La réduction de dimensionnalité non linéaire (RDNL), également appelée apprentissage de variétés , regroupe diverses techniques visant à projeter des données de grande dimension, potentiellement réparties sur des variétés non linéaires ( sous-espaces non affines ) qui ne peuvent être correctement modélisées par des méthodes de décomposition linéaire, sur des variétés latentes de dimension inférieure . L'objectif est soit de visualiser les données dans l'espace de faible dimension, soit d'apprendre la fonction de projection (de l'espace de grande dimension vers l'espace de faible dimension ou inversement). Les techniques décrites ci-dessous peuvent être considérées comme des généralisations des méthodes de décomposition linéaire utilisées pour la réduction de dimensionnalité , telles que la décomposition en valeurs singulières et l'analyse en composantes principales .
Les représentations de données de dimension réduite sont souvent appelées « variables intrinsèques ». Cette appellation sous-entend qu'il s'agit des valeurs à partir desquelles les données ont été générées. Prenons l'exemple d'un ensemble de données contenant des images de la lettre « A », dont l'échelle et la rotation ont varié. Chaque image comporte 32 × 32 pixels et peut être représentée par un vecteur de 1024 valeurs de pixels. Chaque ligne correspond à un échantillon sur une variété bidimensionnelle dans un espace à 1024 dimensions (un espace de Hamming ). La dimensionnalité intrinsèque est de deux, car deux variables (la rotation et l'échelle) ont été modifiées pour produire les données. L'information relative à la forme ou à l'apparence de la lettre « A » ne fait pas partie des variables intrinsèques, car elle est identique pour chaque instance. La réduction de dimensionnalité non linéaire élimine l'information corrélée (la lettre « A ») et ne conserve que l'information variable (la rotation et l'échelle).

En revanche, si l'on utilise l'analyse en composantes principales , un algorithme de réduction de dimensionnalité linéaire, pour réduire ce même ensemble de données à deux dimensions, les valeurs obtenues sont moins bien organisées. Ceci démontre que les vecteurs de grande dimension (représentant chacun la lettre « A ») qui échantillonnent cette variété varient de manière non linéaire.
Il devrait donc être évident que la NLDR trouve plusieurs applications dans le domaine de la vision par ordinateur. Prenons l'exemple d'un robot qui utilise une caméra pour se déplacer dans un environnement statique fermé. Les images obtenues par cette caméra peuvent être considérées comme des échantillons sur une variété dans un espace de grande dimension, et les variables intrinsèques de cette variété représentent la position et l'orientation du robot.
Les variétés invariantes présentent un intérêt général pour la réduction d'ordre des modèles de systèmes dynamiques . En particulier, s'il existe une variété invariante attractive dans l'espace des phases, les trajectoires voisines convergeront vers elle et y resteront indéfiniment, ce qui en fait une candidate pour la réduction de dimensionnalité du système dynamique. Bien que l'existence de telles variétés ne soit pas garantie en général, la théorie des sous-variétés spectrales (SSM) fournit des conditions d'existence d'objets invariants attractifs uniques dans une large classe de systèmes dynamiques. Des recherches actives au NLDR visent à déplier les variétés d'observation associées aux systèmes dynamiques afin de développer des techniques de modélisation.
Voici quelques-unes des techniques de réduction de dimensionnalité non linéaires les plus importantes .
Concepts importants
La cartographie de Sammon
La cartographie de Sammon est l'une des premières et des plus populaires techniques NLDR.
Carte auto-organisatrice
La carte auto-organisatrice (SOM, également appelée carte de Kohonen ) et sa variante probabiliste, la cartographie topographique générative (GTM), utilisent une représentation ponctuelle dans l'espace d'immersion pour former un modèle à variables latentes basé sur une transformation non linéaire de l'espace d'immersion vers l'espace de grande dimension. Ces techniques sont liées aux travaux sur l'ACP à noyau . L'ACP commence par calculer la matrice de covariance de la matrice.
Elle projette ensuite les données sur les k premiers vecteurs propres de cette matrice. Par comparaison, l'ACP à noyau (KPCA) commence par calculer la matrice de covariance des données après leur transformation dans un espace de dimension supérieure.
L'algorithme projette ensuite les données transformées sur les k premiers vecteurs propres de cette matrice, à l'instar de l'ACP. Il utilise l' astuce du noyau pour factoriser une grande partie des calculs, de sorte que l'ensemble du processus peut être réalisé sans calculer explicitement la matrice . Bien entendu , cette matrice doit être choisie de manière à posséder un noyau correspondant connu. Malheureusement, trouver un noyau adapté à un problème donné n'est pas trivial ; par conséquent, l'ACP à noyau (ACP-N) ne donne pas de bons résultats pour certains problèmes lorsqu'elle utilise des noyaux standards. Par exemple, ses performances sont connues pour être médiocres avec ces noyaux sur la variété du rouleau suisse . Cependant, on peut considérer certaines autres méthodes performantes dans de tels contextes (par exemple, les cartes propres laplaciennes, LLE) comme des cas particuliers d'ACP-N, en construisant une matrice de noyau dépendant des données.
KPCA possède un modèle interne, ce qui permet de projeter sur son espace d'intégration des points qui n'étaient pas disponibles lors de l'entraînement.
Courbes et variétés principales
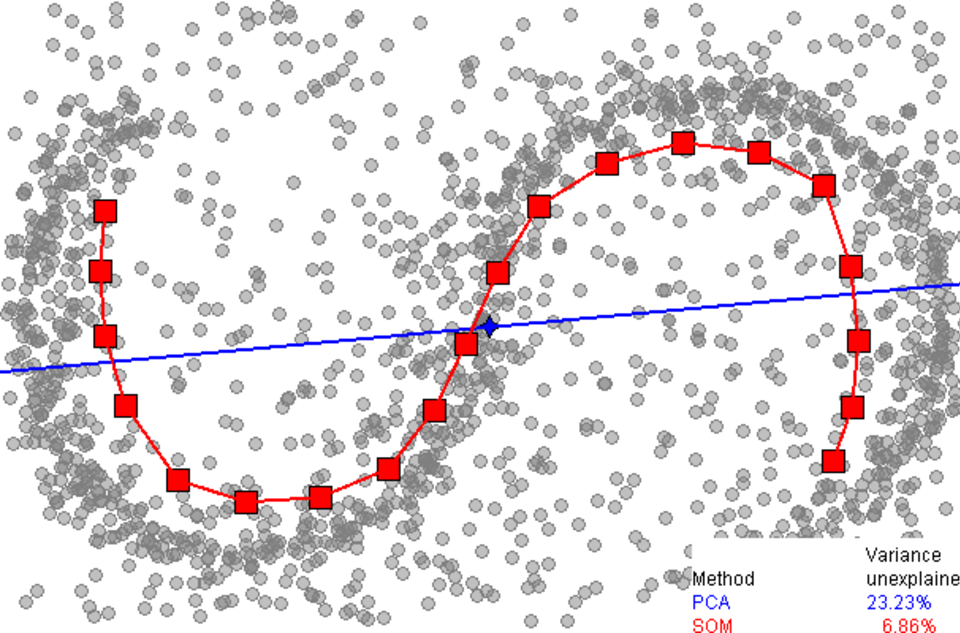
Trevor Hastie dans sa thèse de 1984 , puis formellement introduite en 1989 . De nombreux auteurs ont depuis approfondi cette idée . La définition de la « simplicité » de la variété dépend du problème ; elle est généralement mesurée par sa dimensionnalité intrinsèque et/ou sa régularité. La variété principale est généralement définie comme solution d'un problème d'optimisation. La fonction objectif inclut une approximation de la qualité des données et des pénalités pour la courbure de la variété. Les approximations initiales couramment utilisées sont générées par l'ACP linéaire et la carte auto-organisatrice de Kohonen (SOM).
Cartes propres laplaciennes
Les techniques traditionnelles, comme l'analyse en composantes principales, ne tiennent pas compte de la géométrie intrinsèque des données. Les cartes propres laplaciennes construisent un graphe à partir des informations de voisinage des points de l'ensemble de données. Chaque point de données constitue un nœud du graphe, et la connectivité entre les nœuds est déterminée par la proximité des points voisins (par exemple, à l'aide de l' algorithme des k plus proches voisins ). Le graphe ainsi généré peut être considéré comme une approximation discrète de la variété de faible dimension dans l'espace de grande dimension. La minimisation d'une fonction de coût basée sur le graphe garantit que les points proches les uns des autres sur la variété sont projetés proches les uns des autres dans l'espace de faible dimension, préservant ainsi les distances locales. Les fonctions propres de l' opérateur de Laplace-Beltrami sur la variété servent de dimensions d'immersion, car, sous certaines conditions, cet opérateur possède un spectre dénombrable qui constitue une base des fonctions de carré intégrable sur la variété (à comparer aux séries de Fourier sur le cercle unité ). Les tentatives visant à placer les cartes propres laplaciennes sur des bases théoriques solides ont rencontré un certain succès, car sous certaines hypothèses non restrictives, il a été démontré que la matrice laplacienne du graphe converge vers l'opérateur de Laplace-Beltrami lorsque le nombre de points tend vers l'infini.
Isomap
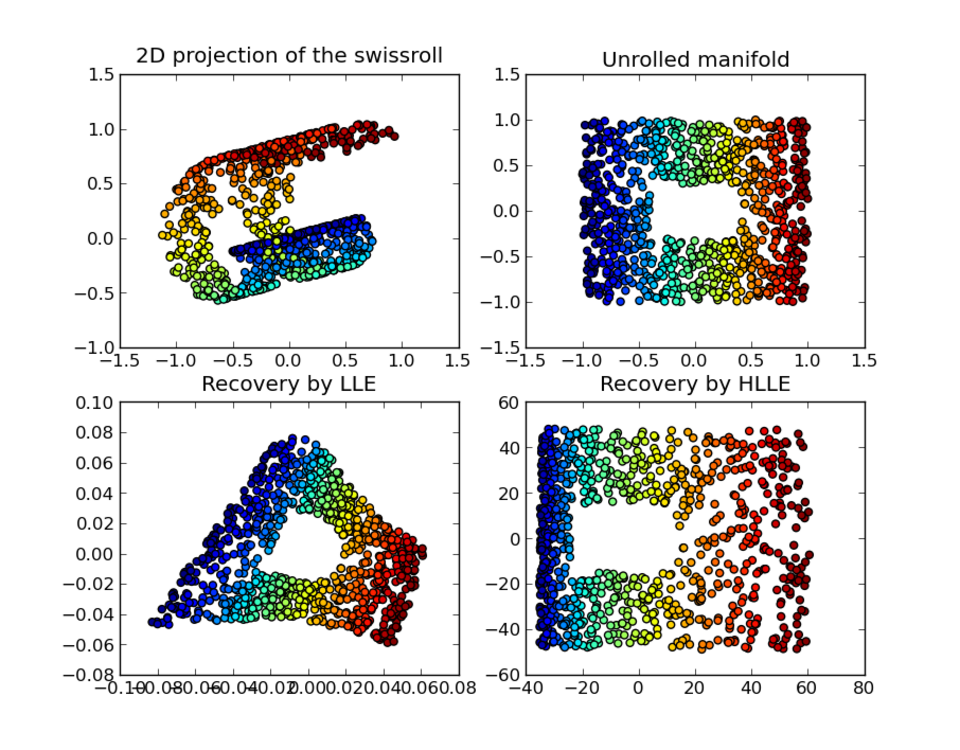
Isomap combine l' algorithme de Floyd-Warshall avec la mise à l'échelle multidimensionnelle (MDS) classique. La MDS classique utilise une matrice des distances par paires entre tous les points et calcule la position de chaque point. Isomap suppose que les distances par paires ne sont connues qu'entre points voisins et utilise l'algorithme de Floyd-Warshall pour calculer les distances par paires entre tous les autres points. Ceci permet d'estimer la matrice complète des distances géodésiques par paires entre tous les points. Isomap utilise ensuite la MDS classique pour calculer les positions de dimension réduite de tous les points. Landmark-Isomap est une variante de cet algorithme qui utilise des points de repère pour accélérer le calcul, au détriment de la précision.
En apprentissage de variétés, les données d'entrée sont supposées être échantillonnées à partir d'une variété de faible dimension plongée dans un espace vectoriel de dimension supérieure . L'idée principale de l'apprentissage de variétés multiples (MVU) est d'exploiter la linéarité locale des variétés et de créer une application qui préserve les voisinages locaux en chaque point de la variété sous-jacente.
Intégration localement linéaire
de matrices creuses , et de meilleurs résultats pour de nombreux problèmes. LLE commence également par trouver l'ensemble des plus proches voisins de chaque point. Elle calcule ensuite un ensemble de poids pour chaque point, qui le décrit au mieux comme une combinaison linéaire de ses voisins. Enfin, elle utilise une technique d'optimisation basée sur les vecteurs propres pour trouver l'intégration de faible dimension des points, de sorte que chaque point soit toujours décrit par la même combinaison linéaire de ses voisins. LLE a tendance à mal gérer les densités d'échantillonnage non uniformes, car il n'y a pas d'unité fixe pour empêcher les poids de dériver lorsque les densités d'échantillonnage varient selon les régions. LLE ne possède pas de modèle interne.
Les points de données originaux , et l'objectif de LLE est d'intégrer chaque point à un point de faible dimension , où .
L'algorithme LLE comporte deux étapes. Dans la première , il calcule, pour chaque point X<sub> i</sub> , la meilleure approximation de X<sub> i</sub> à partir des coordonnées barycentriques de ses voisins X<sub> j</sub> . Le point original est approximativement reconstruit par une combinaison linéaire, donnée par la matrice de pondération W<sub> ij</sub> , de ses voisins. L'erreur de reconstruction est :
Les poids W<sub> ij</sub> font référence à la contribution du point X<sub> j </sub> à la reconstruction du point X<sub> i</sub> . La fonction de coût est minimisée sous deux contraintes :
- Chaque point de données X i est reconstruit uniquement à partir de ses voisins. Autrement dit, si le point X j n'est pas un voisin du point X i .
- La somme de chaque ligne de la matrice de poids est égale à 1, c'est-à-dire .
Ces deux contraintes garantissent que la fonction n'est pas affectée par la rotation et la translation.
Dans un second temps, une carte préservant le voisinage est créée en fonction des pondérations. Chaque point est associé à un autre point en minimisant un coût supplémentaire :
Contrairement à la fonction de coût précédente, les poids W<sub> ij</sub> sont fixes et la minimisation est effectuée sur les points Y<sub> i</sub> afin d'optimiser les coordonnées. Ce problème de minimisation peut être résolu en résolvant un problème de valeurs propres creux N × N ( N étant le nombre de points de données), dont les d vecteurs propres non nuls inférieurs fournissent un système de coordonnées orthogonal.
Le seul hyperparamètre de l'algorithme définit ce qui est considéré comme un « voisin » d'un point. Généralement, les points de données sont reconstruits à partir de leurs K plus proches voisins, selon la distance euclidienne . Dans ce cas, l'algorithme ne possède qu'un seul hyperparamètre entier K, qui peut être déterminé par validation croisée.
Intégration localement linéaire hessienne (Hessian LLE)
Tout comme LLE, projection orthogonale locale des pondérations originales produites par LLE. Les créateurs de cette variante régularisée sont également les auteurs de l'alignement local des espaces tangents (LTSA), implicite dans la formulation MLLE. En effet, l'optimisation globale des projections orthogonales de chaque vecteur de pondération aligne, de fait, les espaces tangents locaux de chaque point de données. Les implications théoriques et empiriques d'une application correcte de cet algorithme sont considérables.
Alignement local de l'espace tangent
Déploiement de la variance maximale
Les algorithmes Maximum Variance Unfolding , Isomap et Locally Linear Embedding partagent une intuition commune : si une variété est correctement dépliée, la variance sur ses points est maximisée. Comme pour Isomap et Locally Linear Embedding, la première étape consiste à trouver les k plus proches voisins de chaque point. L'algorithme cherche ensuite à maximiser la distance entre tous les points non voisins, tout en préservant les distances entre points voisins. Sa principale contribution réside dans sa capacité à formuler ce problème comme un problème de programmation semi-définie . Malheureusement, les solveurs de programmation semi-définie sont coûteux en calcul. À l'instar de Locally Linear Embedding, il ne possède pas de modèle interne.
Auto-encodeurs
Un autoencodeur est un réseau de neurones à propagation avant entraîné à approximer la fonction identité . Autrement dit, il est entraîné à transformer un vecteur de valeurs en ce même vecteur. Lorsqu'il est utilisé pour la réduction de dimensionnalité, l'une des couches cachées du réseau est limitée à un petit nombre d'unités. Le réseau doit donc apprendre à encoder le vecteur dans un espace de dimension réduite, puis à le décoder pour le ramener à son espace d'origine. Ainsi, la première moitié du réseau est un modèle qui transforme un espace de grande dimension en un espace de faible dimension, et la seconde moitié, un espace de faible dimension en un espace de grande dimension. Bien que le concept d'autoencodeurs soit ancien l'entraînement d'autoencodeurs profonds n'est devenu possible que récemment grâce à l'utilisation de machines de Boltzmann restreintes et d'autoencodeurs débruiteurs empilés. L' algorithme mise à l'échelle multidimensionnelle et des transformations de Sammon (voir ci-dessus) pour apprendre une transformation non linéaire de l'espace de grande dimension vers l'espace plongé. Les cartographies de NeuroScale sont basées sur des réseaux de fonctions de base radiales .
Modèles de variables latentes à processus gaussien
processus gaussien ). Cependant, dans les GPLVM, l'application se fait de l'espace latent vers l'espace des données (comme les réseaux de densité et les GTM), tandis que dans l'ACP à noyau, elle se fait dans le sens inverse. Initialement proposés pour la visualisation de données de grande dimension, les GPLVM ont été étendus à la construction d'un modèle de variété partagée entre deux espaces d'observation. Le modèle GPLVM et ses nombreuses variantes ont été spécialement conçus pour la modélisation du mouvement humain, par exemple le GPLVM à contraintes arrière, le modèle dynamique GP (GPDM), le GPDM équilibré (B-GPDM) et le GPDM à contraintes topologiques. Afin de prendre en compte le couplage entre les variétés de pose et de démarche dans l'analyse de la démarche, une variété de pose-démarche articulaire multicouche a été proposée.
Autres algorithmes
Carte de perspective relationnelle
La carte de perspective relationnelle est un algorithme de mise à l'échelle multidimensionnelle . Cet algorithme détermine une configuration de points de données sur une variété en simulant un système dynamique multiparticulaire sur une variété fermée. Dans ce système, les points de données sont représentés par des particules et les distances (ou dissimilarités) entre eux correspondent à une force de répulsion. À mesure que la variété s'agrandit, le système multiparticulaire se refroidit progressivement et converge vers une configuration qui reflète les distances entre les points de données.
La carte de perspective relationnelle s'inspire d'un modèle physique où des particules chargées positivement se déplacent librement à la surface d'une sphère. Guidée par la force de Coulomb entre les particules, la configuration d'énergie minimale de ces dernières reflète l'intensité des forces de répulsion qui s'exercent entre elles.
La carte de perspective relationnelle a été introduite dans . L'algorithme utilisait d'abord le tore plat comme variété image, puis il a été étendu (dans le logiciel VisuMap) pour utiliser d'autres types de variétés fermées, comme la sphère , l'espace projectif et la bouteille de Klein , comme variétés images.
Cartes de contagion
Les cartes de contagion utilisent plusieurs contagions sur un réseau pour représenter les nœuds sous forme de nuage de points. Dans le cas du modèle de cascades globales, la vitesse de propagation peut être ajustée à l'aide du paramètre de seuil . La carte de contagion est alors équivalente à l' algorithme Isomap .
Analyse des composantes curvilignes
la cartographie de Sammon qui se concentre sur les petites distances dans l'espace d'origine).
Il convient de noter que l'analyse canonique des corrélations (CCA), en tant qu'algorithme d'apprentissage itératif, commence par se concentrer sur les grandes distances (comme l'algorithme de Sammon), puis se concentre progressivement sur les petites distances. Les informations relatives aux petites distances prévalent sur celles relatives aux grandes distances si des compromis doivent être trouvés entre les deux.
La fonction de stress de CCA est liée à une somme de divergences de Bregman à droite.
Analyse de distance curviligne
CDA entraîne un réseau de neurones auto-organisateur pour ajuster la variété et cherche à préserver les distances géodésiques dans son plongement. Il est basé sur l'analyse en composantes curvilignes (qui étend la cartographie de Sammon), mais utilise les distances géodésiques.
Réduction de dimensionnalité difféomorphique
La réduction de dimensionnalité difféomorphique, ou Diffeomap apprend une application difféomorphique lisse qui transporte les données sur un sous-espace linéaire de dimension inférieure. Cette méthode détermine un champ vectoriel lisse indexé par le temps, de sorte que les flux le long de ce champ, partant des points de données, aboutissent dans un sous-espace linéaire de dimension inférieure. Elle tente ainsi de préserver les différences deux à deux lors des applications directe et inverse.
Alignement de la variété
L’alignement de variétés exploite l’hypothèse selon laquelle des ensembles de données disparates, produits par des processus générateurs similaires, partagent une représentation de variété sous-jacente similaire. En apprenant les projections de chaque espace d’origine vers la variété partagée, des correspondances sont établies et les connaissances d’un domaine peuvent être transférées à un autre. La plupart des techniques d’alignement de variétés ne considèrent que deux ensembles de données, mais le concept s’étend à un nombre arbitraire d’ensembles de données initiaux.
Cartes de diffusion
Les applications de diffusion exploitent la relation entre la diffusion de la chaleur et une marche aléatoire ( chaîne de Markov ) ; une analogie est établie entre l’opérateur de diffusion sur une variété et une matrice de transition markovienne agissant sur des fonctions définies sur le graphe dont les nœuds ont été échantillonnés à partir de la variété. En particulier, soit un ensemble de données représenté par . L’hypothèse sous-jacente de l’application de diffusion est que les données de grande dimension se trouvent sur une variété de faible dimension de dimension . Soit X l’ensemble de données et la distribution des points de données sur X. Définissons de plus un noyau qui représente une certaine notion d’affinité des points de X. Le noyau possède les propriétés suivantes
k est symétrique
k préserve la positivité
On peut ainsi considérer les points de données individuels comme les nœuds d'un graphe et le noyau k comme définissant une forme d'affinité sur ce graphe. Le graphe est symétrique par construction, puisque le noyau l'est également. Il est aisé de constater qu'à partir du couple ( X , k ), on peut construire une chaîne de Markov réversible . Cette technique, courante dans de nombreux domaines, est connue sous le nom de laplacien du graphe.
Par exemple, le graphe K = ( X , E ) peut être construit à l'aide d'un noyau gaussien.
Dans l'équation ci-dessus, désigne le plus proche voisin de . En réalité, la distance géodésique devrait être utilisée pour mesurer les distances sur la variété . La structure exacte de la variété étant inconnue, la distance géodésique est approchée par la distance euclidienne pour les plus proches voisins. Le choix de module notre notion de proximité : si , alors , et si , alors . Dans le premier cas, la diffusion est très faible ; dans le second, elle est quasi complète. Différentes stratégies de choix de sont présentées dans
Pour représenter fidèlement une matrice de Markov, il faut la normaliser par la matrice des degrés correspondante :
La matrice de Markov représente une certaine notion de géométrie locale de l'ensemble de données X. La principale différence entre les cartes de diffusion et l'analyse en composantes principales réside dans le fait que les cartes de diffusion ne prennent en compte que les caractéristiques locales des données, contrairement à l'analyse en composantes principales qui considère les corrélations de l'ensemble des données.
Pour une valeur de t fixée, cette distance définit une distance entre deux points quelconques de l'ensemble de données en fonction de la connectivité des chemins : sa valeur est d'autant plus petite que le nombre de chemins reliant x à y ( et inversement) est élevé. Comme cette quantité implique une somme sur tous les chemins de longueur t, elle est beaucoup plus robuste au bruit dans les données que la distance géodésique. Elle prend en compte toutes les relations entre les points x et y lors du calcul de la distance et constitue une meilleure notion de proximité que la simple distance euclidienne , voire même que la distance géodésique.
Mise à l'échelle multidimensionnelle locale
La mise à l'échelle multidimensionnelle locale effectue une mise à l'échelle multidimensionnelle dans des régions locales, puis utilise une optimisation convexe pour assembler tous les éléments.
ACP non linéaire
L'ACP non linéaire (NLPCA) utilise la rétropropagation pour entraîner un perceptron multicouche (MLP) à s'ajuster à une variété. Contrairement à l'entraînement classique d'un MLP, qui ne met à jour que les poids, la NLPCA met à jour à la fois les poids et les entrées. Autrement dit, les poids et les entrées sont considérés comme des valeurs latentes. Après l'entraînement, les entrées latentes constituent une représentation de faible dimension des vecteurs observés, et le MLP effectue une projection de cette représentation de faible dimension vers l'espace d'observation de haute dimension.
Mise à l'échelle multidimensionnelle basée sur les données
La mise à l'échelle de haute dimension pilotée par les données (DD-HDS) est étroitement liée à la cartographie de Sammon et à l'analyse des composantes curvilignes, sauf que (1) elle pénalise simultanément les faux voisinages et les déchirures en se concentrant sur les petites distances dans l'espace d'origine et l'espace de sortie, et que (2) elle tient compte du phénomène de concentration de la mesure en adaptant la fonction de pondération à la distribution des distances.
Sculpture de collecteur
Manifold Sculpting utilise une optimisation progressive pour trouver un plongement. Comme d'autres algorithmes, il calcule les k plus proches voisins et cherche un plongement préservant les relations au sein des voisinages locaux. Il réduit progressivement la variance des dimensions supérieures, tout en ajustant simultanément les points des dimensions inférieures afin de préserver ces relations. Avec un faible taux de réduction, il peut trouver des plongements très précis. Il affiche une précision empirique supérieure à celle d'autres algorithmes sur plusieurs points. Il peut également servir à affiner les résultats d'autres algorithmes d'apprentissage de variétés. Cependant, il peine à déplier certaines variétés, sauf si un taux de réduction très lent est utilisé. Il ne possède pas de modèle.
RankVisu
RankVisu est conçu pour préserver le rang du voisinage plutôt que la distance. RankVisu est particulièrement utile pour les tâches complexes (lorsque la préservation de la distance est impossible à obtenir de manière satisfaisante). En effet, le rang du voisinage est moins informatif que la distance (les rangs peuvent être déduits des distances, mais l'inverse n'est pas vrai) et sa préservation est donc plus aisée.
plongement isométrique à contraintes topologiques
majoration des contraintes pondérées qui suit.
plongement stochastique de voisins distribués t
L'algorithme t -SNE (t- distributed stochastic neighbor embedding ) est largement utilisé. Il fait partie de la famille des méthodes d'intégration stochastique de voisins. Cet algorithme calcule la probabilité que des paires de points de données dans un espace de grande dimension soient liées, puis sélectionne des représentations de faible dimension produisant une distribution similaire.
Approximation et projection sur une variété uniforme
L'approximation et la projection uniformes de variétés (UMAP) est une technique de réduction de dimensionnalité non linéaire. Elle fonctionne de manière similaire au t-SNE , la principale différence étant l'inclusion d'un terme répulsif pour éloigner les points éloignés les uns des autres.
Méthodes basées sur les matrices de proximité
Une méthode basée sur les matrices de proximité présente les données à l'algorithme sous forme de matrice de similarité ou de matrice de distance . Ces méthodes relèvent toutes de la catégorie plus large des mises à l'échelle multidimensionnelles métriques . Les variations résident généralement dans le calcul des données de proximité ; par exemple, isomap , les plongements linéaires locaux , le déploiement de variance maximale et le mappage de Sammon (qui n'est pas à proprement parler un mappage) sont des exemples de méthodes de mise à l'échelle multidimensionnelle métrique.
Logiciel
- Waffles est une bibliothèque C++ open source contenant des implémentations de LLE, de Manifold Sculpting et d'autres algorithmes d'apprentissage de variétés.
- UMAP.jl implémente la méthode pour le langage de programmation Julia . Cette méthode a également été implémentée en Python (code disponible sur GitHub ).