération est toujours ajusté d'une valeur bornée dans une direction avec laquelle son produit scalaire est négatif , et peut donc être majoré par
Si , l'argument est symétrique, donc nous l'omettons.
WLOG , , puis , , et .
Par hypothèse, nous avons une séparation avec des marges : Ainsi,
De plus , puisque le perceptron a commis une erreur, et donc
Depuis nos débuts , après avoir commis des erreurs, mais aussi
En combinant les deux, nous avons
Bien que l'algorithme du perceptron garantisse la convergence vers une solution dans le cas d'un ensemble d'apprentissage linéairement séparable, il peut néanmoins choisir n'importe quelle solution, et les problèmes peuvent admettre plusieurs solutions de qualité variable. Le perceptron de stabilité optimale , aujourd'hui plus connu sous le nom de machine à vecteurs de support linéaire , a été conçu pour résoudre ce problème (Krauth et Mezard , 1987).
théorème de cyclage du perceptron
Lorsque l'ensemble de données n'est pas linéairement séparable, il est impossible pour un perceptron unique de converger. Cependant, nous disposons toujours de