En apprentissage automatique, la sélection de caractéristiques consiste à choisir un sous-ensemble de caractéristiques pertinentes (variables, prédicteurs) pour la construction du modèle. Les techniques de sélection de caractéristiques sont utilisées pour plusieurs raisons :
- simplification des modèles pour les rendre plus faciles à interpréter,
- des temps d'entraînement plus courts,
- pour éviter la malédiction de la dimensionnalité ,
- améliorer la compatibilité des données avec une certaine classe de modèles d'apprentissage,
- pour encoder les symétries inhérentes présentes dans l'espace d'entrée.
Le principe fondamental de la sélection de caractéristiques repose sur l'idée que les données contiennent parfois des caractéristiques redondantes ou non pertinentes , qui peuvent donc être supprimées sans entraîner de perte d'information significative. Redondance et non-pertinence sont deux notions distinctes, car une caractéristique pertinente peut être redondante en présence d'une autre caractéristique pertinente avec laquelle elle est fortement corrélée.
L'extraction de caractéristiques crée de nouvelles caractéristiques à partir des fonctions des caractéristiques originales, tandis que la sélection de caractéristiques identifie un sous-ensemble de ces caractéristiques. Les techniques de sélection de caractéristiques sont souvent utilisées dans les domaines où le nombre de caractéristiques est élevé et le nombre d'échantillons (points de données) relativement faible.
Introduction
Un algorithme de sélection de caractéristiques peut être vu comme la combinaison d'une technique de recherche pour proposer de nouveaux sous-ensembles de caractéristiques, et d'une mesure d'évaluation qui attribue un score aux différents sous-ensembles. L'algorithme le plus simple consiste à tester chaque sous-ensemble possible de caractéristiques afin de trouver celui qui minimise le taux d'erreur. Cette recherche exhaustive de l'espace est difficilement calculable, sauf pour les ensembles de caractéristiques les plus petits. Le choix de la métrique d'évaluation influence fortement l'algorithme, et ce sont ces métriques qui distinguent les trois principales catégories d'algorithmes de sélection de caractéristiques : les méthodes enveloppantes, les filtres et les méthodes intégrées.
- Les méthodes d'encapsulation utilisent un modèle prédictif pour évaluer des sous-ensembles de caractéristiques. Chaque nouveau sous-ensemble sert à entraîner un modèle, lequel est ensuite testé sur un ensemble de validation. Le nombre d'erreurs commises sur cet ensemble (le taux d'erreur du modèle) détermine le score du sous-ensemble. Comme les méthodes d'encapsulation entraînent un nouveau modèle pour chaque sous-ensemble, elles sont très gourmandes en ressources de calcul, mais offrent généralement le meilleur ensemble de caractéristiques pour ce type de modèle ou ce problème typique.
- Les méthodes de filtrage utilisent une mesure indirecte plutôt que le taux d'erreur pour évaluer un sous-ensemble de caractéristiques. Cette mesure est choisie pour sa rapidité de calcul, tout en préservant l'utilité de l'ensemble de caractéristiques. Parmi les mesures courantes , on trouve l' information mutuelle , l' information mutuelle ponctuelle , le coefficient de corrélation de Pearson , les algorithmes basés sur Relief et la distance inter/intra-classe ou les scores des tests de signification pour chaque combinaison classe/caractéristique . Les filtres sont généralement moins gourmands en ressources de calcul que les méthodes d'encapsulation, mais ils produisent un ensemble de caractéristiques non adapté à un type spécifique de modèle prédictif . Ce manque d'adaptation signifie qu'un ensemble de caractéristiques issu d'un filtre est plus général que celui issu d'une méthode d'encapsulation, ce qui se traduit généralement par des performances de prédiction inférieures. Cependant, cet ensemble de caractéristiques ne contient pas les hypothèses d'un modèle de prédiction et est donc plus utile pour mettre en évidence les relations entre les caractéristiques. De nombreux filtres proposent un classement des caractéristiques plutôt qu'un sous-ensemble explicite des meilleures caractéristiques, et le seuil de ce classement est déterminé par validation croisée . Les méthodes de filtrage sont également utilisées comme étape de prétraitement pour les méthodes d'encapsulation, permettant ainsi d'appliquer ces dernières à des problèmes plus complexes. Une autre approche courante est l'algorithme d'élimination récursive de caractéristiques , fréquemment utilisé avec les machines à vecteurs de support pour construire un modèle de manière itérative et supprimer les caractéristiques ayant un faible poids.
- Les méthodes intégrées regroupent un ensemble de techniques qui effectuent la sélection de caractéristiques lors de la construction du modèle. La méthode LASSO , utilisée pour construire un modèle linéaire, illustre parfaitement cette approche en pénalisant les coefficients de régression par une pénalité L1, ce qui annule un grand nombre d'entre eux. Toute caractéristique ayant un coefficient de régression non nul est « sélectionnée » par l'algorithme LASSO. Parmi les améliorations apportées à LASSO, on peut citer Bolasso, qui utilise le bootstrap pour l'échantillonnage ; la régularisation Elastic Net , qui combine la pénalité L1 de LASSO avec la pénalité L2 de la régression Ridge ; et FeaLect, qui attribue un score à toutes les caractéristiques en fonction d'une analyse combinatoire des coefficients de régression. AEFS étend LASSO aux cas non linéaires grâce à des auto-encodeurs. Ces approches se situent généralement entre les filtres et les méthodes d'encapsulation en termes de complexité de calcul.
En analyse de régression traditionnelle , la méthode de sélection de variables la plus courante est la régression pas à pas , une technique d'encapsulation. Cet algorithme glouton ajoute la meilleure variable (ou supprime la moins performante) à chaque itération. La principale difficulté réside dans la détermination du moment d'arrêt de l'algorithme. En apprentissage automatique, on utilise généralement la validation croisée . En statistique, certains critères sont optimisés, ce qui engendre le problème inhérent d'imbrication. Des méthodes plus robustes ont été explorées, telles que la méthode par séparation et évaluation ( branch and bound) et les réseaux linéaires par morceaux.
sélection de sous-ensemble
La sélection de sous-ensembles évalue la pertinence d'un ensemble de caractéristiques. Les algorithmes de sélection de sous-ensembles se divisent en trois catégories : les méthodes d'encapsulation, les filtres et les méthodes intégrées. Les méthodes d'encapsulation utilisent un algorithme de recherche pour explorer l'espace des caractéristiques potentielles et évaluer chaque sous-ensemble en appliquant un modèle à celui-ci. Ces méthodes peuvent être gourmandes en ressources de calcul et présentent un risque de surapprentissage. Les filtres fonctionnent de manière similaire aux méthodes d'encapsulation, mais au lieu d'être évalués par rapport à un modèle, ils évaluent un filtre plus simple. Les techniques intégrées sont spécifiques à un modèle et y sont intégrées.
De nombreuses méthodes de recherche populaires utilisent l'algorithme glouton de recherche locale , qui évalue itérativement un sous-ensemble candidat de caractéristiques, puis le modifie et vérifie si le nouveau sous-ensemble représente une amélioration par rapport au précédent. L'évaluation des sous-ensembles nécessite une métrique de score qui attribue une note à chaque sous-ensemble de caractéristiques. La recherche exhaustive étant généralement impraticable, à un certain seuil défini par l'implémenteur (ou l'opérateur), le sous-ensemble de caractéristiques ayant obtenu le score le plus élevé jusqu'à ce point est sélectionné comme sous-ensemble satisfaisant. Le critère d'arrêt varie selon l'algorithme ; il peut s'agir, par exemple, du dépassement d'un seuil par le score d'un sous-ensemble ou du dépassement du temps d'exécution maximal autorisé du programme.
Les techniques de recherche alternatives sont basées sur la recherche de projections ciblées qui trouvent des projections de faible dimension des données qui obtiennent un score élevé : les caractéristiques qui ont les plus grandes projections dans l’espace de dimension inférieure sont ensuite sélectionnées.
Les méthodes de recherche comprennent :
- Exhaustif
- Meilleur premier
- Recuit simulé
- Algorithme génétique
- Sélection avant gourmande
- Élimination rétrograde gourmande
- Optimisation par essaim de particules
- Poursuite de projection ciblée
- Recherche dispersée
- Recherche de voisinage variable
Deux métriques de filtrage couramment utilisées pour les problèmes de classification sont la corrélation et l'information mutuelle . Cependant, aucune ne constitue une véritable métrique ou « mesure de distance » au sens mathématique du terme, car elles ne respectent pas l' inégalité triangulaire et ne calculent donc aucune « distance » réelle ; il convient plutôt de les considérer comme des « scores ». Ces scores sont calculés entre une caractéristique candidate (ou un ensemble de caractéristiques) et la catégorie de sortie souhaitée. Il existe néanmoins de véritables métriques qui sont une fonction simple de l'information mutuelle ; voir ici .
Les autres indicateurs de filtrage disponibles incluent :
- séparabilité des classes
- Probabilité d'erreur
- Distance interclasse
- Distance probabiliste
- Entropie
- Sélection de caractéristiques basée sur la cohérence
- Sélection de caractéristiques basée sur la corrélation
Critères d'optimalité
Le choix des critères d'optimalité est complexe, car une tâche de sélection de caractéristiques comporte de multiples objectifs. De nombreux critères courants intègrent une mesure de précision, pénalisée par le nombre de caractéristiques sélectionnées. On peut citer, par exemple, le critère d'information d'Akaike (AIC) et le C<sub> p</sub> de Mallows , qui appliquent une pénalité de 2 pour chaque caractéristique ajoutée. L'AIC repose sur la théorie de l'information et est dérivé du principe d'entropie maximale .
D'autres critères incluent le critère d'information bayésien (BIC), qui utilise une pénalité de pour chaque caractéristique ajoutée, la longueur de description minimale (MDL), qui utilise asymptotiquement , Bonferroni / RIC, qui utilise , la sélection de caractéristiques par dépendance maximale, et divers nouveaux critères inspirés du taux de fausses découvertes (FDR), qui utilisent une valeur proche de . Un critère de taux d'entropie maximal peut également être utilisé pour sélectionner le sous-ensemble de caractéristiques le plus pertinent.
Apprentissage structuré
La sélection de caractéristiques par filtrage est un cas particulier d'un paradigme plus général appelé apprentissage de structure . La sélection de caractéristiques identifie l'ensemble de caractéristiques pertinentes pour une variable cible spécifique, tandis que l'apprentissage de structure détermine les relations entre toutes les variables, généralement en les représentant sous forme de graphe. Les algorithmes d'apprentissage de structure les plus courants supposent que les données sont générées par un réseau bayésien , et que la structure est donc un modèle graphique orienté . La solution optimale au problème de sélection de caractéristiques par filtrage est la couverture de Markov du nœud cible, et dans un réseau bayésien, chaque nœud possède une couverture de Markov unique.
Mécanismes de sélection de caractéristiques basés sur la théorie de l'information
Il existe différents mécanismes de sélection de caractéristiques qui utilisent l'information mutuelle pour évaluer les différentes caractéristiques. Ils utilisent généralement tous le même algorithme :
- Calculez l' information mutuelle sous forme de score entre toutes les caractéristiques ( ) et la classe cible ( c ).
- Sélectionnez la caractéristique ayant le score le plus élevé (par exemple ) et ajoutez-la à l'ensemble des caractéristiques sélectionnées ( S ).
- Calculez le score qui pourrait être déduit de l' information mutuelle
- Sélectionnez la caractéristique ayant le score le plus élevé et ajoutez-la à l'ensemble des caractéristiques sélectionnées (par exemple )
- Répétez les étapes 3 et 4 jusqu'à ce qu'un certain nombre de fonctionnalités soient sélectionnées (par exemple ).
L'approche la plus simple utilise l' information mutuelle comme score « dérivé ».
Il existe cependant différentes approches qui tentent de réduire la redondance entre les fonctionnalités.
sélection de caractéristiques à redondance minimale et pertinence maximale (mRMR)
Peng et al. ont proposé une méthode de sélection de caractéristiques qui peut utiliser l'information mutuelle, la corrélation ou les scores de distance/similarité. L'objectif est de pénaliser la pertinence d'une caractéristique en fonction de sa redondance par rapport aux autres caractéristiques sélectionnées. La pertinence d'un ensemble de caractéristiques S pour la classe c est définie par la valeur moyenne de toutes les informations mutuelles entre la caractéristique individuelle f<sub> i</sub> et la classe c , comme suit :
La redondance de toutes les caractéristiques de l'ensemble S est la valeur moyenne de toutes les valeurs d'information mutuelle entre la caractéristique f i et la caractéristique f j :
Le critère mRMR est une combinaison des deux mesures mentionnées ci-dessus et est défini comme suit :
Supposons qu'il existe n caractéristiques complètes. Soit x <sub>i </sub> la fonction indicatrice d'appartenance à l'ensemble de caractéristiques f <sub>i </sub> , telle que x<sub> i</sub> = 1 indique la présence et x <sub>i</sub> = 0 indique l'absence de la caractéristique f<sub> i</sub> dans l'ensemble de caractéristiques globalement optimal. Soient et . Le problème ci-dessus peut alors être formulé comme un problème d'optimisation :
L'algorithme mRMR est une approximation de l'algorithme de sélection de caractéristiques par dépendance maximale, théoriquement optimal, qui maximise l'information mutuelle entre la distribution conjointe des caractéristiques sélectionnées et la variable de classification. Comme mRMR approxime le problème d'estimation combinatoire par une série de problèmes beaucoup plus petits, chacun impliquant seulement deux variables, il utilise ainsi des probabilités conjointes par paires, plus robustes. Dans certaines situations, l'algorithme peut sous-estimer l'utilité des caractéristiques, car il ne peut mesurer les interactions entre elles susceptibles d'accroître leur pertinence. Cela peut entraîner de faibles performances lorsque les caractéristiques sont individuellement inutiles, mais utiles une fois combinées (un cas pathologique se présente lorsque la classe est une fonction de parité des caractéristiques). Globalement, l'algorithme est plus efficace (en termes de quantité de données requises) que la sélection par dépendance maximale théoriquement optimale, tout en produisant un ensemble de caractéristiques présentant une faible redondance par paires.
mRMR est un exemple d'une vaste classe de méthodes de filtrage qui font des compromis entre pertinence et redondance de différentes manières.
Sélection de caractéristiques de programmation quadratique
mRMR est un exemple typique de stratégie gloutonne incrémentale pour la sélection de caractéristiques : une fois qu’une caractéristique a été sélectionnée, elle ne peut pas être désélectionnée ultérieurement. Bien que mRMR puisse être optimisé à l’aide d’une recherche flottante pour réduire le nombre de caractéristiques, il peut également être reformulé comme un problème d’optimisation quadratique global comme suit :
où représente le vecteur de pertinence des caractéristiques (en supposant qu'il y ait n caractéristiques au total), est la matrice de redondance par paire des caractéristiques, et représente les poids relatifs des caractéristiques. Le QPFS est résolu par programmation quadratique. Il a été récemment démontré que le QFPS est biaisé en faveur des caractéristiques à faible entropie , du fait du placement du terme d'auto-redondance des caractéristiques sur la diagonale de H.
Information mutuelle conditionnelle
Un autre score dérivé de l'information mutuelle est basé sur la pertinence conditionnelle :
où et .
L'un des avantages de SPEC CMI est sa simplicité de résolution, qui consiste à trouver le vecteur propre dominant de Q , ce qui le rend très évolutif. SPEC CMI gère également l'interaction des caractéristiques du second ordre.
Informations mutuelles conjointes
Dans une étude comparant différents scores, Brown et al. ont recommandé l' information mutuelle conjointe comme un bon score pour la sélection de caractéristiques. Ce score vise à identifier la caractéristique qui apporte le plus d'informations nouvelles aux caractéristiques déjà sélectionnées, afin d'éviter les redondances. Il est formulé comme suit :
Le score utilise l' information mutuelle conditionnelle et l' information mutuelle pour estimer la redondance entre les caractéristiques déjà sélectionnées ( ) et la caractéristique étudiée ( ).
Sélection de caractéristiques basée sur le critère d'indépendance de Hilbert-Schmidt et le lasso
Pour les données de grande dimension et de petit échantillon (par exemple, dimensionnalité > 105 et le nombre d'échantillons < 103 ), le Lasso à critère d'indépendance de Hilbert-Schmidt (HSIC Lasso) est utile. Le problème d'optimisation HSIC Lasso est donné comme
où est une mesure d'indépendance basée sur un noyau, appelée critère d'indépendance de Hilbert-Schmidt (HSIC) (empirique), désigne la trace , est le paramètre de régularisation, et sont les matrices de Gram centrées sur l'entrée et la sortie , et sont des matrices de Gram, et sont des fonctions noyau, est la matrice de centrage, est la matrice identité de dimension m ( m : le nombre d'échantillons), est le vecteur de dimension m composé uniquement de 1, et est la norme -norme. Le HSIC prend toujours une valeur non négative, et est nul si et seulement si deux variables aléatoires sont statistiquement indépendantes lorsqu'un noyau reproduisant universel tel que le noyau gaussien est utilisé.
Le lasso HSIC peut s'écrire comme
où désigne la norme de Frobenius . Le problème d'optimisation est un problème Lasso et peut donc être résolu efficacement avec un solveur Lasso de pointe tel que la méthode du lagrangien augmenté dual .
Sélection de caractéristiques de corrélation
La mesure de sélection de caractéristiques par corrélation (CFS) évalue des sous-ensembles de caractéristiques selon l'hypothèse suivante : « Les bons sous-ensembles de caractéristiques contiennent des caractéristiques fortement corrélées à la classification, mais non corrélées entre elles. » L'équation suivante donne la qualité d'un sous-ensemble de caractéristiques S composé de k caractéristiques :
Ici, représente la valeur moyenne de toutes les corrélations caractéristique-classification, et représente la valeur moyenne de toutes les corrélations caractéristique-caractéristique. Le critère CFS est défini comme suit :
Les variables et sont appelées corrélations, mais ne correspondent pas nécessairement au coefficient de corrélation de Pearson ou au ρ de Spearman . La thèse de Hall n'utilise aucun de ces coefficients, mais trois mesures différentes de relation : la longueur de description minimale (MDL), l'incertitude symétrique et le relief .
Soit x i la fonction indicatrice d'appartenance à un ensemble pour la caractéristique f i ; alors ce qui précède peut être réécrit comme un problème d'optimisation :
Les problèmes combinatoires ci-dessus sont en fait des problèmes de programmation linéaire mixte 0-1 qui peuvent être résolus à l'aide d'algorithmes de séparation et d'évaluation .
Arbres régularisés
Il est démontré que les caractéristiques issues d'un arbre de décision ou d'un ensemble d'arbres sont redondantes. Une méthode récente, appelée arbre régularisé permet de sélectionner un sous-ensemble de caractéristiques. Les arbres régularisés pénalisent l'utilisation d'une variable similaire à celles sélectionnées aux nœuds précédents pour la division du nœud courant. Ils ne nécessitent la construction que d'un seul modèle d'arbre (ou d'un seul ensemble d'arbres) et sont donc efficaces en termes de calcul.
Les arbres de décision régularisés gèrent naturellement les variables numériques et catégorielles, les interactions et les non-linéarités. Invariants aux échelles (unités) des attributs et insensibles aux valeurs aberrantes , ils nécessitent peu de prétraitement des données, comme la normalisation . La forêt aléatoire régularisée (RRF) est un type d'arbre de décision régularisé. La RRF guidée est une RRF améliorée, guidée par les scores d'importance d'une forêt aléatoire classique.
Aperçu des méthodes métaheuristiques
Une métaheuristique désigne un algorithme conçu pour résoudre des problèmes d'optimisation difficiles (généralement NP-difficiles ) pour lesquels il n'existe pas de méthodes de résolution classiques. De manière générale, une métaheuristique est un algorithme stochastique qui tend vers un optimum global. Il existe de nombreuses métaheuristiques, allant d'une simple recherche locale à un algorithme de recherche globale complexe.
Principes fondamentaux
Les méthodes de sélection de caractéristiques sont généralement présentées en trois classes selon la manière dont elles combinent l'algorithme de sélection et la construction du modèle.
Méthode de filtrage

Les méthodes de filtrage sélectionnent les variables indépendamment du modèle. Elles se basent uniquement sur des caractéristiques générales, comme la corrélation avec la variable à prédire. Ces méthodes éliminent les variables les moins pertinentes. Les autres variables font partie d'un modèle de classification ou de régression utilisé pour classifier ou prédire les données. Ces méthodes sont particulièrement efficaces en termes de temps de calcul et robustes au surapprentissage .
Les méthodes de filtrage ont tendance à sélectionner des variables redondantes lorsqu'elles ne tiennent pas compte des relations entre les variables. Cependant, des fonctionnalités plus élaborées tentent de minimiser ce problème en supprimant les variables fortement corrélées entre elles, comme l'algorithme Fast Correlation Based Filter (FCBF).
Méthode Wrapper
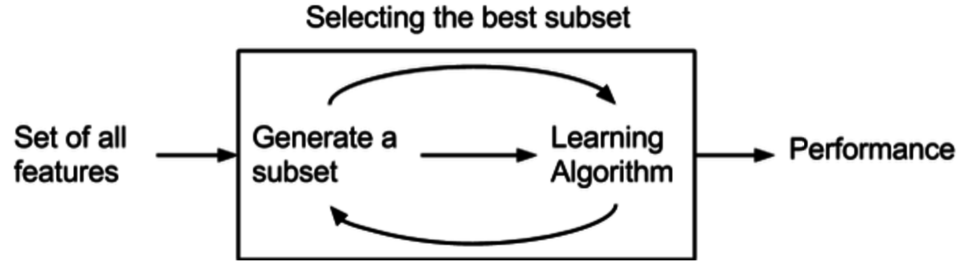
Les méthodes d'encapsulation évaluent des sous-ensembles de variables, ce qui permet, contrairement aux approches de filtrage, de détecter les interactions possibles entre les variables. Les deux principaux inconvénients de ces méthodes sont :
- Le risque de surapprentissage augmente lorsque le nombre d'observations est insuffisant.
- Le temps de calcul est important lorsque le nombre de variables est élevé.
Méthode intégrée
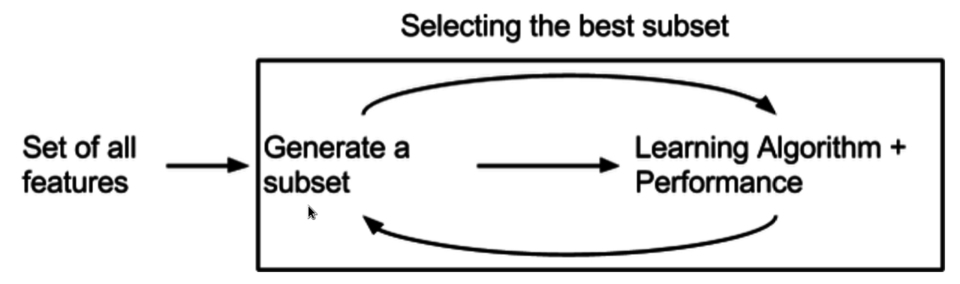
Des méthodes intégrées ont été récemment proposées, qui tentent de combiner les avantages des deux méthodes précédentes. Un algorithme d'apprentissage tire parti de son propre processus de sélection de variables et effectue simultanément la sélection de caractéristiques et la classification, comme l'algorithme FRMT.
Application des métaheuristiques de sélection de caractéristiques
Il s’agit d’une étude des applications récentes des métaheuristiques de sélection de caractéristiques dans la littérature. Cette étude a été réalisée par J. Hammon dans sa thèse de 2013.
| Application | Algorithme | Approche | Classificateur | Fonction d'évaluation | Référence |
|---|---|---|---|---|---|
| SNP | Sélection de caractéristiques par similarité des caractéristiques | Filtre | r 2 | Phuong 2005 | |
| SNP | Algorithme génétique | Emballage | Arbre de décision | Précision de la classification (10 plis) | Shah 2004 |
| SNP | Escalade en montagne | Filtre + Emballage | Bayésien naïf | Somme des carrés des résidus prédits | Long 2007 |
| SNP | Recuit simulé | bayésien naïf | Précision de la classification (5 plis) | Ustunkar 2011 | |
| Segments de libération conditionnelle | colonie de fourmis | Emballage | Réseau neuronal artificiel | MSE | Al-ani 2005 |
| Commercialisation | Recuit simulé | Emballage | Régression | AIC , r² | Meiri 2006 |
| Économie | Recuit simulé, algorithme génétique | Emballage | Régression | BIC | Kapetanios 2007 |
| Masse spectrale | Algorithme génétique | Emballage | Régression linéaire multiple, moindres carrés partiels | erreur quadratique moyenne de prédiction | Broadhurst et al. 1997 |
| Courrier indésirable | PSO binaire + Mutation | Emballage | Arbre de décision | coût pondéré | Zhang 2014 |
| Microréseau | Recherche tabou + PSO | Emballage | Machine à vecteurs de support , k plus proches voisins | Distance euclidienne | Chuang 2009 |
| Microréseau | PSO + Algorithme génétique | Emballage | Machine à vecteurs de support | Précision de la classification (10 plis) | Alba 2007 |
| Microréseau | Algorithme génétique + Recherche locale itérative | Intégré | Machine à vecteurs de support | Précision de la classification (10 plis) | Duval 2009 |
| Microréseau | Recherche locale itérative | Emballage | Régression | Probabilité postérieure | Hans 2007 |
| Microréseau | Algorithme génétique | Emballage | K plus proches voisins | Précision de la classification ( validation croisée Leave-One-Out ) | Jirapech-Umpai 2005 |
| Microréseau | algorithme génétique hybride | Emballage | K plus proches voisins | Précision de la classification (validation croisée Leave-One-Out) | Oh 2004 |
| Microréseau | Algorithme génétique | Emballage | Machine à vecteurs de support | Sensibilité et spécificité | Xuan 2011 |
| Microréseau | Algorithme génétique | Emballage | Machine à vecteurs de support appariée | Précision de la classification (validation croisée Leave-One-Out) | Peng 2003 |
| Microréseau | Algorithme génétique | Intégré | Machine à vecteurs de support | Précision de la classification (10 plis) | Hernandez 2007 |
| Microréseau | Algorithme génétique | Hybride | Machine à vecteurs de support | Précision de la classification (validation croisée Leave-One-Out) | Huerta 2006 |
| Microréseau | Algorithme génétique | Machine à vecteurs de support | Précision de la classification (10 plis) | Muni 2006 | |
| Microréseau | Algorithme génétique | Emballage | Machine à vecteurs de support | EH-DIALL, CLUMP | Jourdan 2005 |
| maladie d'Alzheimer | Test t de Welch | Filtre | Machine à vecteurs de support | Précision de la classification (10 plis) | Zhang 2015 |
| vision par ordinateur | Sélection de fonctionnalités infinie | Filtre | Indépendant | Précision moyenne , AUC ROC | Roffo 2015 |
| Microréseaux | Centralité de vecteur propre FS | Filtre | Indépendant | Précision moyenne, exactitude, aire sous la courbe ROC | Roffo & Melzi 2016 |
| XML | Tau symétrique (ST) | Filtre | Classification structurale associative | Précision, couverture | Shaharanee & Hadzic 2014 |
Sélection de caractéristiques intégrée aux algorithmes d'apprentissage
Certains algorithmes d'apprentissage effectuent une sélection de caractéristiques dans le cadre de leur fonctionnement global. Il s'agit notamment des suivants :
- Les techniques de régularisation α , telles que la régression parcimonieuse, LASSO et α - SVM, sont utilisées .
- Arbres régularisés, par exemple forêt aléatoire régularisée implémentée dans le package RRF
- Arbre de décision
- Algorithme mémétique
- Logit multinomial aléatoire (RMNL)
- Réseaux d'auto-encodage avec une couche de goulot d'étranglement
- Sélection de caractéristiques sous-modulaires
- Sélection de caractéristiques basée sur l'apprentissage local. Contrairement aux méthodes traditionnelles, elle ne nécessite aucune recherche heuristique, gère aisément les problèmes multiclasses et s'applique aux problèmes linéaires et non linéaires. Elle repose par ailleurs sur des fondements théoriques solides. Des expériences numériques ont démontré que cette méthode permet d'obtenir une solution quasi optimale même lorsque les données contiennent plus d'un million de caractéristiques non pertinentes.
- Système de recommandation basé sur la sélection de caractéristiques. Les méthodes de sélection de caractéristiques sont introduites dans la recherche sur les systèmes de recommandation.