Le World Wide Web (également connu sous le nom de WWW , W3 ou simplement le Web ) est un système d'information mondial interconnecté qui permet le partage de contenu sur Internet . Il facilite l'accès aux documents et autres ressources Web selon les règles spécifiques du protocole de transfert hypertexte (HTTP).
Le Web a été inventé par l'informaticien britannique Tim Berners-Lee au CERN en 1989 et ouvert au public en 1993. Il a été conçu comme un « système d'information interconnecté universel ». Les documents et autres contenus multimédias sont mis à disposition sur le réseau via des serveurs Web et sont accessibles par des programmes tels que les navigateurs Web . Les serveurs et les ressources du World Wide Web sont identifiés et localisés grâce à une chaîne de caractères appelée URL ( Uniform Resource Locator ).
Le type de document original, et encore très répandu, est une page web formatée en HTML ( Hypertext Markup Language ). Ce langage de balisage prend en charge le texte brut , les images , les contenus audio et vidéo intégrés , ainsi que les scripts (courts programmes ) permettant des interactions utilisateur complexes. Le langage HTML prend également en charge les hyperliens (URL intégrées), qui offrent un accès direct à d'autres ressources web. La navigation web , ou surf sur le web, consiste à suivre ces hyperliens sur différents sites web. Les applications web sont des pages web qui fonctionnent comme des logiciels d'application . Les informations sur le web sont transférées sur Internet via le protocole HTTP. Un site web est constitué de plusieurs ressources web partageant un thème commun et généralement un nom de domaine commun . Un seul serveur web peut héberger plusieurs sites web, tandis que certains sites, notamment les plus populaires, peuvent être hébergés par plusieurs serveurs. Le contenu des sites web est fourni par une multitude d'entreprises, d'organisations, d'organismes gouvernementaux et d'utilisateurs individuels ; il comprend une quantité considérable d'informations éducatives, de divertissement, commerciales et gouvernementales.
Le World Wide Web est devenu la plateforme de systèmes d'information dominante au niveau mondial . C'est le principal outil que des milliards de personnes dans le monde utilisent pour interagir avec Internet.
Histoire

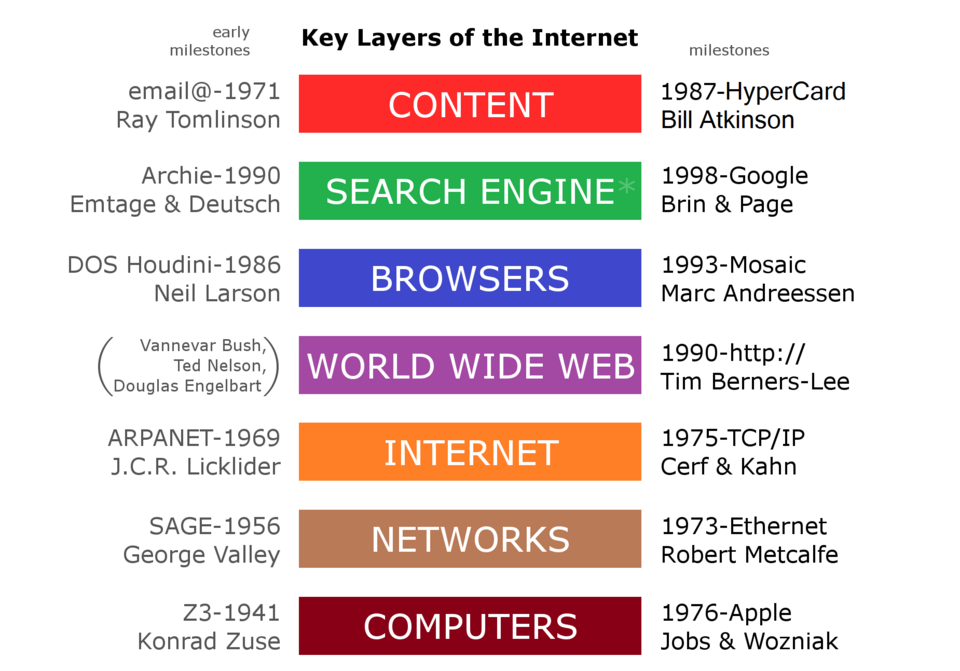
Le Web a été inventé par l'informaticien anglais Tim Berners-Lee alors qu'il travaillait au CERN . Il était motivé par le problème du stockage, de la mise à jour et de la recherche de documents et de fichiers de données au sein de cette organisation vaste et en constante évolution, ainsi que par leur diffusion auprès de collaborateurs extérieurs au CERN. Dans sa conception, Berners-Lee a rejeté l'approche classique de la structure arborescente , utilisée par exemple dans le système de documentation CERNDOC et dans le système de fichiers Unix , ainsi que les approches reposant sur l'étiquetage des fichiers par des mots-clés , comme dans le système VAX/NOTES. Il a plutôt adopté des concepts qu'il avait mis en pratique avec son système privé ENQUIRE (1980), développé au CERN. La découverte du modèle hypertexte de Ted Nelson (1965), dans lequel les documents peuvent être liés de manière libre par des hyperliens associés à des « points d'intérêt » intégrés au texte, a contribué à confirmer la validité de son concept.

Ce modèle fut ensuite popularisé par le système HyperCard d' Apple . Contrairement à HyperCard, le nouveau système de Berners-Lee visait dès le départ à prendre en charge les liens entre plusieurs bases de données sur des ordinateurs indépendants et à permettre un accès simultané par de nombreux utilisateurs depuis n'importe quel ordinateur connecté à Internet. Il précisa également que le système devrait à terme gérer d'autres types de médias que le texte, tels que les graphiques, la parole et la vidéo. Les liens pourraient pointer vers des fichiers de données modifiables, voire lancer des programmes sur leur serveur. Il conçut également des « passerelles » permettant d'accéder, via le nouveau système, à des documents organisés autrement (par exemple, via les systèmes de fichiers informatiques traditionnels ou Usenet ). De plus, il insista sur la décentralisation du système, sans contrôle ni coordination centralisée de la création des liens.
En mars 1989, Berners-Lee soumit une proposition au CERN sans nommer le système. Il parvint à mettre en place un système fonctionnel fin 1990, comprenant un navigateur appelé WorldWideWeb (qui devint le nom du projet et du réseau) et un serveur HTTP hébergé au CERN. Dans le cadre de ce développement, il définit la première version du protocole HTTP, la syntaxe de base des URL et imposa implicitement le format HTML comme format de document principal. La technologie fut diffusée hors du CERN à d'autres institutions de recherche à partir de janvier 1991, puis sur l'ensemble d'Internet le 23 août 1991. Le Web connut un vif succès au CERN et commença à se répandre dans d'autres institutions scientifiques et universitaires. Au cours des deux années suivantes, 50 sites web furent créés .
Le CERN a mis à disposition le protocole et le code du Web gratuitement le 30 avril 1993, permettant ainsi sa large diffusion. Après la publication du navigateur web Mosaic par le NCSA plus tard dans l'année, la popularité du Web a explosé, avec l'apparition de milliers de sites web en moins d'un an. Mosaic était un navigateur graphique capable d'afficher des images intégrées et de soumettre des formulaires traités par le serveur HTTPd . Marc Andreessen et Jim Clark ont fondé Netscape l'année suivante et ont lancé le navigateur Navigator , qui a introduit Java et JavaScript sur le Web. Il est rapidement devenu le navigateur dominant. Netscape est entré en bourse en 1995, déclenchant un véritable engouement pour le Web et amorçant la bulle Internet . Microsoft a réagi en développant son propre navigateur, Internet Explorer , lançant ainsi la guerre des navigateurs . En l'intégrant à Windows, il est devenu le navigateur dominant pendant 14 ans.
Berners-Lee a fondé le World Wide Web Consortium (W3C), qui a créé XML en 1996 et a recommandé de remplacer HTML par XHTML, plus strict . Entre-temps, les développeurs ont commencé à exploiter une fonctionnalité d'Internet Explorer appelée XMLHttpRequest pour créer des applications Ajax et ont lancé la révolution du Web 2.0 . Mozilla , Opera et Apple ont rejeté XHTML et créé le WHATWG , qui a développé HTML5 . En 2009, le W3C a cédé et abandonné XHTML. En 2019, il a cédé le contrôle de la spécification HTML au WHATWG.
Le World Wide Web a joué un rôle central dans le développement de l' ère de l'information et constitue le principal outil utilisé par des milliards de personnes pour interagir sur Internet .
Concurrence avec Gopher
Gopher était géré par l' Université du Minnesota et constituait une alternative au World Wide Web.
- En février 1993, l' Université du Minnesota annonça qu'elle exigerait des droits de licence pour l'utilisation de son implémentation du serveur Gopher. Les utilisateurs s'inquiétèrent de la possibilité que des frais soient également exigés pour les implémentations indépendantes. Le développement de Gopher stagna, au profit du World Wide Web, qui passa dans le domaine public en avril 1993 , sous la gestion du CERN . En septembre 2000, l'Université du Minnesota redistribua son logiciel Gopher sous la licence publique générale GNU .
- Les fonctionnalités du client Gopher ont rapidement été reproduites par le navigateur web Mosaic , qui a intégré son protocole.
- Gopher possède une structure plus rigide que le langage HTML (HyperText Markup Language) du Web, qui est plus libre . Chaque document Gopher a un format et un type définis, et l'utilisateur navigue généralement via un système de menus unique, défini par le serveur, pour accéder à un document particulier. Cette méthode peut être très différente de la manière dont un utilisateur recherche des documents sur le Web.
- Non-respect du modèle des systèmes ouverts et mauvaise publicité par rapport au World Wide Web.
Nomenclature
Tim Berners-Lee affirme que World Wide Web s'écrit officiellement en trois mots distincts, chacun avec une majuscule, sans trait d'union. L'utilisation du préfixe « www » est en déclin, notamment depuis que les applications web ont cherché à personnaliser leurs noms de domaine et à les rendre plus faciles à prononcer. Avec la popularité croissante du web mobile , des services comme Gmail.com , Outlook.com , Myspace.com , Facebook.com et Twitter.com sont le plus souvent mentionnés sans ajouter « www. » (ni « .com ») au domaine.
En anglais, www se prononce généralement « double-u double-u double-u » . Certains utilisateurs le prononcent « dub-dub-dub » , notamment en Nouvelle-Zélande . Stephen Fry , dans sa série de podcasts « Podgrams », le prononce « wuh wuh wuh » . L’écrivain anglais Douglas Adams a un jour écrit avec humour dans The Independent on Sunday (1999) : « Le World Wide Web est la seule chose que je connaisse dont la forme abrégée est trois fois plus longue à prononcer que le nom qu’elle signifie. »
Fonction
Les termes « Internet » et « World Wide Web » sont souvent utilisés indifféremment. Pourtant, ils ne sont pas synonymes. Internet est un système mondial de réseaux informatiques interconnectés par télécommunications et réseaux optiques . Le World Wide Web, quant à lui, est un ensemble mondial de documents et autres ressources , reliés par des hyperliens et des URI . L’accès aux ressources Web se fait via HTTP ou HTTPS , des protocoles Internet de niveau application qui utilisent les protocoles de transport Internet.
La consultation d'une page web sur le World Wide Web commence généralement soit par la saisie de son URL dans un navigateur, soit par le clic sur un lien hypertexte. Le navigateur lance alors une série de messages en arrière-plan pour récupérer et afficher la page demandée. Dans les années 1990, l'utilisation d'un navigateur pour consulter des pages web – et passer d'une page à l'autre par le biais de liens hypertextes – a commencé à être appelée « navigation sur le Web ». Les premières études sur ce nouveau comportement ont analysé les habitudes des utilisateurs. Une étude, par exemple, a identifié cinq profils d'utilisateurs : la navigation exploratoire, la navigation par fenêtres, la navigation évoluée, la navigation délimitée et la navigation ciblée.
L'exemple suivant illustre le fonctionnement d'un navigateur web lors de l'accès à une page à l'URLhttp://example.org/home.htmlLe navigateur résout le nom du serveur de l'URL (exemple.orgLe navigateur récupère une adresse IP (par exemple , 203.0.113.4 ou 2001:db8:2e::7334 ) via le système de noms de domaine (DNS), un système de résolution de noms de domaine distribué à l'échelle mondiale. Il demande ensuite la ressource en envoyant une requête HTTP sur Internet à l'ordinateur correspondant à cette adresse. Cette requête utilise un port TCP spécifique, connu pour le protocole HTTP, afin que le serveur puisse la distinguer des autres protocoles réseau qu'il traite. Le protocole HTTP utilise généralement le port 80 et le protocole HTTPS, le port 443. Le contenu de la requête HTTP peut se limiter à deux lignes de texte :
GET /home.html HTTP / 1.1 Hôte : example.org
L'ordinateur qui reçoit la requête HTTP la transmet au serveur web qui écoute les requêtes sur le port 80. Si le serveur web peut traiter la requête, il renvoie une réponse HTTP au navigateur pour indiquer que l'opération a réussi.
HTTP / 1.1 200 OK Content-Type : text/html; charset=UTF-8
Suivi du contenu de la page demandée. Le code HTML (Hypertext Markup Language ) d'une page web basique pourrait ressembler à ceci :
< html > < head > < title > Example.org – Le World Wide Web </ title > </ head > < body > < p > Le World Wide Web, abrégé en WWW et communément appelé ... </ p > </ body > </ html >
Le navigateur web analyse le code HTML et interprète le balisage (balises <p> , <paragraphe, etc.) qui entoure le texte afin de le mettre en forme à l'écran. De nombreuses pages web utilisent le HTML pour référencer les URL d'autres ressources telles que des images, d'autres médias intégrés, des scripts qui modifient le comportement de la page et des feuilles de style en cascade (CSS) qui affectent sa mise en page. Le navigateur effectue des requêtes HTTP supplémentaires auprès du serveur web pour obtenir ces autres types de médias . Au fur et à mesure qu'il reçoit le contenu du serveur web, le navigateur affiche progressivement la page à l'écran conformément au code HTML et à ces ressources supplémentaires. <title><p>
HTML
Le langage HTML (Hypertext Markup Language) est le langage de balisage standard pour la création de pages web et d'applications web . Avec les feuilles de style en cascade (CSS) et JavaScript , il forme une triade de technologies fondamentales pour le World Wide Web.
Les navigateurs web reçoivent des documents HTML depuis un serveur web ou depuis le stockage local et les transforment en pages web multimédias. Le HTML décrit la structure sémantique d'une page web et incluait à l'origine des indications pour la mise en forme du document.
Les éléments HTML sont les composants de base des pages HTML. Grâce à ces structures, des images et d'autres objets, comme des formulaires interactifs, peuvent être intégrés à la page rendue. HTML permet de créer des documents structurés en définissant la structure sémantique du texte : titres, paragraphes, listes, liens , citations, etc. Les éléments HTML sont délimités par des balises <img> , écrites entre chevrons . Les balises <p> et <div> introduisent directement du contenu dans la page. D'autres balises, comme <b> , entourent <img> et <div>, fournissent des informations sur le texte du document et peuvent contenir d'autres balises <b> comme sous-éléments. Les navigateurs n'affichent pas les balises HTML, mais les utilisent pour interpréter le contenu de la page. <img/><input/><p>
HTML peut intégrer des programmes écrits dans un langage de script tel que JavaScript , ce qui influence le comportement et le contenu des pages web. L'inclusion de CSS définit l'apparence et la mise en page du contenu. Le World Wide Web Consortium (W3C), qui maintient la norme CSS, encourage l'utilisation de CSS plutôt que du HTML de présentation explicite depuis 1997.
Enchaînement
La plupart des pages web contiennent des hyperliens vers d'autres pages connexes et parfois vers des fichiers téléchargeables, des documents sources, des définitions et d'autres ressources web. En HTML, un hyperlien est codé ainsi : <ahref="http://example.org/home.html">Example.org Homepage</a>.
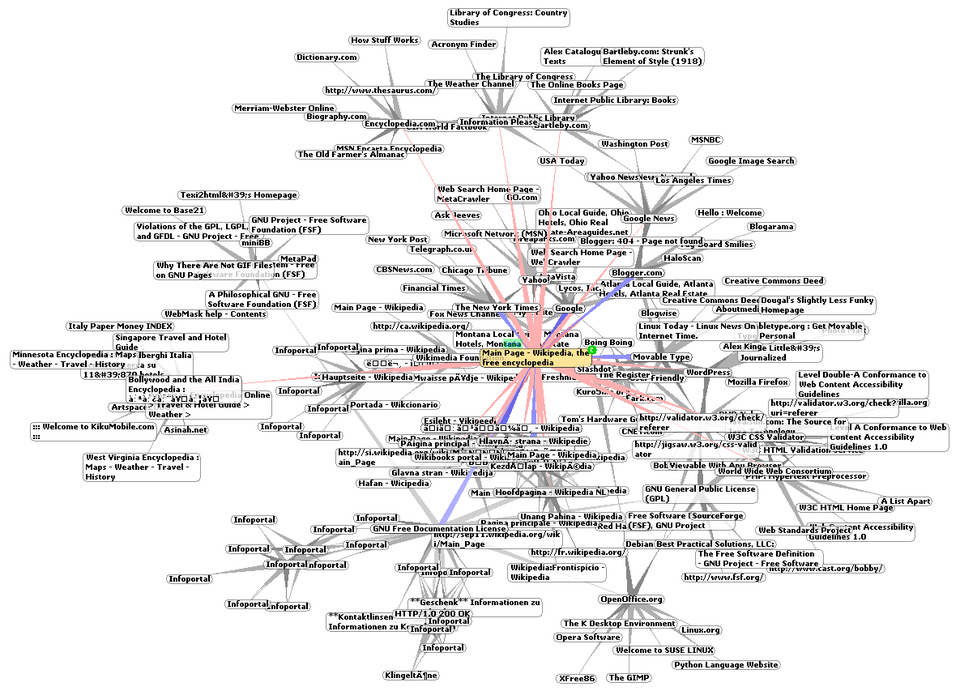
Un tel ensemble de ressources utiles et connexes, interconnectées par des liens hypertextes, est appelé « web d’information ». La publication sur Internet a créé ce que Tim Berners-Lee a d’abord appelé le WorldWideWeb (dans sa notation CamelCase originale , qui a ensuite été abandonnée) le 12 novembre 1990.
La structure des liens hypertextes du Web est décrite par le graphe du Web : les nœuds de ce graphe correspondent aux pages Web (ou URL), et les arêtes orientées entre elles aux liens hypertextes. Au fil du temps, de nombreuses ressources Web accessibles par des liens hypertextes disparaissent, changent d’adresse ou sont remplacées par un contenu différent. Les liens hypertextes deviennent alors obsolètes, un phénomène parfois appelé « pourriture des liens », et les liens concernés sont souvent qualifiés de « liens morts » . La nature éphémère du Web a suscité de nombreuses initiatives d’archivage de sites Web. L’ Internet Archive , active depuis 1996, est la plus connue d’entre elles.
préfixe www
De nombreux noms d'hôtes utilisés pour le World Wide Web commencent par « www » en raison de la pratique courante consistant à nommer les hôtes Internet en fonction des services qu'ils fournissent. Le nom d'hôte d'un serveur web est souvent « www » , de la même manière qu'il peut être « ftp » pour un serveur FTP , et « news » ou « nntp » pour un serveur de news Usenet . Ces noms d'hôtes apparaissent comme noms de domaine (DNS) ou sous-domaines , comme dans www.example.com . L'utilisation de « www » n'est imposée par aucune norme technique ou politique, et de nombreux sites web ne l'utilisent pas ; le premier serveur web était nxoc01.cern.ch . Selon Paolo Palazzi, qui travaillait au CERN avec Tim Berners-Lee, l'utilisation courante de « www » comme sous-domaine était accidentelle ; la page du projet World Wide Web était censée être publiée à l'adresse www.cern.ch, tandis que info.cern.ch était destiné à être la page d'accueil du CERN. Cependant, les enregistrements DNS n'ont jamais été modifiés, et la pratique consistant à ajouter www au nom de domaine du site Web d'une institution a été copiée par la suite.
De nombreux sites web établis utilisent encore le préfixe www, ou emploient d'autres sous-domaines tels que www2 , secure ou en pour des besoins spécifiques. Beaucoup de ces serveurs web sont configurés de sorte que le nom de domaine principal (par exemple, example.com) et le sous-domaine www (par exemple, www.example.com) pointent vers le même site ; d'autres exigent l'une ou l'autre forme, ou peuvent les faire correspondre à des sites web différents. L'utilisation d'un sous-domaine est utile pour répartir la charge du trafic web entrant en créant un enregistrement CNAME pointant vers un cluster de serveurs web. Étant donné qu'actuellement seul un sous-domaine peut être utilisé dans un enregistrement CNAME, le même résultat ne peut être obtenu en utilisant simplement le nom de domaine racine.
Lorsqu'un utilisateur saisit un nom de domaine incomplet dans la barre d'adresse de son navigateur web, certains navigateurs tentent automatiquement d'ajouter le préfixe « www » au début et éventuellement les extensions « .com », « .org » et « .net » à la fin, selon les éléments manquants. Par exemple, « microsoft » peut être transformé en http://www.microsoft.com/ et « openoffice » en http://www.openoffice.org . Cette fonctionnalité est apparue dans les premières versions de Firefox , alors appelé « Firebird » début 2003, reprenant une pratique antérieure de navigateurs tels que Lynx . Il semblerait que Microsoft ait obtenu un brevet américain pour cette même idée en 2008, mais uniquement pour les appareils mobiles.
Spécificateurs de schéma
Les spécificateurs de schéma `http://` http://et https://`httpS` au début d'une URI Web font respectivement référence au protocole de transfert hypertexte (HTTP) et au protocole HTTP sécurisé (HTTP Secure) . Ils spécifient le protocole de communication à utiliser pour la requête et la réponse. Le protocole HTTP est fondamental au fonctionnement du Web, et la couche de chiffrement supplémentaire apportée par HTTPS est essentielle lorsque les navigateurs envoient ou reçoivent des données confidentielles, telles que des mots de passe ou des informations bancaires. Les navigateurs Web ajoutent généralement automatiquement `http://` au début des URI saisies par l'utilisateur, si ce préfixe est omis.
Pages
Une page web est un document conçu pour le World Wide Web et les navigateurs web . Un navigateur web affiche une page web sur un écran ou un appareil mobile .
Le terme « page web » désigne généralement ce qui est visible, mais peut aussi faire référence au contenu du fichier informatique lui-même, généralement un fichier texte contenant des hyperliens écrits en HTML ou dans un langage de balisage similaire . Les pages web classiques proposent des hyperliens permettant de naviguer vers d'autres pages web . Lors de l'affichage de chaque page web, les navigateurs doivent fréquemment accéder à de nombreux éléments de ressources web , tels que les feuilles de style , les scripts et les images.
Sur un réseau, un navigateur web peut récupérer une page web depuis un serveur web distant . Ce serveur peut restreindre l'accès à un réseau privé, tel qu'un intranet d'entreprise. Le navigateur utilise le protocole de transfert hypertexte (HTTP) pour effectuer ces requêtes auprès du serveur web.
Une page web statique est affichée telle quelle, c'est -à -dire telle qu'elle est stockée sur le serveur web . À l'inverse, une page web dynamique est générée par une application web , généralement pilotée par un logiciel côté serveur . Les pages web dynamiques sont utilisées lorsque chaque utilisateur peut avoir besoin d'informations différentes, par exemple pour les sites web bancaires, les messageries électroniques, etc.
Page statique
Une page web statique (parfois appelée page plate/page fixe ) est une page web qui est livrée à l'utilisateur exactement telle qu'elle est stockée, contrairement aux pages web dynamiques qui sont générées par une application web .
Par conséquent, une page web statique affiche les mêmes informations à tous les utilisateurs, quel que soit le contexte, sous réserve des capacités modernes d'un serveur web à négocier le type de contenu ou la langue du document lorsque de telles versions sont disponibles et que le serveur est configuré pour ce faire.
Pages dynamiques

Une page web dynamique côté serveur est une page web dont la construction est contrôlée par un serveur d'applications exécutant des scripts côté serveur. Dans ce type de script, des paramètres déterminent le déroulement de l'assemblage de chaque nouvelle page web, y compris la mise en place de traitements supplémentaires côté client.
Une page web dynamique côté client traite la page web à l'aide de JavaScript exécuté dans le navigateur. Les programmes JavaScript peuvent interagir avec le document via le DOM ( Document Object Model ) pour interroger l'état de la page et le modifier. Les mêmes techniques côté client permettent ensuite de mettre à jour ou de modifier dynamiquement le DOM de la même manière.
Une page web dynamique est ensuite rechargée par l'utilisateur ou par un programme informatique pour modifier son contenu variable. Les informations mises à jour peuvent provenir du serveur ou de modifications apportées au DOM de la page. Cette opération peut tronquer l'historique de navigation ou créer une version enregistrée pour y revenir, mais une mise à jour de page web dynamique utilisant les technologies Ajax ne crée ni une page de retour en arrière ni ne tronque l' historique de navigation au-delà de la page affichée. Grâce aux technologies Ajax, l' utilisateur final obtient une page dynamique gérée comme une page unique dans son navigateur, même si le contenu web affiché sur cette page peut varier. Le moteur Ajax s'exécute uniquement côté navigateur et demande des parties de son DOM ( le DOM du client) à un serveur d'applications.
Le terme DHTML (HTML dynamique) désigne l'ensemble des technologies et méthodes permettant de créer des pages web dynamiques . Cependant, son usage a diminué depuis la popularisation d' AJAX , un terme lui-même aujourd'hui peu utilisé. L'expérience web dynamique dans un navigateur repose sur l'exécution de scripts côté client, de scripts côté serveur, ou d'une combinaison des deux.
JavaScript est un langage de script initialement développé en 1995 par Brendan Eich , alors chez Netscape , pour une utilisation au sein des pages web. Sa version standardisée est ECMAScript . Pour rendre les pages web plus interactives, certaines applications web utilisent également des techniques JavaScript telles qu'Ajax ( JavaScript asynchrone et XML ). Un script côté client est intégré à la page et peut effectuer des requêtes HTTP supplémentaires vers le serveur, soit en réponse à des actions de l'utilisateur (mouvements de souris, clics, etc.), soit en fonction du temps écoulé. Les réponses du serveur permettent de modifier la page courante sans avoir à en créer une nouvelle à chaque réponse ; le serveur n'a donc besoin de fournir que des informations limitées et incrémentales. Plusieurs requêtes Ajax peuvent être traitées simultanément, et les utilisateurs peuvent interagir avec la page pendant la récupération des données. Les pages web peuvent également interroger régulièrement le serveur pour vérifier la disponibilité de nouvelles informations.
Site web

Un site web est un ensemble de ressources web liées entre elles, comprenant des pages web et du contenu multimédia , généralement identifiées par un nom de domaine commun et publiées sur au moins un serveur web . Des exemples notables sont wikipedia.org , google.com et amazon.com .
Un site web peut être accessible via un réseau public de protocole Internet (IP), tel qu'Internet , ou un réseau local privé (LAN), en référençant un localisateur de ressources uniformes (URL) qui identifie le site.
Les sites web peuvent avoir de nombreuses fonctions et être utilisés de diverses manières ; il peut s’agir d’un site personnel , d’un site d’entreprise, d’un site gouvernemental, d’un site d’organisation, etc. Les sites web sont généralement dédiés à un sujet ou à un objectif particulier, allant du divertissement et des réseaux sociaux à l’information et à l’éducation. L’ensemble des sites web accessibles au public constitue le World Wide Web, tandis que les sites web privés, tels que le site web d’une entreprise destiné à ses employés, font généralement partie d’un intranet .
Les pages web, éléments constitutifs des sites web, sont des documents généralement composés de texte brut , agrémenté d' instructions de mise en forme en HTML (Hypertext Markup Language ) ou XHTML ( Hypertext Markup Language ). Elles peuvent intégrer des éléments provenant d'autres sites web grâce à des ancres de balisage appropriées . L'accès aux pages web et leur transmission s'effectuent via le protocole HTTP ( Hypertext Transfer Protocol ), qui peut, en option, utiliser le chiffrement ( HTTP Secure ou HTTPS) afin de garantir la sécurité et la confidentialité des données de l'utilisateur. L'application de l'utilisateur, souvent un navigateur web , affiche le contenu de la page sur un terminal d'affichage , conformément à ses instructions de balisage HTML .
Les liens hypertextes entre les pages web permettent au lecteur de comprendre la structure du site et facilitent sa navigation. Celle-ci commence généralement par une page d'accueil présentant le répertoire des contenus . Certains sites web exigent une inscription ou un abonnement pour accéder à leur contenu. Parmi les exemples de sites web sur abonnement, on peut citer de nombreux sites d'entreprises, d'actualités, de revues scientifiques , de jeux en ligne, de partage de fichiers, de forums , de messagerie électronique , de réseaux sociaux , de sites proposant des cotations en temps réel pour différents marchés, ainsi que des sites offrant divers autres services. Les utilisateurs peuvent accéder aux sites web depuis différents appareils, notamment les ordinateurs de bureau et portables , les tablettes , les smartphones et les téléviseurs connectés .
Navigateur
Un navigateur web (communément appelé navigateur ) est un logiciel permettant d'accéder aux informations sur le Web. Pour se connecter au serveur d'un site web et afficher ses pages, un utilisateur a besoin d'un navigateur web. C'est ce programme que l'utilisateur exécute pour télécharger, mettre en forme et afficher une page web sur son ordinateur.
En plus de permettre aux utilisateurs de trouver, d'afficher et de naviguer entre les pages Web, un navigateur Web possède généralement des fonctionnalités telles que la conservation des signets, l'enregistrement de l'historique, la gestion des cookies (voir ci-dessous) et des pages d'accueil, et peut également disposer de fonctionnalités permettant d'enregistrer les mots de passe pour se connecter aux sites Web.
Les navigateurs les plus populaires sont Chrome , Safari , Edge , Samsung Internet et Firefox .
Serveur

Un serveur web est un logiciel serveur , ou un matériel dédié à l'exécution de ce logiciel, capable de répondre aux requêtes des clients du World Wide Web. Un serveur web peut généralement héberger un ou plusieurs sites web. Il traite les requêtes réseau entrantes via HTTP et plusieurs autres protocoles associés.
La fonction principale d'un serveur web est de stocker, traiter et diffuser des pages web aux clients . La communication entre le client et le serveur s'effectue via le protocole de transfert hypertexte (HTTP) . Les pages diffusées sont le plus souvent des documents HTML , qui peuvent inclure des images , des feuilles de style et des scripts en plus du contenu textuel.

Un agent utilisateur , généralement un navigateur web ou un robot d'exploration , initie la communication en effectuant une requête HTTP pour une ressource spécifique. Le serveur répond en fournissant le contenu de cette ressource ou un message d'erreur en cas d'impossibilité. La ressource est généralement un fichier physique stocké sur le serveur , mais cela peut varier selon l' implémentation du serveur web .
Bien que sa fonction principale soit de diffuser du contenu, une implémentation complète du protocole HTTP inclut également la réception de contenu provenant des clients. Cette fonctionnalité est utilisée pour soumettre des formulaires web , notamment pour le téléchargement de fichiers.
De nombreux serveurs web génériques prennent également en charge les scripts utilisant Active Server Pages (ASP), PHP (Hypertext Preprocessor) ou d'autres langages de script . Cela signifie que le comportement du serveur web peut être défini dans des fichiers séparés, tandis que le logiciel serveur lui-même reste inchangé. Généralement, cette fonctionnalité est utilisée pour générer dynamiquement des documents HTML (« à la volée ») plutôt que de renvoyer des documents statiques . La génération dynamique est principalement utilisée pour récupérer ou modifier des informations provenant de bases de données . La génération statique est généralement beaucoup plus rapide et plus facile à mettre en cache, mais ne permet pas de diffuser du contenu dynamique .
On trouve fréquemment des serveurs web intégrés à des périphériques tels que les imprimantes , les routeurs et les webcams , desservant uniquement un réseau local . Le serveur web peut alors servir de composant à un système de surveillance ou d'administration du périphérique concerné. En général, cela signifie qu'aucun logiciel supplémentaire n'est requis sur l'ordinateur client, un simple navigateur web suffisant (désormais inclus dans la plupart des systèmes d'exploitation ).
Réseaux optiques
Les réseaux optiques constituent une infrastructure sophistiquée qui utilise la fibre optique pour transmettre des données sur de longues distances, reliant pays, villes et même résidences privées. Cette technologie utilise des microsystèmes optiques tels que des lasers accordables , des filtres, des atténuateurs , des commutateurs et des commutateurs sélectifs en longueur d'onde pour gérer et exploiter ces réseaux.
Le déploiement massif de fibres optiques à travers le monde à la fin du XXe siècle a jeté les bases d'Internet tel que nous le connaissons aujourd'hui. Cette autoroute de l'information repose largement sur les réseaux optiques, une méthode de transmission de messages codés en lumière permettant de relayer l'information dans divers réseaux de télécommunications.
Le réseau ARPANET (Advanced Research Projects Agency Network ) fut l'une des premières versions d'Internet, créé en collaboration avec des universités et des chercheurs en 1969. Cependant, l'accès à l'ARPANET était limité aux chercheurs, et en 1985, la National Science Foundation a fondé le NSFNET ( National Science Foundation Network ), un programme qui offrait aux chercheurs un accès aux supercalculateurs.
L’accès public limité à Internet a engendré des pressions de la part des consommateurs et des entreprises en faveur de la privatisation du réseau. En 1993, les États-Unis ont adopté la loi sur l’infrastructure nationale de l’information (National Information Infrastructure Act ), qui stipulait que la Fondation nationale pour la science (National Science Foundation) devait céder le contrôle des capacités optiques à des opérateurs commerciaux.
La privatisation d'Internet et la mise à disposition du World Wide Web au public en 1993 ont entraîné une augmentation de la demande en capacités Internet. Ceci a incité les développeurs à rechercher des solutions pour réduire le temps et le coût de déploiement de la fibre optique et augmenter la quantité d'informations pouvant être transmises sur une seule fibre, afin de répondre aux besoins croissants du public.
En 1994, la division des composants optiques de Pirelli SpA a introduit un système de multiplexage par répartition en longueur d'onde (WDM) afin de répondre à la demande croissante de transmission de données. Cette technologie WDM à quatre canaux permettait d'envoyer simultanément davantage d'informations sur une seule fibre optique, augmentant ainsi la capacité du réseau.
Pirelli n'était pas la seule entreprise à avoir développé un système WDM ; une autre société, Ciena Corporation (Ciena), a créé sa propre technologie pour transmettre des données plus efficacement. David Huber , ingénieur en réseaux optiques, et l'entrepreneur Kevin Kimberlin ont fondé Ciena en 1992. S'appuyant sur la technologie laser de Gordon Gould et William Culver d' Optelecom, Inc. , l'entreprise s'est concentrée sur l'utilisation d'amplificateurs optiques pour transmettre des données par la lumière. Sous la direction de son PDG, Pat Nettles, Ciena a développé un amplificateur optique à deux étages pour le multiplexage dense en longueur d'onde (DWDM), breveté en 1997 et déployé sur le réseau Sprint en 1996.
Cookie
Un cookie HTTP (également appelé cookie web , cookie Internet , cookie de navigateur ou simplement cookie ) est un petit fichier de données envoyé par un site web et stocké sur l'ordinateur de l'utilisateur par son navigateur pendant sa navigation. Les cookies ont été conçus comme un mécanisme fiable permettant aux sites web de mémoriser des informations (comme les articles ajoutés au panier d'une boutique en ligne) ou d'enregistrer l'activité de navigation de l'utilisateur (notamment les clics sur certains boutons, la connexion à un site ou les pages consultées). Ils peuvent également servir à mémoriser des informations saisies par l'utilisateur dans des formulaires, telles que ses nom, adresse, mot de passe et numéro de carte bancaire.
Les cookies jouent un rôle essentiel sur le web moderne. Plus important encore, les cookies d'authentification constituent la méthode la plus courante utilisée par les serveurs web pour savoir si l'utilisateur est connecté et, le cas échéant, avec quel compte. Sans ce mécanisme, le site ne saurait pas s'il doit envoyer une page contenant des informations sensibles ou exiger une authentification. La sécurité d'un cookie d'authentification dépend généralement de la sécurité du site web émetteur et du navigateur de l'utilisateur, ainsi que du chiffrement des données du cookie. Des failles de sécurité peuvent permettre à un pirate informatique de lire les données d'un cookie , de les utiliser pour accéder aux données de l'utilisateur ou, avec ses identifiants, d'accéder au site web auquel le cookie appartient (voir par exemple les attaques XSS et CSRF ).
Les cookies de suivi, et en particulier les cookies de suivi tiers, sont couramment utilisés comme moyens de compiler des enregistrements à long terme de l'historique de navigation des individus – un problème potentiel de confidentialité qui a incité les législateurs européens et américains à prendre des mesures en 2011. La loi européenne exige que tous les sites Web ciblant les États membres de l'Union européenne obtiennent le « consentement éclairé » des utilisateurs avant de stocker des cookies non essentiels sur leur appareil.
Jann Horn, chercheur au sein du projet Zero de Google, décrit comment les cookies peuvent être lus par des intermédiaires , tels que les fournisseurs de points d'accès Wi-Fi . Dans ce cas, il recommande d'utiliser le navigateur en mode de navigation privée (communément appelé mode Incognito dans Google Chrome).
moteur de recherche
Un moteur de recherche web , ou moteur de recherche Internet , est un logiciel conçu pour effectuer des recherches sur le Web , c'est -à-dire explorer le World Wide Web de manière systématique afin de trouver des informations spécifiques, telles que spécifiées dans une requête . Les résultats de recherche sont généralement présentés sous forme de liste, souvent appelée page de résultats de recherche (SERP). Ces informations peuvent inclure des pages web , des images, des vidéos, des infographies, des articles, des documents de recherche et d'autres types de fichiers. Certains moteurs de recherche exploitent également les données disponibles dans des bases de données ou des répertoires publics . Contrairement aux répertoires web , qui sont uniquement gérés par des modérateurs humains, les moteurs de recherche maintiennent des informations en temps réel grâce à un algorithme exécuté par un robot d'exploration du Web . Le contenu Internet qui n'est pas indexé par un moteur de recherche web est généralement qualifié de web profond .
En 1990, Archie , le premier moteur de recherche au monde, a été lancé. Cette technologie reposait initialement sur un index des sites FTP ( File Transfer Protocol ), une méthode de transfert de fichiers entre un client et un serveur au sein d'un réseau. Ce premier outil de recherche a été supplanté par des moteurs plus performants tels que Yahoo! en 1995 et Google en 1998.
Web profond
Le web profond, le web invisible , ou le web caché désigne les parties du Web dont le contenu n'est pas indexé par les moteurs de recherche classiques . Le terme opposé est le web de surface , accessible à tous les internautes. C'est au chercheur en informatique Michael K. Bergman qu'est attribué l'invention du terme « web profond » en 2001, dans le cadre de l'indexation des moteurs de recherche.
Le contenu du web profond est caché derrière des formulaires HTTP , et comprend de nombreuses utilisations très courantes telles que la messagerie web , les services bancaires en ligne et des services que les utilisateurs doivent payer et qui sont protégés par un mur payant , comme la vidéo à la demande , certains magazines et journaux en ligne, entre autres.
Le contenu du web profond peut être localisé et consulté via une URL directe ou une adresse IP et peut nécessiter un mot de passe ou un autre dispositif de sécurité pour accéder à l'information au-delà de la page web publique.
Mise en cache
Un cache web est un serveur, accessible sur Internet ou au sein d'une entreprise, qui stocke les pages web récemment consultées afin d'améliorer le temps de réponse pour les utilisateurs lorsque le même contenu est demandé peu de temps après la requête initiale. La plupart des navigateurs web implémentent également un cache en enregistrant les données récemment obtenues sur un périphérique de stockage local. Les requêtes HTTP d'un navigateur peuvent ne demander que les données modifiées depuis le dernier accès. Les pages web et les ressources peuvent contenir des informations d'expiration pour contrôler la mise en cache et sécuriser les données sensibles, comme dans le cas des services bancaires en ligne , ou pour faciliter la mise à jour fréquente de sites tels que les médias d'actualités. Même les sites au contenu très dynamique peuvent limiter l'actualisation des ressources de base à des périodes ponctuelles. Les concepteurs de sites web ont intérêt à regrouper les ressources telles que les données CSS et JavaScript dans quelques fichiers communs à l'ensemble du site afin d'optimiser leur mise en cache. Les pare-feu d'entreprise mettent souvent en cache les ressources web demandées par un utilisateur pour le bénéfice de tous. Certains moteurs de recherche stockent le contenu en cache des sites web fréquemment consultés.
Sécurité
Pour les criminels , le Web est devenu un vecteur de diffusion de logiciels malveillants et un moyen de perpétrer diverses cybercrimes , notamment (mais pas exclusivement) l'usurpation d'identité , la fraude , l'espionnage et la collecte de renseignements . Les vulnérabilités du Web sont désormais plus nombreuses que les problèmes de sécurité informatique traditionnels, et, selon Google , environ une page Web sur dix pourrait contenir du code malveillant. La plupart des attaques Web ciblent des sites web légitimes et, d'après Sophos , la plupart sont hébergés aux États-Unis, en Chine et en Russie. La menace la plus courante est l' injection SQL . Avec le HTML et les URI, le Web était vulnérable aux attaques de type cross-site scripting (XSS), apparues avec l'introduction de JavaScript et exacerbées par le Web 2.0 et la conception Web Ajax , qui privilégie l'utilisation de scripts. Selon une estimation de 2007, 70 % des sites web sont vulnérables aux attaques XSS. L’hameçonnage est une autre menace courante sur le web. En février 2013, RSA (la division sécurité d’EMC) estimait les pertes mondiales dues à l’hameçonnage à 1,5 milliard de dollars en 2012. La redirection cachée et la redirection ouverte sont deux méthodes d’hameçonnage bien connues.
Les solutions proposées sont diverses. De grandes entreprises de sécurité comme McAfee conçoivent déjà des suites de gouvernance et de conformité pour répondre aux réglementations post-11 septembre , et certaines, comme Finjan Holdings, recommandent une inspection active en temps réel du code source et de tous les contenus, quelle que soit leur source . Certains estiment que les entreprises devraient considérer la sécurité web comme une opportunité commerciale plutôt que comme un centre de coûts , tandis que d'autres préconisent une gestion des droits numériques omniprésente et permanente, intégrée à l'infrastructure, pour remplacer les centaines d'entreprises qui sécurisent les données et les réseaux . Jonathan Zittrain affirme que le partage des responsabilités en matière de sécurité informatique entre les utilisateurs est de loin préférable au verrouillage d'Internet
Confidentialité
Chaque fois qu'un client demande une page web, le serveur peut identifier l' adresse IP de la requête . Les serveurs web enregistrent généralement les adresses IP dans un fichier journal . De plus, sauf configuration contraire, la plupart des navigateurs web conservent l'historique des pages consultées et mettent généralement une grande partie du contenu en cache localement. À moins que la communication entre le serveur et le navigateur n'utilise le protocole HTTPS, les requêtes et réponses web circulent en clair sur Internet et peuvent être consultées, enregistrées et mises en cache par des systèmes intermédiaires. Une autre façon de masquer les informations personnelles est d'utiliser un réseau privé virtuel (VPN) . Un VPN chiffre le trafic entre le client et le serveur VPN et masque l'adresse IP d'origine, réduisant ainsi le risque d'identification de l'utilisateur.
Lorsqu'une page web demande et que l'utilisateur fournit des informations personnelles identifiables (nom, adresse, adresse électronique, etc.), les entités web peuvent associer le trafic web actuel à cet individu. Si le site web utilise des cookies HTTP , l'authentification par nom d'utilisateur et mot de passe, ou d'autres techniques de suivi, il peut relier les visites précédentes et suivantes aux informations personnelles fournies. De cette manière, une organisation web peut élaborer un profil des personnes qui utilisent son ou ses sites. Elle peut ainsi constituer un dossier pour chaque individu, incluant des informations sur ses loisirs, ses préférences d'achat, sa profession et d'autres aspects de son profil démographique . Ces profils peuvent intéresser les spécialistes du marketing, les annonceurs et autres. Selon les conditions générales d'utilisation du site web et la législation locale applicable, les informations de ces profils peuvent être vendues, partagées ou transmises à d'autres organisations sans que l'utilisateur en soit informé. Pour la plupart des gens, cela se traduit simplement par quelques courriels inattendus dans leur boîte de réception ou des publicités étrangement ciblées sur une page web ultérieure. Pour d'autres, cela peut signifier que le temps consacré à un intérêt inhabituel peut entraîner un déluge de publicités ciblées indésirables. Les forces de l'ordre, les services de lutte contre le terrorisme et les services d'espionnage peuvent également identifier, cibler et suivre des individus en fonction de leurs centres d'intérêt ou de leurs penchants sur Internet.
Les réseaux sociaux incitent généralement les utilisateurs à utiliser leurs vrais noms, centres d'intérêt et localisations, plutôt que des pseudonymes, car leurs dirigeants estiment que cela rend l'expérience plus attrayante. Cependant, les photos ou déclarations imprudentes publiées peuvent permettre d'identifier une personne, qui pourrait regretter cette exposition. Les employeurs, les établissements scolaires, les parents et autres proches peuvent être influencés par des éléments des profils, tels que les publications textuelles ou les photos numériques, que l'auteur n'avait pas l'intention de diffuser auprès de ces publics. Les cyberharceleurs peuvent utiliser ces informations personnelles pour harceler ou traquer les utilisateurs. Les réseaux sociaux modernes offrent un contrôle précis des paramètres de confidentialité pour chaque publication, mais ces options peuvent être complexes et difficiles à trouver ou à utiliser, surtout pour les débutants. Les photos et vidéos publiées en ligne posent des problèmes particuliers, car elles peuvent ajouter le visage d'une personne à un profil. Grâce aux technologies de reconnaissance faciale actuelles et potentielles , il sera alors possible d'associer ce visage à d'autres images, événements et situations, auparavant anonymes, photographiés ailleurs. En raison de la mise en cache, de la duplication et de la copie des images, il est difficile de supprimer une image du World Wide Web.
normes
Les standards du Web regroupent de nombreuses normes et spécifications interdépendantes, dont certaines régissent différents aspects d' Internet , et pas seulement du Web. Même lorsqu'elles ne sont pas spécifiquement dédiées au Web, ces normes influencent directement ou indirectement le développement et l'administration des sites web et des services en ligne . Parmi les aspects à prendre en compte figurent l' interopérabilité , l'accessibilité et l'ergonomie des pages et des sites web.
Les normes du Web, au sens large, comprennent les éléments suivants :
- Recommandations publiées par le World Wide Web Consortium (W3C)
- « Norme vivante » élaborée par le groupe de travail WHATWG ( Web Hypertext Application Technology Working Group )
- Documents de demande de commentaires (RFC) publiés par l' Internet Engineering Task Force (IETF)
- Normes publiées par l’ Organisation internationale de normalisation (ISO)
- Normes publiées par Ecma International (anciennement ECMA)
- La norme Unicode et divers rapports techniques Unicode (UTR) publiés par le Consortium Unicode
- Registres de noms et de numéros tenus par l' Internet Assigned Numbers Authority (IANA)
Les standards du Web ne sont pas des ensembles de règles figées, mais des ensembles de spécifications techniques finalisées et en constante évolution pour les technologies Web. Ils sont élaborés par des organismes de normalisation – des groupes de parties prenantes, souvent concurrentes, chargées de la normalisation – et non par une seule personne ou entreprise qui développe et déclare standard des technologies. Il est essentiel de distinguer les spécifications en cours d'élaboration de celles qui ont déjà atteint leur stade final (dans le cas des spécifications du W3C , le niveau de maturité le plus élevé).
Accessibilité
Il existe des méthodes d'accès au Web sur des supports et dans des formats alternatifs afin de faciliter son utilisation par les personnes en situation de handicap . Ces handicaps peuvent être visuels, auditifs, physiques, de la parole, cognitifs, neurologiques ou une combinaison de ces handicaps. Les fonctionnalités d'accessibilité aident également les personnes souffrant d'un handicap temporaire, comme une fracture du bras, ou les utilisateurs vieillissants dont les capacités évoluent. Le Web reçoit et diffuse des informations et interagit avec la société. Le World Wide Web Consortium affirme qu'il est essentiel que le Web soit accessible afin de garantir l'égalité d'accès et l'égalité des chances aux personnes en situation de handicap. Tim Berners-Lee a déclaré : « La force du Web réside dans son universalité. L'accès pour tous, quel que soit le handicap, est un aspect essentiel. » De nombreux pays réglementent l'accessibilité du Web comme une exigence pour les sites web. La coopération internationale au sein de l' Initiative pour l'accessibilité du Web ( WAI) du W3C a abouti à des lignes directrices simples que les auteurs de contenu web et les développeurs de logiciels peuvent utiliser pour rendre le Web accessible aux personnes qui utilisent ou non des technologies d'assistance .
Internationalisation

Le groupe de travail sur l'internationalisation du W3C veille à ce que les technologies web fonctionnent dans toutes les langues, avec tous les systèmes d'écriture et dans toutes les cultures. À partir de 2004 ou 2005, Unicode a gagné du terrain et a finalement, en décembre 2007, supplanté l'ASCII et l'ASCII occidental comme système de caractères le plus utilisé sur le Web . Initialement, la RFC 3986 autorisait l'identification des ressources par URI dans un sous-ensemble de l'ASCII américain. La RFC 3987 autorise davantage de caractères – tous les caractères du jeu de caractères universel – et une ressource peut désormais être identifiée par IRI dans n'importe quelle langue.