Les méthodes sont généralement divisées en approches linéaires et non linéaires. Les approches linéaires peuvent être subdivisées en sélection et extraction de caractéristiques . La réduction de dimensionnalité peut être utilisée pour la réduction du bruit , la visualisation des données , l'analyse de regroupement ou comme étape intermédiaire facilitant d'autres analyses.
sélection de caractéristiques vise à trouver un sous-ensemble approprié de variables d'entrée ( caractéristiques ou attributs ) pour la tâche à accomplir. Les trois stratégies sont : la stratégie de filtrage (par exemple, le gain d'information ), la stratégie d'encapsulation (par exemple, la recherche guidée par la précision) et la stratégie intégrée (les caractéristiques sont ajoutées ou supprimées lors de la construction du modèle en fonction des erreurs de prédiction).L'analyse de données telle que la régression ou la classification peut être effectuée dans l'espace réduit avec plus de précision que dans l'espace d'origine.
Projection des caractéristiques
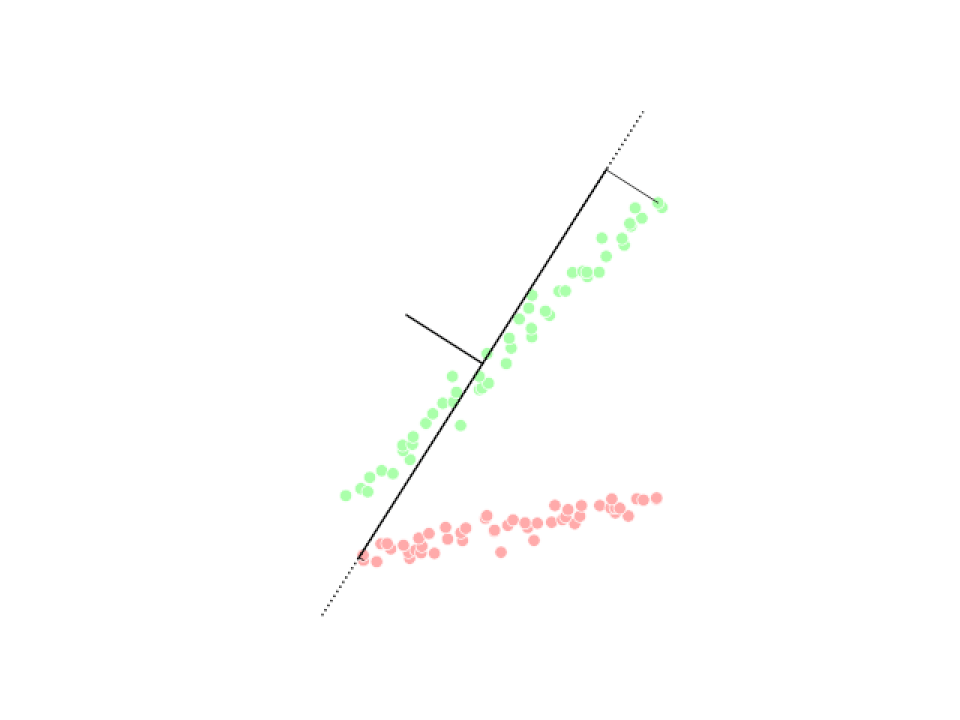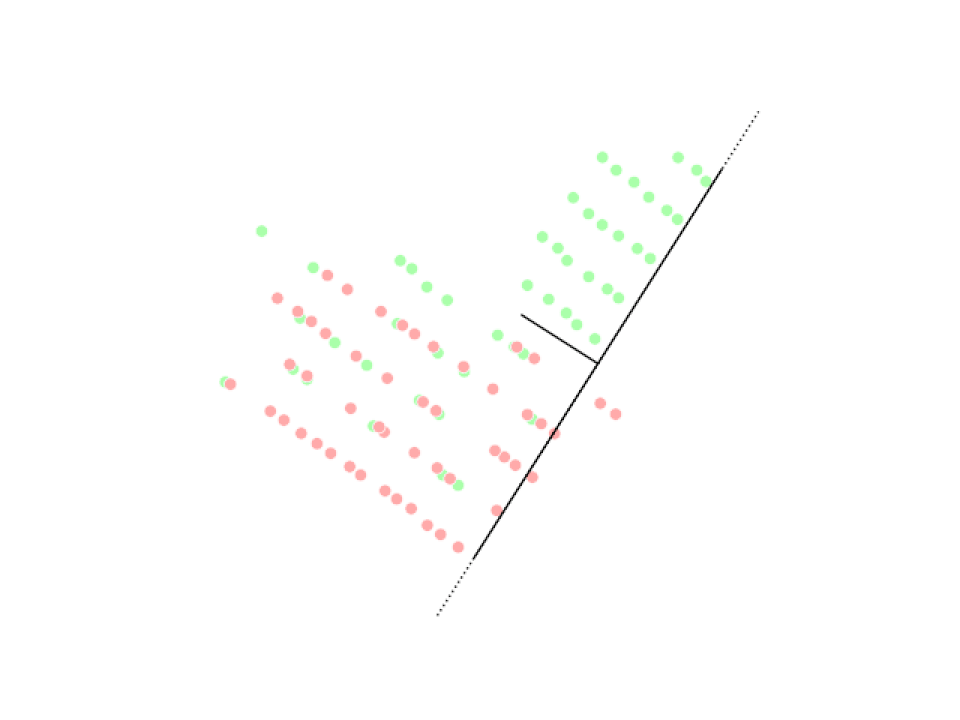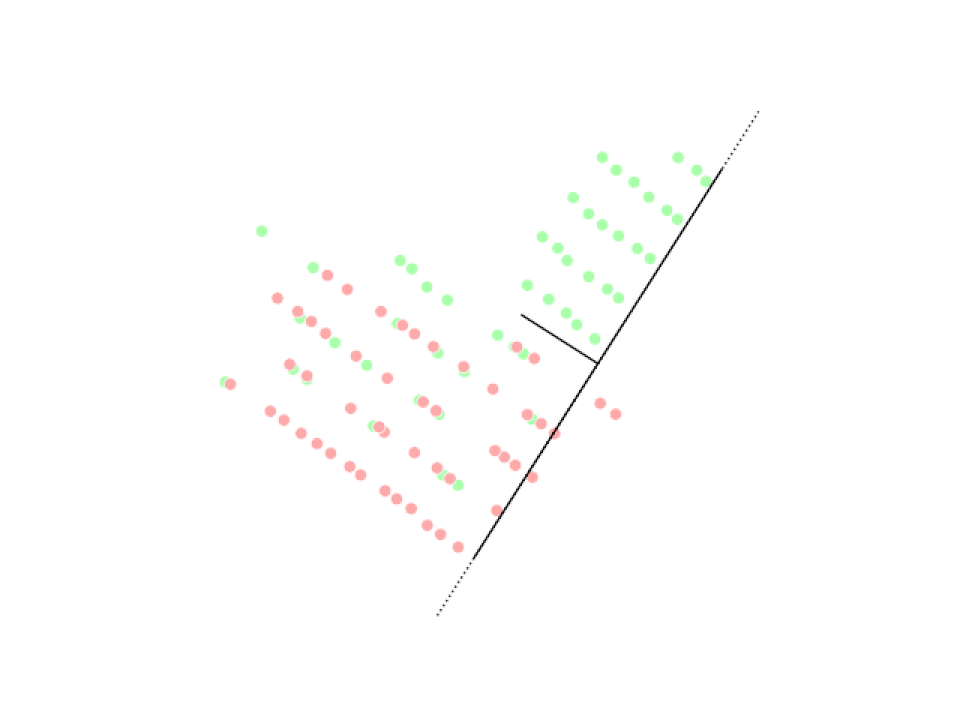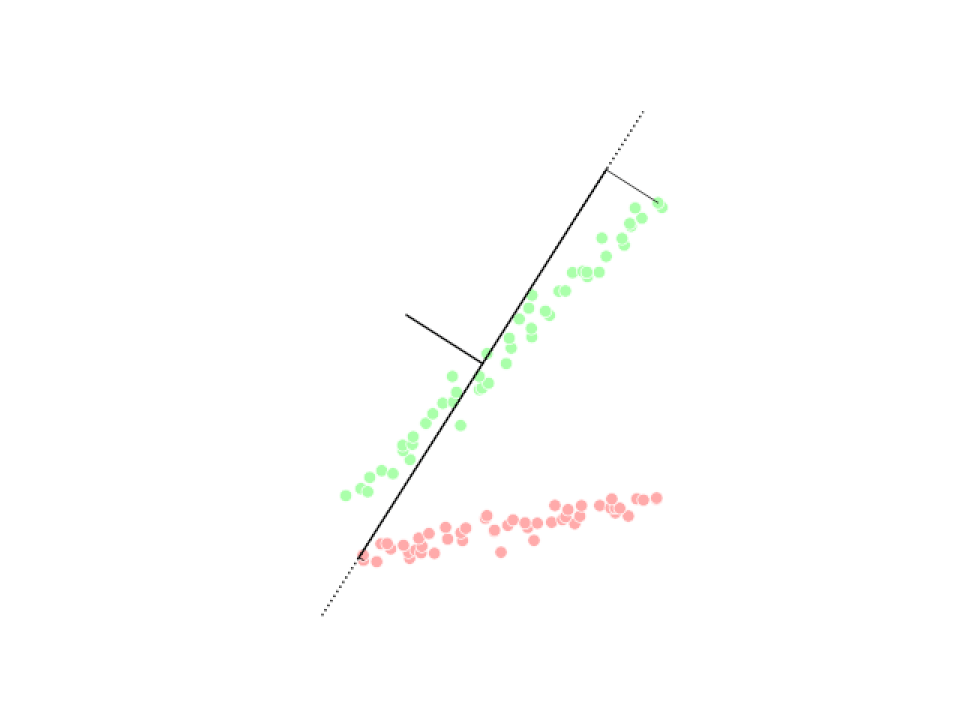
Analyse en composantes principales (ACP)
Grâce à une base de composants stable lors de sa construction et à un processus de modélisation linéaire, la NMF séquentielle permet de préserver le flux lors de l'imagerie directe de structures circumstellaires en astronomie , notamment pour la détection d'exoplanètes , en particulier pour l'imagerie directe de disques circumstellaires . Contrairement à l'ACP, la NMF ne supprime pas la moyenne des matrices, ce qui garantit des flux physiquement non négatifs ; par conséquent, la NMF préserve davantage d'informations que l'ACP, comme l'ont démontré Ren et al.
ACP à noyau
PCA à noyau basée sur un graphe
Parmi les autres techniques non linéaires importantes, on peut citer les techniques d'apprentissage de variétés telles que Isomap , l'intégration linéaire locale (LLE) , la LLE hessienne, les cartes propres laplaciennes et les méthodes basées sur l'analyse de l'espace tangent . Ces techniques supposent que les données d'entrée de grande dimension se situent à proximité d'une variété de faible dimension plongée dans l'espace ambiant et construisent une représentation de faible dimension à l'aide d'une fonction de coût qui préserve les propriétés locales des données ; elles peuvent être vues comme définissant un noyau basé sur un graphe pour l'ACP à noyau
Plus récemment, des techniques ont été proposées qui, au lieu de définir un noyau fixe, tentent d'apprendre le noyau à l'aide de la programmation semi-définie . L'exemple le plus connu de ce type de technique est le déploiement de variance maximale (MVU). L'idée centrale du MVU est de préserver exactement toutes les distances par paires entre les plus proches voisins (dans l'espace préhilbertien) tout en maximisant les distances entre les points qui ne sont pas les plus proches voisins.
Une autre approche pour la préservation du voisinage consiste à minimiser une fonction de coût mesurant les différences de distance entre les espaces d'entrée et de sortie. Parmi les techniques importantes, on peut citer : la mise à l'échelle multidimensionnelle classique (MDS), identique à l'ACP ; Isomap , qui utilise les distances géodésiques dans l'espace des données ; les cartes de diffusion , qui utilisent les distances de diffusion dans l'espace des données ; l'intégration stochastique de voisins à distribution t (t-SNE), qui minimise la divergence entre les distributions sur les paires de points ; et l'analyse en composantes curvilignes.
Une autre approche de la réduction de dimensionnalité non linéaire consiste à utiliser des auto-encodeurs , un type particulier de réseaux neuronaux à propagation avant avec une couche cachée à goulot d'étranglement. L'entraînement des encodeurs profonds est généralement effectué à l'aide d'un pré-entraînement glouton couche par couche (par exemple, à l'aide d'une pile de machines de Boltzmann restreintes ) suivi d'une étape de réglage fin basée sur la rétropropagation .
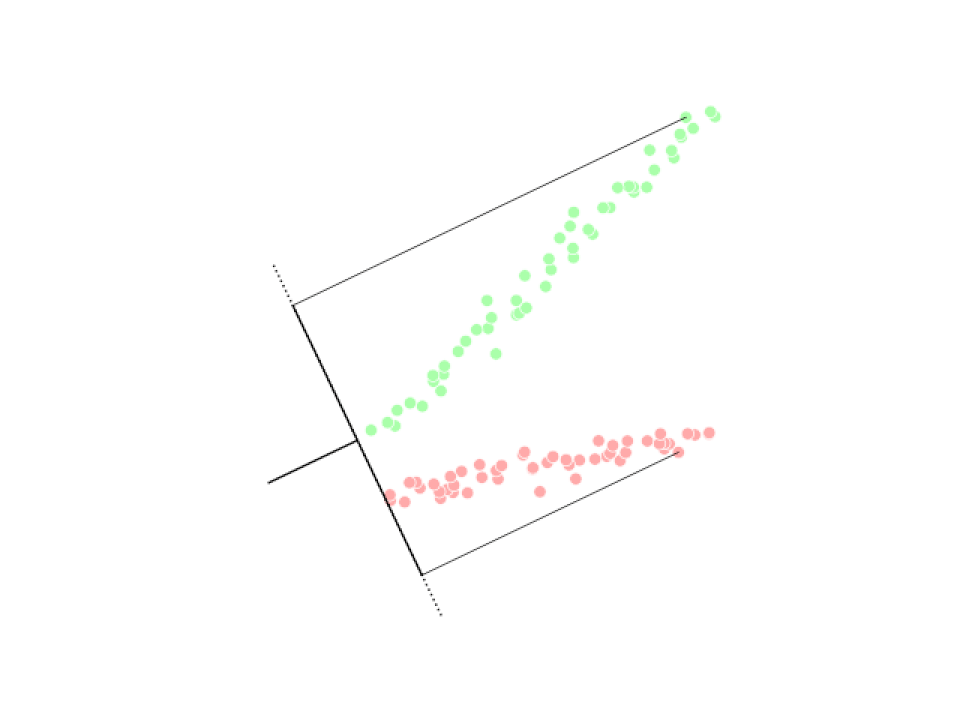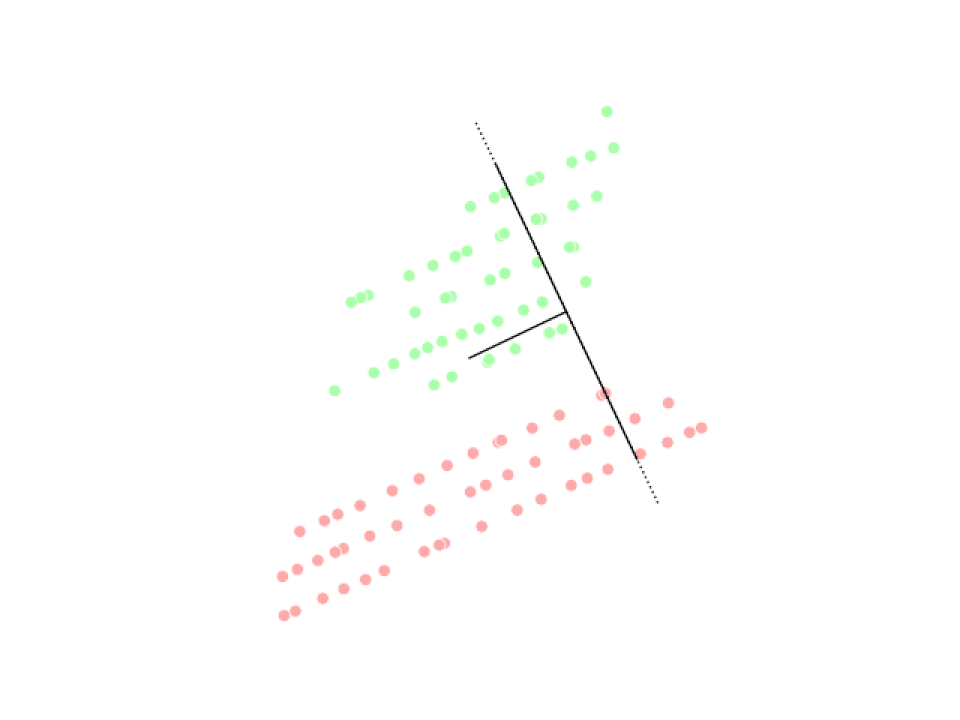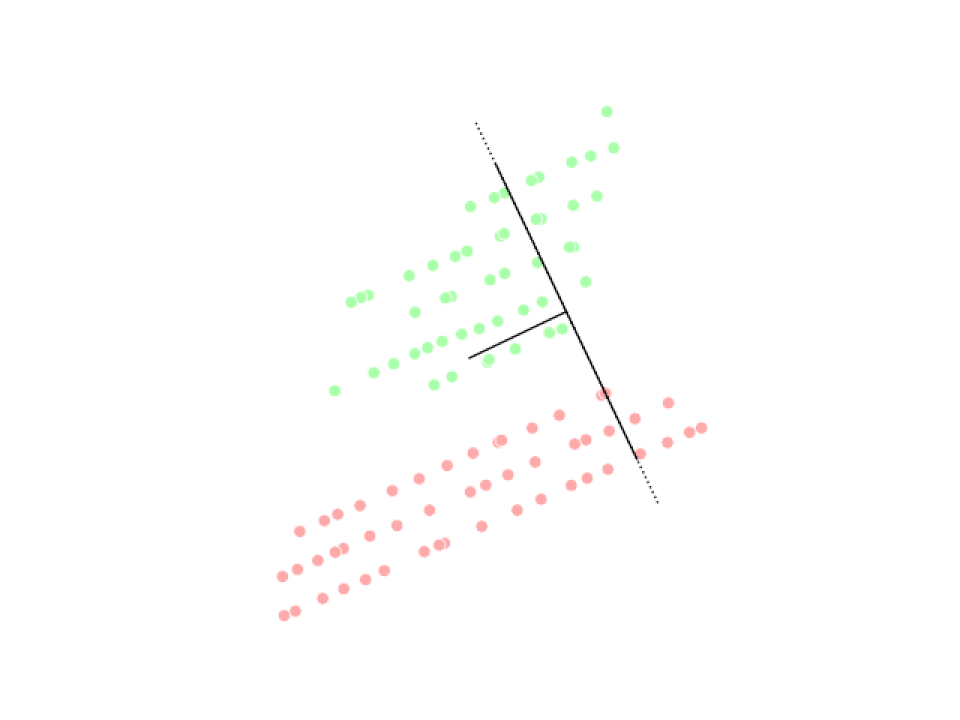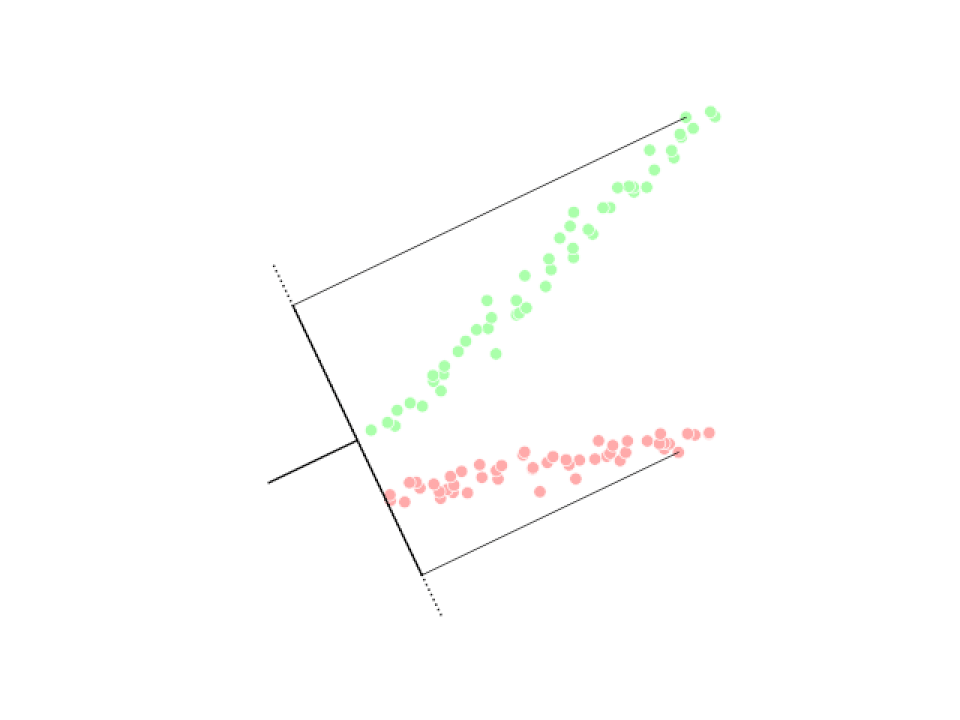
Analyse discriminante linéaire (LDA)
Autoencodeur
Réduction de dimension
Pour les ensembles de données de grande dimension, la réduction de dimension est généralement effectuée avant d'appliquer un algorithme des k plus proches voisins ( k -NN) afin d'atténuer la malédiction de la dimensionnalité .
L’extraction de caractéristiques et la réduction de dimension peuvent être combinées en une seule étape, en utilisant des techniques d’analyse en composantes principales (ACP), d’analyse discriminante linéaire (ADL), d’analyse de corrélation canonique (ACC) ou de factorisation matricielle non négative (FMN) pour prétraiter les données, suivies d’un regroupement par k plus proches voisins ( k -NN) sur les vecteurs de caractéristiques dans un espace de dimension réduite. En apprentissage automatique , ce processus est également appelé plongement de faible dimension .
Pour les ensembles de données de grande dimension (par exemple, lors de la recherche de similarité sur des flux vidéo en direct, des données ADN ou des séries temporelles de grande dimension ), l'exécution d'une recherche k -NN approximative rapide utilisant le hachage sensible à la localité , la projection aléatoire , "croquis", ou d'autres techniques de recherche de similarité de grande dimension de la neurosciences est celle des dimensions maximalement informatives , qui trouve une représentation de dimension inférieure d'un ensemble de données de sorte que le maximum d'informations possible sur les données originales soit préservé.