Pour permettre l'encodage sémantique des données, des technologies telles que le Resource Description Framework (RDF) et le Web Ontology Language (OWL) sont utilisées. Ces technologies servent à représenter formellement les métadonnées . Par exemple, une ontologie peut décrire des concepts , les relations entre entités et les catégories d'objets. Cette sémantique intégrée offre des avantages significatifs, comme le raisonnement sur les données et l'exploitation de sources de données hétérogènes . Ces normes favorisent des formats de données et des protocoles d'échange communs sur le Web, notamment le RDF. Selon le W3C, « le Web sémantique fournit un cadre commun permettant le partage et la réutilisation des données au-delà des frontières des applications, des entreprises et des communautés » . Le Web sémantique est donc considéré comme un intégrateur entre différentes applications et systèmes de contenu et d'information.
Tim Berners-Lee pour désigner un réseau de données (ou web de données ) pouvant être traité par des machines — c’est-à-dire un réseau dont une grande partie du sens est lisible par machine . Si ses détracteurs ont mis en doute sa faisabilité, ses partisans affirment que des applications en bibliothéconomie et sciences de l’information , dans l’industrie, en biologie et en recherche en sciences humaines ont déjà prouvé la validité du concept original.L'idée d'ajouter une sémantique au Web est antérieure au terme lui-même. Berners-Lee a évoqué la nécessité d'une sémantique sur le Web lors de la première Conférence internationale sur le Web (W3C) en 1994 . En 1998, il a publié un document de conception intitulé « Semantic Web Roadmap », décrivant l'architecture d'un réseau de données exploitables par machine . Le premier brevet pour la création d'un Web sémantique a été déposé par Amit Sheth et al. le 30 octobre 2001
Berners-Lee a initialement exprimé sa vision du Web sémantique en 1999 comme suit :
Je rêve d'un Web où les ordinateurs seront capables d'analyser toutes les données qui y sont présentes : le contenu, les liens et les transactions entre les personnes et les ordinateurs. Le « Web sémantique », qui rend cela possible, n'a pas encore vu le jour, mais lorsqu'il émergera, les mécanismes quotidiens du commerce, de la bureaucratie et de notre vie de tous les jours seront gérés par des machines communiquant entre elles. Les « agents intelligents » dont on parle depuis des siècles deviendront enfin réalité.
L’article de 2001 paru dans Scientific American et signé par Berners-Lee, Hendler et Lassila décrivait l’évolution attendue du Web existant vers un Web sémantique. En 2006, Berners-Lee et ses collègues affirmaient : « Cette idée simple… reste largement lettre morte. » En 2013, plus de quatre millions de domaines Web (sur un total d’environ 250 millions) contenaient du balisage Web sémantique.
Exemple
Dans l'exemple suivant, le texte « Paul Schuster est né à Dresde » sur un site web sera annoté, reliant ainsi une personne à son lieu de naissance. L' extrait HTML suivant montre comment un petit graphe est décrit, en syntaxe RDFa, à l'aide d'un vocabulaire schema.org et d'un identifiant Wikidata :

Les triplets donnent le graphique illustré dans la figure donnée .
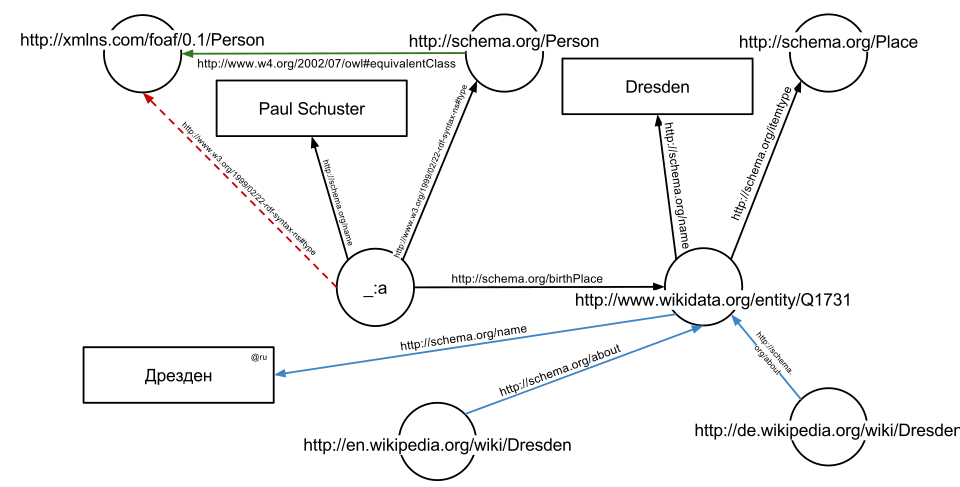
L'un des avantages de l'utilisation des URI (Uniform Resource Identifiers) est leur déréférencement possible via le protocole HTTP . Conformément aux principes des données ouvertes liées , un tel déréférencement d'URI devrait aboutir à un document fournissant des informations complémentaires sur l'URI en question. Dans cet exemple, tous les URI, qu'il s'agisse des arêtes ou des nœuds (par exemple, `<a>` , `<b> OWL (ligne pointillée rouge sur la deuxième figure) :
Nombre de technologies proposées par le W3C existaient déjà avant d'être intégrées à cette organisation. Elles sont utilisées dans divers contextes, notamment ceux qui traitent d'informations relevant d'un domaine limité et défini, et où le partage de données est une nécessité courante, comme dans la recherche scientifique ou les échanges de données entre entreprises. Par ailleurs, d'autres technologies aux objectifs similaires ont vu le jour, telles que les microformats .
Limitations du HTML
Sur un ordinateur classique, on peut classer de manière générale les fichiers en deux catégories : les documents lisibles par l’humain et les données lisibles par la machine. Les courriels, les rapports et les brochures sont des exemples de documents lisibles par l’humain. Les calendriers, les carnets d’adresses, les listes de lecture et les tableurs sont des exemples de données lisibles par la machine ; ces fichiers sont présentés à l’utilisateur via une application permettant de les consulter, de les rechercher et de les fusionner.
Actuellement, le Web repose principalement sur des documents écrits en HTML ( Hypertext Markup Language ), un langage de balisage utilisé pour coder un texte agrémenté d'objets multimédias tels que des images et des formulaires interactifs. Les métadonnées permettent aux ordinateurs de catégoriser le contenu des pages Web. Dans les exemples ci-dessous, les champs « mots-clés », « description » et « auteur » se voient attribuer des valeurs telles que « informatique », « gadgets bon marché à vendre » et « John Doe ».
Grâce à ce balisage et à cette catégorisation des métadonnées, les autres systèmes informatiques qui souhaitent accéder à ces données et les partager peuvent facilement identifier les valeurs pertinentes.
Grâce au HTML et à un outil d'affichage ( un navigateur web ou un autre agent utilisateur ), il est possible de créer et d'afficher une page listant des articles à vendre. Le code HTML de cette page catalogue peut formuler des assertions simples au niveau du document, telles que « le titre de ce document est "Widget Superstore » , mais il est impossible, en HTML lui-même, d'affirmer sans ambiguïté que, par exemple, l'article numéro X586172 est un gadget Acme au prix de 199 €, ou qu'il s'agit d'un produit de consommation. Le HTML peut seulement indiquer que l'élément de texte « X586172 » doit être placé à proximité de « Gizmo Acme » et « 199 € », etc. Il est impossible de préciser « ceci est un catalogue », ni même d'établir que « Gizmo Acme » est un titre ou que « 199 € » est un prix. Il est également impossible d'exprimer que ces informations sont liées entre elles pour décrire un article précis, distinct des autres articles éventuellement listés sur la page.
Le HTML sémantique désigne la pratique traditionnelle du balisage HTML qui consiste à suivre l'intention plutôt que de spécifier directement les détails de mise en page. Par exemple, on utilise `<em>` pour indiquer l'emphase plutôt que `</em>` , qui spécifie l'italique . Les détails de mise en page sont laissés à la discrétion du navigateur, en combinaison avec les feuilles de style en cascade (CSS ). Cependant, cette pratique ne permet pas de spécifier la sémantique d'objets tels que les articles en vente ou leurs prix.
Les microformats étendent la syntaxe HTML pour créer un balisage sémantique lisible par machine sur des objets tels que des personnes, des organisations, des événements et des produits. Des initiatives similaires incluent RDFa , Microdata et Schema.org .
Solutions Web sémantiques
Le Web sémantique pousse la solution plus loin. Il consiste à publier dans des langages spécifiquement conçus pour les données : RDF ( Resource Description Framework ), OWL ( Web Ontology Language ) et XML (Extensible Markup Language ). HTML décrit les documents et les liens qui les unissent. RDF, OWL et XML, en revanche, peuvent décrire des éléments aussi divers que des personnes, des réunions ou des pièces d’avion.
Ces technologies sont combinées afin de fournir des descriptions qui complètent ou remplacent le contenu des documents Web. Ainsi, le contenu peut se manifester sous forme de données descriptives stockées dans des bases de données accessibles via le Web , ou sous forme de balisage au sein des documents (notamment en HTML extensible ( XHTML ) mêlé à du XML, ou, plus souvent, uniquement en XML, avec des indications de mise en page ou de rendu stockées séparément). Ces descriptions lisibles par machine permettent aux gestionnaires de contenu d'enrichir le contenu de sens, c'est-à-dire de décrire la structure des connaissances que nous possédons à son sujet. De cette manière, une machine peut traiter elle-même les connaissances, et non le texte, en utilisant des processus similaires au raisonnement déductif et à l'inférence humaine , obtenant ainsi des résultats plus pertinents et permettant aux ordinateurs d'effectuer des recherches et des collectes d'informations automatisées.
Voici un exemple de balise qui serait utilisée dans une page web non sémantique :
Tim Berners-Lee nomme le réseau de données liées « Géant Graphique Mondial » , par opposition au Web basé sur HTML. Il affirme que si le passé était celui du partage de documents, l'avenir est celui du partage de données . Sa réponse à la question du « comment » repose sur trois principes : premièrement, une URL doit pointer vers les données ; deuxièmement, toute personne accédant à cette URL doit obtenir les données en retour ; troisièmement, les relations entre les données doivent pointer vers d'autres URL contenant des données.
Étiquettes et identifiants
Les étiquettes , y compris les catégories hiérarchiques et les étiquettes ajoutées et maintenues de manière collaborative (par exemple avec les folksonomies ), peuvent être considérées comme faisant partie de la vision du Web sémantique, comme potentiellement utiles à celle-ci ou comme une étape vers celle-ci.
Des identifiants uniques , y compris des catégories hiérarchiques et celles ajoutées collaborativement, des outils d'analyse et des métadonnées , notamment des balises, peuvent être utilisés pour créer des formes de Web sémantiques – des Web qui sont, dans une certaine mesure, sémantiques . En particulier, cela a été utilisé pour structurer la recherche scientifique par sujets de recherche et domaines scientifiques par les projets OpenAlex , Wikidata et Scholia qui sont en cours de développement et fournissent des API , des pages Web, des flux et des graphiques pour diverses requêtes sémantiques .
Web 3.0
Tim Berners-Lee a décrit le Web sémantique comme une composante du Web 3.0.
graphismes vectoriels évolutifs – avec des effets de vague et de flou – au Web 2.0 et qu'on accède à un Web sémantique intégré à un immense espace de données, on dispose d'une ressource de données incroyable…— Tim Berners-Lee, 2006
« Web sémantique » est parfois utilisé comme synonyme de « Web 3.0 », bien que la définition de chaque terme varie.
Au-delà du Web 3.0
La prochaine génération du Web est souvent appelée Web 4.0, mais sa définition reste floue. Selon certaines sources, il s'agit d'un Web intégrant l'intelligence artificielle , l' Internet des objets , l'informatique omniprésente et le Web des objets, entre autres concepts . D'après l'Union européenne, le Web 4.0 est « la quatrième génération attendue du World Wide Web. Grâce à l'intelligence artificielle et ambiante avancée, à l'Internet des objets, aux transactions blockchain sécurisées, aux mondes virtuels et aux capacités XR, les objets et environnements numériques et réels sont pleinement intégrés et communiquent entre eux, permettant des expériences véritablement intuitives et immersives, fusionnant harmonieusement les mondes physique et numérique »
Défis
Parmi les défis que représente le Web sémantique figurent son immensité, son imprécision, son incertitude, son incohérence et la tromperie. Les systèmes de raisonnement automatisé devront composer avec tous ces problèmes pour tenir la promesse du Web sémantique.
- Immense volume : Le Web contient des milliards de pages. L’ ontologie terminologique médicale SNOMED CT, à elle seule, compte 370 000 noms de classes , et les technologies actuelles ne permettent pas encore d’éliminer tous les termes sémantiquement dupliqués. Tout système de raisonnement automatisé devra traiter des volumes de données véritablement colossaux.
- Imprécision : Il s’agit de concepts imprécis comme « jeune » ou « grand ». Cette imprécision découle du caractère vague des requêtes des utilisateurs, des concepts représentés par les fournisseurs de contenu, de la difficulté à faire correspondre les termes de requête aux termes des fournisseurs et des tentatives de combiner différentes bases de connaissances aux concepts partiellement similaires. La logique floue est la technique la plus courante pour traiter cette imprécision.
- Incertitude : Il s’agit de concepts précis dont les valeurs sont incertaines. Par exemple, un patient peut présenter un ensemble de symptômes correspondant à plusieurs diagnostics distincts, chacun ayant une probabilité différente. On utilise généralement des techniques de raisonnement probabiliste pour traiter l’incertitude.
- Incohérence : Il s’agit de contradictions logiques qui surgissent inévitablement lors du développement d’ontologies de grande taille et lors de la combinaison d’ontologies provenant de sources distinctes. Le raisonnement déductif échoue lamentablement face à l’incohérence, car « tout découle d’une contradiction » . Le raisonnement déductif et le raisonnement paraconsistant sont deux techniques permettant de traiter l’incohérence.
- Tromperie : Il s’agit d’une situation où le producteur de l’information induit intentionnellement en erreur le consommateur. Les techniques de cryptographie sont actuellement utilisées pour atténuer cette menace. Elles permettent de vérifier l’intégrité de l’information, notamment en ce qui concerne l’identité de l’entité qui l’a produite ou publiée. Toutefois, en cas de suspicion de tromperie, les questions de crédibilité restent à résoudre.
Cette liste de défis est indicative et non exhaustive ; elle se concentre sur les difficultés liées aux couches de « logique unificatrice » et de « preuve » du Web sémantique. Le rapport final du groupe d’incubation du Consortium World Wide Web (W3C) pour le raisonnement sur l’incertitude dans le cadre du Web (URW3-XG) regroupe ces problèmes sous l’appellation unique d’« incertitude » . Nombre des techniques mentionnées ici nécessiteront des extensions du langage d’ontologie Web (OWL), par exemple pour annoter les probabilités conditionnelles. Ce domaine fait l’objet de recherches actives
normes
La normalisation du Web sémantique dans le contexte du Web 3.0 est sous la responsabilité du W3C.
Composants
Le terme « Web sémantique » est souvent utilisé plus spécifiquement pour désigner les formats et les technologies qui le rendent possible. La collecte, la structuration et la récupération des données liées sont rendues possibles par des technologies qui fournissent une description formelle des concepts, des termes et des relations au sein d’un domaine de connaissances donné . Ces technologies sont spécifiées par les normes du W3C et comprennent :
- Le Resource Description Framework (RDF) est une méthode générale de description des informations.
- Schéma RDF (RDFS)
- Système simple d'organisation des connaissances (SKOS)
- SPARQL , un langage de requête RDF
- Notation3 (N3), conçue pour être lisible par l'homme.
- N-Triples , un format de stockage et de transmission de données
- Tortue (Langage RDF triple concis)
- Le langage d'ontologie Web (OWL) est une famille de langages de représentation des connaissances.
- Le format d'échange de règles (RIF) est un cadre de dialectes de langages de règles Web prenant en charge l'échange de règles sur le Web.
- JSON-LD ( JavaScript Object Notation for Linked Data ) est une méthode basée sur JSON pour décrire les données.
- ActivityPub est un protocole générique permettant la communication entre un client et un serveur. Il est utilisé par le réseau social décentralisé Mastodon .
La pile Web sémantique illustre l'architecture du Web sémantique. Les fonctions et les relations des composants peuvent être résumées comme suit :
- XML fournit une syntaxe élémentaire pour la structure du contenu des documents, mais n'associe aucune sémantique à la signification de ce contenu. Actuellement, XML n'est généralement pas un composant indispensable des technologies du Web sémantique, car des syntaxes alternatives existent, comme Turtle . Turtle est un standard de facto, mais n'a pas fait l'objet d'un processus de normalisation formel.
- XML Schema est un langage permettant de définir et de restreindre la structure et le contenu des éléments contenus dans les documents XML.
- RDF est un langage simple permettant d'exprimer des modèles de données , qui font référence à des objets (« ressources web ») et à leurs relations. Un modèle basé sur RDF peut être représenté selon diverses syntaxes, par exemple RDF/XML , N3, Turtle et RDFa. RDF est une norme fondamentale du Web sémantique.
- RDF Schema étend RDF et constitue un vocabulaire permettant de décrire les propriétés et les classes des ressources basées sur RDF, avec une sémantique pour les hiérarchies généralisées de ces propriétés et classes.
- OWL ajoute un vocabulaire plus étendu pour décrire les propriétés et les classes : entre autres, les relations entre les classes (par exemple la disjonction), la cardinalité (par exemple « exactement un »), l’égalité, un typage plus riche des propriétés, les caractéristiques des propriétés (par exemple la symétrie) et les classes énumérées.
- SPARQL est un protocole et un langage de requête pour les sources de données du Web sémantique.
- RIF est le format d'échange de règles du W3C. Il s'agit d'un langage XML permettant d'exprimer des règles Web exécutables par ordinateur. RIF propose plusieurs versions, appelées dialectes. Parmi celles-ci, on trouve le dialecte RIF Basic Logic (RIF-BLD) et le dialecte RIF Production Rules (RIF PRD).
État actuel de la normalisation
Normes bien établies :
- RDF - Cadre de description des ressources
- RDFS - Schéma du cadre de description des ressources
- RIF - Format d'échange de règles
- SPARQL - « Protocole SPARQL et langage de requête RDF »
- Unicode
- URI - Identifiant uniforme de ressource
- OWL - Langage d'ontologie Web
- XML - Langage de balisage extensible
Pas encore pleinement réalisé :
- Couches logiques et de preuve unifiées
- SWRL - Langage de règles du Web sémantique
Applications
L'objectif est d'améliorer la convivialité et l'utilité du Web et de ses ressources interconnectées en créant des services Web sémantiques , tels que :
- Les serveurs exposent les systèmes de données existants en utilisant les standards RDF et SPARQL. De nombreux convertisseurs vers RDF existent pour différentes applications. Les bases de données relationnelles constituent une source importante. Le serveur Web sémantique s'intègre au système existant sans en perturber le fonctionnement.
- Les documents sont « balisés » avec des informations sémantiques (une extension des
balises HTML utilisées sur les pages Web actuelles pour fournir des informations aux moteurs de recherche via des robots d'exploration ). Ces informations peuvent être compréhensibles par machine et relatives au contenu du document (tel que l'auteur, le titre, la description, etc.) ou de simples métadonnées représentant un ensemble de faits (comme les ressources et services disponibles sur le site). Tout élément identifiable par un URI ( Uniform Resource Identifier ) peut être décrit ; le Web sémantique peut ainsi traiter des animaux, des personnes, des lieux, des idées, etc. Quatre formats d'annotation sémantique sont utilisables dans les documents HTML : Microformat, RDFa, Microdata et JSON-LD . Le balisage sémantique est généralement généré automatiquement.

- Des vocabulaires de métadonnées communs ( ontologies ) et des correspondances entre les vocabulaires permettent aux créateurs de documents de savoir comment baliser leurs documents afin que les agents puissent utiliser les informations contenues dans les métadonnées fournies (afin que l'auteur au sens de « l'auteur de la page » ne soit pas confondu avec l'auteur au sens d'un livre qui fait l'objet d'une critique de livre).
- Des agents automatisés pour effectuer des tâches pour les utilisateurs du web sémantique à partir de ces données.
- Traduction sémantique . Une approche alternative ou complémentaire consiste à améliorer la compréhension contextuelle et sémantique des textes – celle-ci pourrait être facilitée par les méthodes du Web sémantique afin de réduire le nombre de traductions erronées à corriger manuellement ou semi-automatiser après la révision .
- Des services Web (souvent dotés de leurs propres agents) pour fournir des informations spécifiquement aux agents, par exemple un service de confiance qu'un agent pourrait demander si une boutique en ligne a des antécédents de mauvais service ou de spam .
- Les concepts du Web sémantique sont mis en œuvre dans des plateformes collaboratives de cartographie argumentative structurée où les relations entre les arguments sont organisées sémantiquement. Les arguments peuvent être dupliqués (liés) à plusieurs endroits, réutilisés (copiés), évalués et modifiés en tant qu'unités sémantiquement distinctes. L'idée d'un tel Web, ou d'un « Web mondial des arguments » plus largement adopté, remonte au moins à 2007 et a été partiellement implémentée dans Argüman et Kialo . Les prochaines étapes vers des services Web sémantiques pourraient inclure la possibilité d'effectuer des requêtes, de créer des moteurs de recherche d'arguments et de résumer les points litigieux et consensuels d'une discussion
Ces services pourraient être utiles aux moteurs de recherche publics ou servir à la gestion des connaissances au sein d'une organisation. Voici quelques exemples d'applications commerciales :
- Faciliter l’intégration des informations provenant de sources mixtes
- Levée des ambiguïtés dans la terminologie d'entreprise
- Améliorer la recherche d’informations, réduisant ainsi la surcharge d’informations et augmentant le raffinement et la précision des données récupérées
- Identification des informations pertinentes en rapport avec un domaine donné
- Fournir un soutien à la prise de décision
Au sein d'une entreprise, le groupe d'utilisateurs est restreint et la direction peut imposer des directives internes, comme l'adoption d'ontologies spécifiques et l'utilisation d' annotations sémantiques . Comparé au Web sémantique public, les exigences en matière d'évolutivité sont moindres et l'information circulant en interne est généralement plus fiable ; la protection de la vie privée est moins problématique, hormis pour le traitement des données clients.
Réactions sceptiques
faisabilité pratique
Les critiques remettent en question la faisabilité même d'une réalisation complète ou partielle du Web sémantique, soulignant à la fois les difficultés de sa mise en place et son manque d'utilité générale, ce qui empêche d'y investir les efforts nécessaires. Dans un article de 2003, Marshall et Shipman mettent en évidence la charge cognitive inhérente à la formalisation des connaissances, comparée à la création de contenu hypertexte web traditionnel :
tacite et évolutive d'une grande partie des connaissances complexifie le problème de l'ingénierie des connaissances et limite l'applicabilité du Web sémantique à des domaines spécifiques. Ils soulignent également que les modes d'expression des connaissances propres à chaque domaine ou organisation doivent être résolus par un consensus communautaire plutôt que par de simples moyens techniques. Il s'avère que les communautés et organisations spécialisées dans les projets internes aux entreprises ont eu tendance à adopter les technologies du Web sémantique plus fréquemment que les communautés périphériques et moins spécialisées. Les obstacles pratiques à l'adoption semblent moins importants lorsque le domaine et la portée sont plus restreints que pour le grand public et le Web.Enfin, Marshall et Shipman voient des problèmes pragmatiques dans l’idée d’agents intelligents ( de type Knowledge Navigator ) travaillant dans le Web sémantique largement organisé manuellement :
La critique de Cory Doctorow (« métacrap ») s'inscrit dans une perspective de comportement humain et de préférences personnelles. Par exemple, certains utilisateurs peuvent inclure des métadonnées erronées dans les pages web afin de tromper les moteurs du web sémantique qui présument naïvement de leur véracité. Ce phénomène était bien connu avec les métadonnées qui ont dupé l' algorithme de classement d'Altavista , améliorant ainsi le classement de certaines pages web : le moteur d'indexation de Google recherche spécifiquement de telles tentatives de manipulation. Peter Gärdenfors et Timo Honkela soulignent que les technologies du web sémantique basées sur la logique ne couvrent qu'une fraction des phénomènes pertinents liés à la sémantique.Censure et vie privée
L'enthousiasme suscité par le Web sémantique pourrait être tempéré par des préoccupations liées à la censure et au respect de la vie privée . Par exemple, les techniques d'analyse textuelle peuvent désormais être facilement contournées en utilisant d'autres mots, des métaphores par exemple, ou des images à la place des mots. Une implémentation avancée du Web sémantique faciliterait grandement le contrôle, par les gouvernements, de la consultation et de la création d'informations en ligne, car ces informations seraient bien plus faciles à comprendre pour un système automatisé de blocage de contenu. De plus, l'utilisation des fichiers FOAF et des métadonnées de géolocalisation soulève la question de l'anonymat, particulièrement réduit, des auteurs d'articles publiés sur des plateformes telles que les blogs personnels. Certaines de ces préoccupations ont été abordées dans le cadre du projet « Policy Aware Web » et font l'objet de recherches et de développements actifs.
Doublement des formats de sortie
Une autre critique du Web sémantique est qu'il serait beaucoup plus long de créer et de publier du contenu, car il faudrait deux formats pour une même donnée : un pour la lecture humaine et un pour les machines. Cependant, de nombreuses applications Web en développement s'attaquent à ce problème en créant un format lisible par machine lors de la publication des données ou lorsqu'une machine en fait la demande. Le développement des microformats constitue une réponse à ce type de critique. Un autre argument en faveur de la faisabilité du Web sémantique est la baisse probable du coût des tâches d'intelligence humaine sur les plateformes numériques comme Amazon Mechanical Turk .GRDDL (Gleaning Resource Descriptions from Dialects of Language) permet d'interpréter automatiquement les documents existants (y compris les microformats) au format RDF, ce qui permet aux éditeurs d'utiliser un seul format, comme HTML.
Activités de recherche sur les applications d'entreprise
Le premier groupe de recherche se concentrant explicitement sur le Web sémantique d'entreprise a été l'équipe ACACIA à l'INRIA-Sophia-Antipolis , fondée en 2002. Les résultats de leurs travaux comprennent le moteur de recherche Corese basé sur RDF(S) et l'application de la technologie du Web sémantique dans le domaine de l'intelligence artificielle distribuée pour la gestion des connaissances (par exemple, les ontologies et les systèmes multi-agents pour le Web sémantique d'entreprise) et l'apprentissage en ligne .
Depuis 2008, le groupe de recherche Corporate Semantic Web, situé à l' Université libre de Berlin , se concentre sur les éléments constitutifs : la recherche sémantique d'entreprise, la collaboration sémantique d'entreprise et l'ingénierie d'ontologies d'entreprise.
La recherche en ingénierie ontologique comprend la question de savoir comment impliquer des utilisateurs non experts dans la création d'ontologies et de contenu annoté sémantiquement et comment extraire des connaissances explicites de l'interaction des utilisateurs au sein des entreprises.
Avenir des applications
Tim O'Reilly , qui a inventé le terme Web 2.0, a proposé une vision à long terme du Web sémantique comme un réseau de données, où des applications sophistiquées naviguent et le manipulent. Le Web de données transforme le World Wide Web d'un système de fichiers distribué en une base de données distribuée .