Un histogramme est une représentation visuelle de la distribution de données quantitatives. Pour construire un histogramme, la première étape consiste à « classer » (ou « regrouper ») l’ensemble des valeurs, c’est-à-dire à diviser l’ensemble des valeurs en une série d’intervalles, puis à compter le nombre de valeurs appartenant à chaque intervalle. Les classes sont généralement définies comme des intervalles consécutifs et non chevauchants d’une variable. Les classes (intervalles) sont adjacentes et sont généralement (mais pas nécessairement) de taille égale.
Les histogrammes donnent une idée approximative de la densité de la distribution sous-jacente des données et sont souvent utilisés pour l'estimation de densité : l'estimation de la fonction de densité de probabilité de la variable sous-jacente. L'aire totale d'un histogramme utilisé pour la densité de probabilité est toujours normalisée à 1. Si la longueur des intervalles sur l' axe des abscisses est égale à 1, alors un histogramme est identique à un graphique de fréquences relatives .
Les histogrammes sont parfois confondus avec les diagrammes à barres . Dans un histogramme, chaque classe correspond à une plage de valeurs différente, illustrant ainsi la distribution des valeurs. En revanche, dans un diagramme à barres, chaque barre représente une catégorie d'observations différente (par exemple, chaque barre peut représenter une population différente), permettant ainsi de comparer différentes catégories. Certains auteurs recommandent d'espacer les barres des diagrammes à barres afin de les distinguer des histogrammes.
Étymologie
Le terme « histogramme » a été introduit pour la première fois par Karl Pearson , fondateur des statistiques mathématiques , lors de cours donnés en 1892 à l'University College de Londres . On affirme parfois, à tort, que ce terme combine la racine grecque γραμμα ( gramma ; « figure » ou « dessin ») avec la racine ἱστορία (historia ; « enquête » ou « histoire »). On propose également la racine ἱστίον ( histion ), signifiant « réseau » ou « tissu » (comme dans histologie , l'étude des tissus biologiques). Ces deux étymologies sont erronées. En réalité, Pearson, qui maîtrisait parfaitement le grec ancien , a fait dériver le terme d'une autre racine grecque, homophone certes, ἱστός (« quelque chose dressé » ou « mât »), en référence aux barres verticales du graphique. Le nouveau terme de Pearson était intégré dans une série d'autres néologismes analogues , tels que stigmogramme et radiogramme .
Pearson lui-même notait en 1895 que, bien que le terme histogramme fût nouveau, le type de graphique qu'il désignait était « une forme courante de représentation graphique ». En fait, la technique consistant à utiliser un graphique à barres pour représenter des mesures statistiques a été conçue par l' économiste écossais William Playfair dans son Atlas commercial et politique (1786).
Exemples
Voici les données de l'histogramme de droite, utilisant 500 éléments :
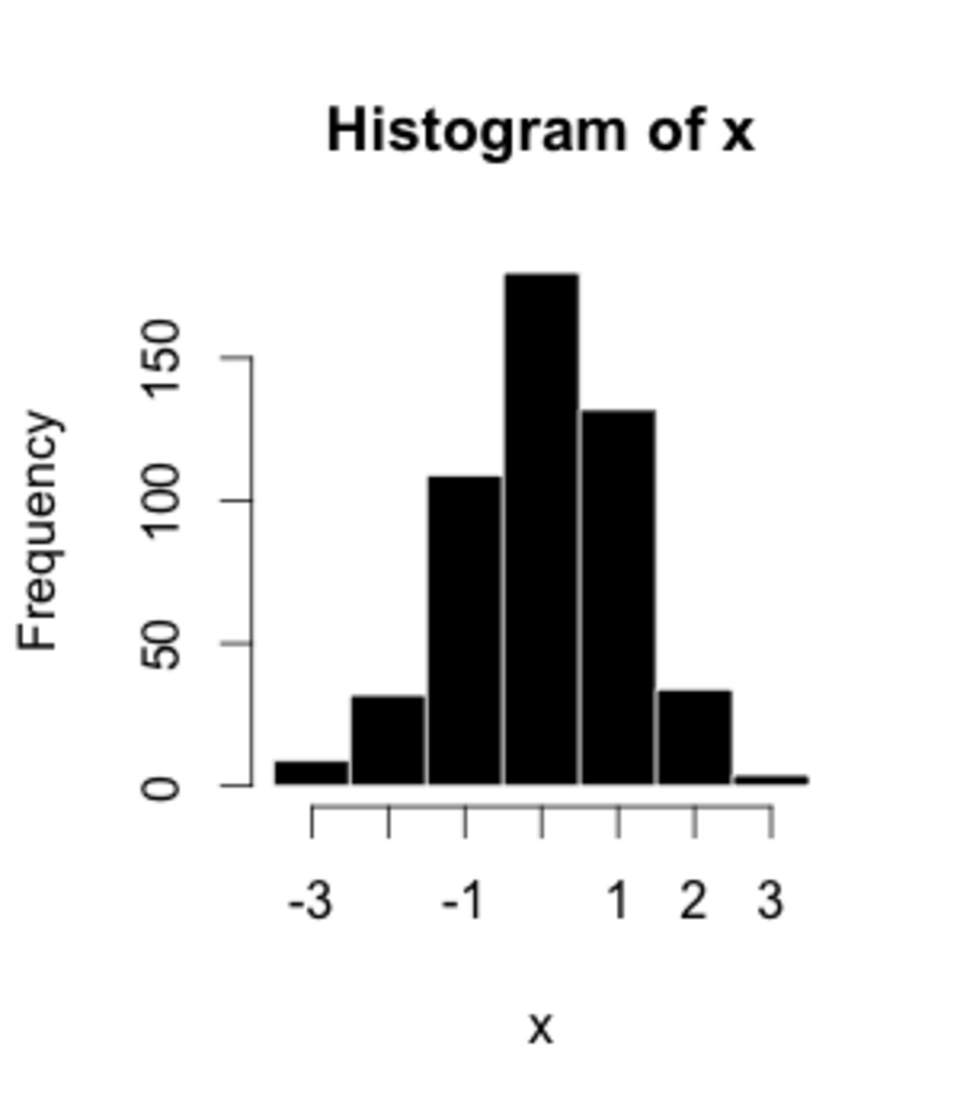
| Bin/Interval | Nombre/Fréquence |
|---|---|
| −3,5 à −2,51 | 9 |
| −2,5 à −1,51 | 32 |
| −1,5 à −0,51 | 109 |
| −0,5 à 0,49 | 180 |
| 0,5 à 1,49 | 132 |
| 1,5 à 2,49 | 34 |
| 2,5 à 3,49 | 4 |
Les termes utilisés pour décrire les tendances d'un histogramme sont : « symétrique », « asymétrique à gauche » ou « asymétrique à droite », « unimodal », « bimodal » ou « multimodal ».
 Symétrique, unimodal
Symétrique, unimodal
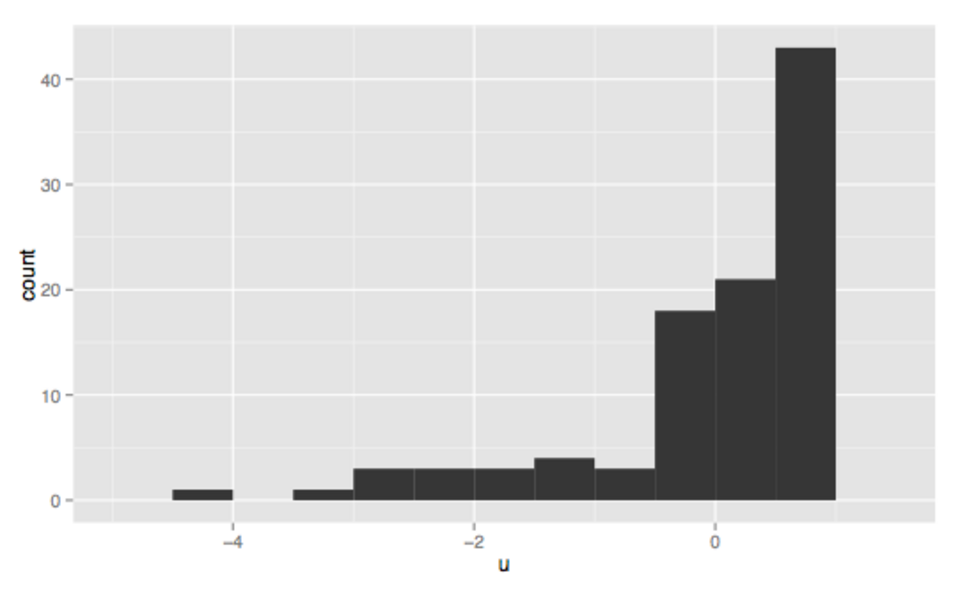
 Bimodal
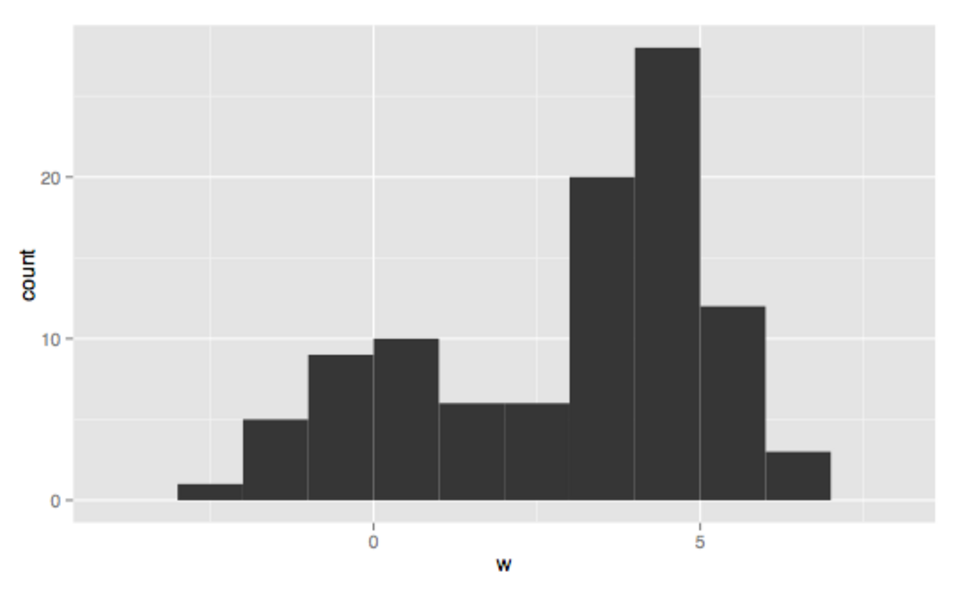
Bimodal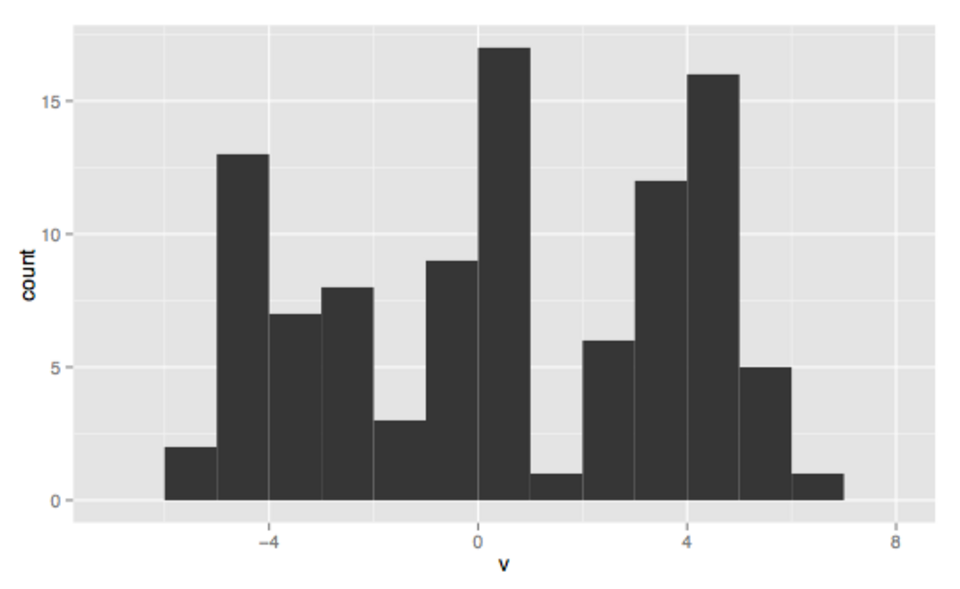 Multimodal
Multimodal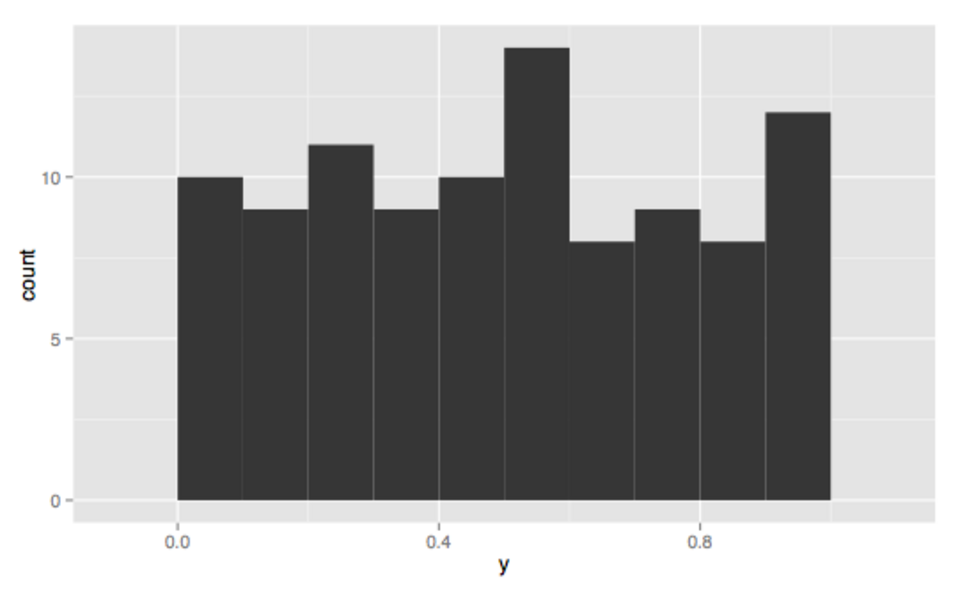 Symétrique
Symétrique
Il est judicieux de représenter graphiquement les données avec différentes largeurs de classes pour mieux les comprendre. Voici un exemple concernant les pourboires donnés dans un restaurant.
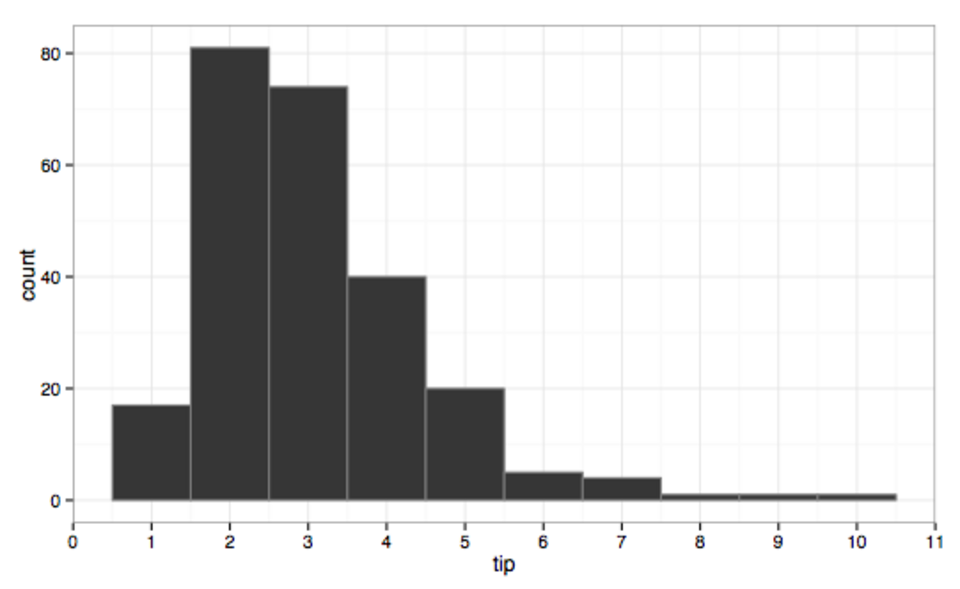 Conseils utilisant une largeur de classe de 1 $, asymétrique à droite, unimodale
Conseils utilisant une largeur de classe de 1 $, asymétrique à droite, unimodale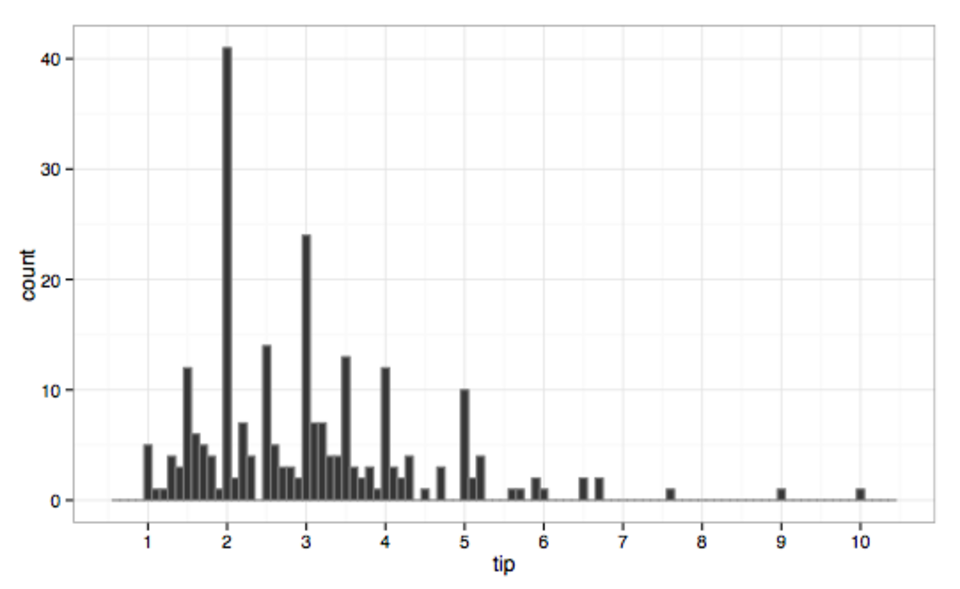 Les conseils utilisant une largeur de classe de 10 centimes, toujours asymétriques à droite, multimodaux avec des modes à 1 $ et 50 centimes, indiquent un arrondi, ainsi que quelques valeurs aberrantes.
Les conseils utilisant une largeur de classe de 10 centimes, toujours asymétriques à droite, multimodaux avec des modes à 1 $ et 50 centimes, indiquent un arrondi, ainsi que quelques valeurs aberrantes.
Le Bureau du recensement des États-Unis a dénombré 124 millions de personnes travaillant hors de leur domicile. À partir de leurs données sur le temps de trajet domicile-travail, le tableau ci-dessous montre que le nombre absolu de personnes ayant déclaré un temps de trajet « d’au moins 30 minutes mais de moins de 35 minutes » est supérieur aux chiffres des catégories supérieures et inférieures. Ceci est probablement dû à l’arrondi du temps de trajet déclaré. Le problème de la déclaration de valeurs arrondies , parfois arbitrairement, est un phénomène courant lors de la collecte de données auprès du grand public.

Données par nombres absolus Intervalle Largeur Quantité Quantité/largeur 0 5 4180 836 5 5 13687 2737 10 5 18618 3723 15 5 19634 3926 20 5 17981 3596 25 5 7190 1438 30 5 16369 3273 35 5 3212 642 40 5 4122 824 45 15 9200 613 60 30 6461 215 90 60 3435 57
Cet histogramme représente le nombre de cas par unité d'intervalle , la hauteur de chaque bloc correspondant à la surface de chaque bloc. L'aire sous la courbe représente le nombre total de cas (124 millions). Ce type d'histogramme affiche des valeurs absolues, Q étant exprimé en milliers.

Données par proportion Intervalle Largeur Quantité (Q) Q/total/largeur 0 5 4180 0,0067 5 5 13687 0,0221 10 5 18618 0,0300 15 5 19634 0,0316 20 5 17981 0,0290 25 5 7190 0,0116 30 5 16369 0,0264 35 5 3212 0,0052 40 5 4122 0,0066 45 15 9200 0,0049 60 30 6461 0,0017 90 60 3435 0,0005
Cet histogramme diffère du premier uniquement par son échelle verticale . L'aire de chaque bloc représente la fraction du total que représente chaque catégorie, et l'aire totale de toutes les barres est égale à 1 (la fraction signifiant « tout »). La courbe affichée est une simple estimation de densité . Cette version montre les proportions et est également connue sous le nom d'histogramme à aire unitaire.
Autrement dit, un histogramme représente une distribution de fréquences au moyen de rectangles dont la largeur représente les intervalles de classe et dont l'aire est proportionnelle aux fréquences correspondantes : la hauteur de chaque rectangle correspond à la densité de fréquence moyenne de l'intervalle. Les intervalles sont juxtaposés afin de montrer que les données représentées par l'histogramme, bien qu'exclusives, sont également contiguës. (Par exemple, dans un histogramme, il est possible d'avoir deux intervalles consécutifs de 10,5–20,5 et de 20,5–33,5, mais pas deux intervalles consécutifs de 10,5–20,5 et de 22,5–32,5. Les intervalles vides sont représentés comme tels et ne sont pas ignorés.)
Définitions mathématiques

Les données utilisées pour construire un histogramme sont générées par une fonction m <sub>i</sub> qui compte le nombre d'observations appartenant à chacune des catégories disjointes (appelées classes ). Ainsi, si l'on note n le nombre total d'observations et k le nombre total de classes, les données de l'histogramme m <sub>i</sub> satisfont aux conditions suivantes :
Un histogramme peut être vu comme une estimation simplifiée de la densité par noyau , utilisant un noyau pour lisser les fréquences dans les classes. On obtient ainsi une fonction de densité de probabilité plus lisse , reflétant généralement plus fidèlement la distribution de la variable sous-jacente. L'estimation de la densité peut être représentée graphiquement, alternativement à l'histogramme, et est généralement dessinée sous forme de courbe plutôt que de rectangles. Les histogrammes restent néanmoins privilégiés dans les applications nécessitant la modélisation de leurs propriétés statistiques. La variation corrélée d'une estimation de densité par noyau est très difficile à décrire mathématiquement, contrairement à un histogramme où chaque classe varie indépendamment.
Une alternative à l'estimation de densité par noyau est l'histogramme décalé moyen, qui est rapide à calculer et donne une estimation de courbe lisse de la densité sans utiliser de noyaux.
Histogramme cumulatif
Histogramme cumulatif : représentation graphique qui comptabilise le nombre cumulé d’observations dans toutes les classes jusqu’à la classe spécifiée. Autrement dit, l’histogramme cumulatif M<sub> i</sub> d’un histogramme m <sub> j</sub> peut être défini comme suit :
Nombre de bacs et largeur
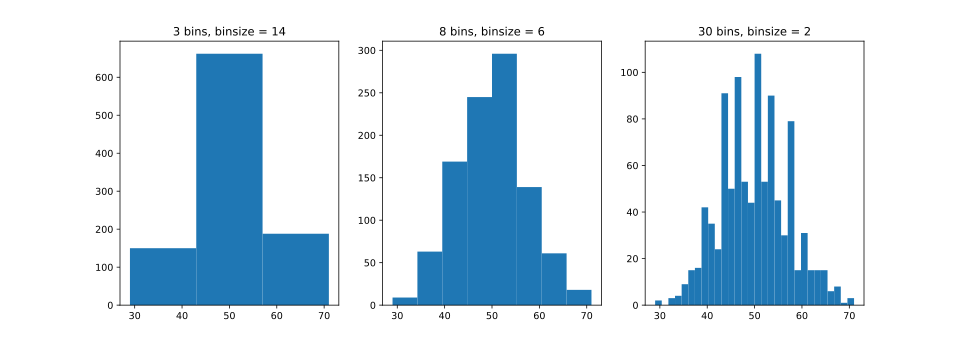
Il n'existe pas de nombre « idéal » de classes, et différentes tailles de classes peuvent révéler différentes caractéristiques des données. Le regroupement de données est au moins aussi ancien que les travaux de Graunt au XVIIe siècle, mais aucune directive systématique n'a été donnée avant les travaux de Sturges en 1926.
L'utilisation de classes plus larges là où la densité des données sous-jacentes est faible réduit le bruit dû à l'aléatoire de l'échantillonnage ; l'utilisation de classes plus étroites là où la densité est élevée (le signal masquant alors le bruit) améliore la précision de l'estimation de la densité. Il peut donc être avantageux de faire varier la largeur des classes dans un histogramme. Néanmoins, les classes de largeur égale restent les plus courantes.
Certains théoriciens ont tenté de déterminer un nombre optimal de classes, mais ces méthodes reposent généralement sur des hypothèses fortes concernant la forme de la distribution. Selon la distribution réelle des données et les objectifs de l'analyse, différentes largeurs de classes peuvent convenir ; il est donc généralement nécessaire de procéder à des essais pour déterminer une largeur appropriée. Il existe cependant diverses lignes directrices et règles empiriques utiles.
Le nombre de classes k peut être attribué directement ou calculé à partir d'une largeur de classe suggérée h comme suit :
Les accolades indiquent la fonction de plafond .
Choix de la racine carrée
qui prend la racine carrée du nombre de points de données dans l'échantillon et arrondit à l' entier supérieur . Cette règle est suggérée par plusieurs manuels de statistiques élémentaires et largement implémentée dans de nombreux logiciels.
La formule de Sturges
La règle de Sturges est dérivée d'une distribution binomiale et suppose implicitement une distribution approximativement normale.
La formule de Sturges base implicitement la taille des classes sur l'étendue des données et peut donner de mauvais résultats si n < 30 , car le nombre de classes sera faible (moins de sept) et il est peu probable qu'elle permette de bien mettre en évidence les tendances dans les données. À l'inverse, cette formule peut surestimer la largeur des classes pour les très grands ensembles de données, ce qui entraîne des histogrammes trop lissés. Elle peut également donner de mauvais résultats si les données ne suivent pas une distribution normale.
Comparée à la règle de Scott et à la règle de Terrell-Scott, deux autres formules largement acceptées pour les classes d'histogramme, la sortie de la formule de Sturges est la plus proche lorsque n ≈ 100 .
Règle du riz
La règle de Rice est présentée comme une alternative simple à la règle de Sturges.
La formule de Doane
La formule de Doane est une modification de la formule de Sturges qui tente d'améliorer ses performances avec des données non normales.
où représente l' asymétrie du troisième moment estimée de la distribution et
La règle de référence normale de Scott
La largeur des bins est donnée par
où σ représente l' écart type de l'échantillon . La règle de référence normale de Scott est optimale pour les échantillons aléatoires de données normalement distribuées, en ce sens qu'elle minimise l'erreur quadratique moyenne intégrée de l'estimation de la densité. Il s'agit de la règle par défaut utilisée dans Microsoft Excel.
Règle Terrell-Scott
La règle de Terrell-Scott n'est pas une règle de référence classique. Elle donne le nombre minimal de classes requis pour un histogramme asymptotiquement optimal, l'optimalité étant mesurée par l'erreur quadratique moyenne intégrée. La borne est obtenue en déterminant la densité la plus « lisse » possible, qui s'avère être . Toute autre densité nécessitera davantage de classes ; c'est pourquoi cette estimation est également appelée règle « sur-lissée ». La similarité des formules et le fait que Terrell et Scott travaillaient à l'Université Rice lors de sa proposition suggèrent que cette dernière est également à l'origine de la règle de Rice.
Règle Freedman-Diaconis
La règle de Freedman–Diaconis donne la largeur des intervalles comme suit :
Cette méthode est basée sur l' écart interquartile , noté IQR. Elle remplace 3,5σ (règle de Scott) par 2 IQR, moins sensible aux valeurs aberrantes que l'écart type.
Minimisation de l'erreur quadratique estimée par validation croisée
Cette approche de minimisation de l'erreur quadratique moyenne intégrée de la règle de Scott peut être généralisée au-delà des distributions normales, en utilisant la validation croisée leave-one-out :
Ici, représente le nombre de points de données dans la k -ième classe, et choisir la valeur de h qui minimise J minimisera l'erreur quadratique moyenne intégrée.
Le choix de Shimazaki et Shinomoto
Le choix est basé sur la minimisation d'une fonction de risque L 2 estimée
où et sont la moyenne et la variance biaisée d'un histogramme avec une largeur de classe , et .
largeurs de bacs variables
Plutôt que de choisir des classes équidistantes, il est parfois préférable de faire varier leur largeur. Cela permet d'éviter les classes contenant peu d'éléments. On choisit souvent des classes équiprobables , c'est-à-dire que le nombre d'échantillons dans chaque classe est approximativement égal. Les classes peuvent être choisies selon une distribution connue ou en fonction des données, de sorte que chaque classe contienne suffisamment d'échantillons. Lors de la construction de l'histogramme, la densité de fréquence est utilisée pour l'axe des ordonnées. Bien que toutes les classes aient une aire approximativement égale, les hauteurs de l'histogramme correspondent approximativement à la distribution de densité.
Pour les classes équiprobables, la règle suivante concernant le nombre de classes est suggérée :
Ce choix de classes est motivé par la maximisation de la puissance d'un test du chi carré de Pearson visant à vérifier si les classes contiennent un nombre égal d'échantillons. Plus précisément, pour un intervalle de confiance donné, il est recommandé de choisir entre 1/2 et 1 fois l'équation suivante :
Où se trouve la fonction probit ? En suivant cette règle pour , on obtiendrait entre et ; le coefficient 2 est choisi comme valeur facile à retenir parmi cet optimum général.
Remarque
Une bonne raison pour laquelle le nombre de classes doit être proportionnel à est la suivante : supposons que les données soient obtenues comme des réalisations indépendantes d'une distribution de probabilité bornée à densité régulière. L'histogramme reste alors tout aussi « turbulent » lorsque tend vers l'infini. Si est la « largeur » de la distribution (par exemple, l'écart type ou l'écart interquartile), alors le nombre d'unités dans une classe (la fréquence) est de l'ordre de et l' erreur standard relative est de l'ordre de . Par rapport à la classe suivante, la variation relative de la fréquence est de l'ordre de à condition que la dérivée de la densité soit non nulle. Ces deux grandeurs sont du même ordre si est de l'ordre de , donc est de l'ordre de . Ce choix simple de racine cubique peut également être appliqué aux classes de largeur non constante.
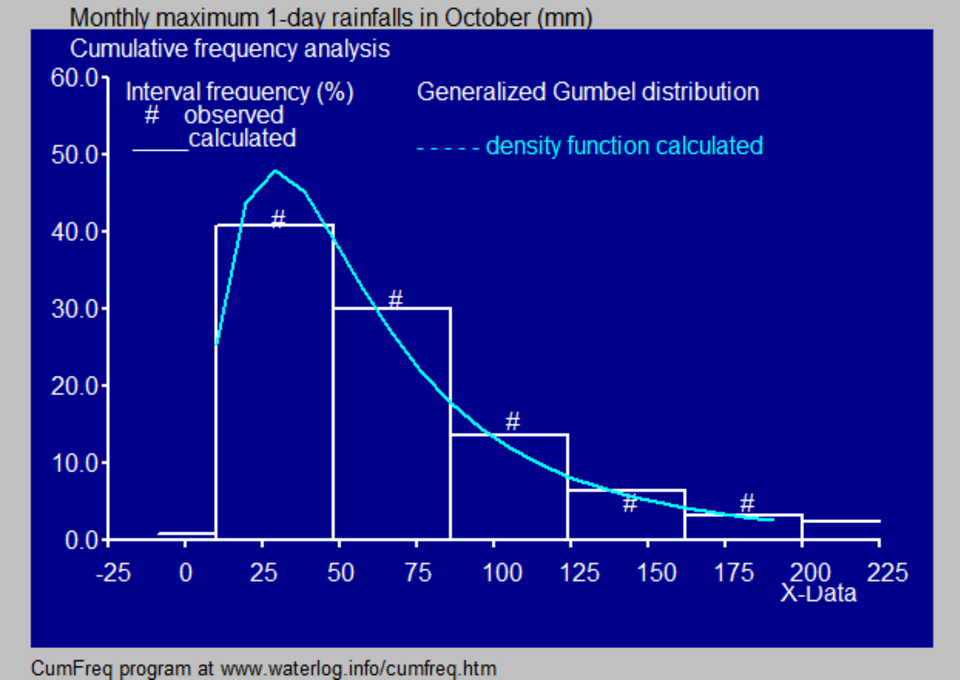
Applications
- En hydrologie, l'histogramme et la fonction de densité estimée des données de précipitations et de débit fluvial, analysés à l'aide d'une distribution de probabilité , sont utilisés pour mieux comprendre leur comportement et leur fréquence d'occurrence. Un exemple est présenté dans la figure bleue.
- De nombreux logiciels de traitement d'images numériques disposent d'un outil histogramme qui affiche la distribution du contraste /de la luminosité des pixels .
Histogramme du contraste