En statistique , la corrélation est un type de relation statistique entre deux variables aléatoires ou données bivariées . Elle désigne généralement le degré de relation linéaire entre deux quantités . Plus généralement, une relation quelconque entre des variables est appelée association , c'est-à-dire la mesure dans laquelle la variabilité de l'une peut être expliquée par l'autre.
La présence d'une corrélation ne suffit pas à inférer l'existence d'une relation causale , et cela est souvent formulé ainsi : « corrélation n'implique pas causalité ». De plus, la notion de corrélation diffère de celle de dépendance : si deux variables sont indépendantes, elles ne sont pas corrélées, mais l'inverse n'est pas nécessairement vrai ; même si deux variables ne sont pas corrélées, elles peuvent être dépendantes l'une de l'autre.les conditions météorologiques extrêmes incitent les gens à consommer davantage d'électricité pour le chauffage ou la climatisation.
Plusieurs coefficients de corrélation permettent de mesurer la corrélation, souvent notés ρ ou ρ<sub>P</sub>. Le plus courant est le coefficient de corrélation de Pearson , sensible uniquement à une relation linéaire entre deux variables (qui peut exister même si l'une des variables est une fonction non linéaire de l'autre). D'autres coefficients de corrélation, comme le coefficient de corrélation de rang de Spearman , ont été développés pour être plus robustes que celui de Pearson et pour détecter des relations moins structurées entre les variables.
Le concept a été généralisé à d'autres formes d'association entre deux variables, telles que l'information mutuelle et la covariance de distance .
La mesure de dépendance la plus courante entre deux quantités est le coefficient de corrélation de Pearson, plus communément appelé « coefficient de corrélation de Pearson » ou simplement « coefficient de corrélation » (car c’est la variante la plus fréquente). Il s’obtient en calculant le rapport des covariances entre deux variables d’un ensemble de données numériques, normalisées par la racine carrée de leurs variances. De manière équivalente, le coefficient de corrélation de Pearson peut être calculé en divisant la covariance des deux variables par le produit de leurs écarts-types . Karl Pearson a développé ce coefficient à partir d’une idée similaire de Francis Galton .
Le coefficient de corrélation de Pearson permet d'établir une droite de régression linéaire pour un ensemble de données composé de deux variables. Il définit les valeurs attendues, et le coefficient de corrélation obtenu indique l'écart entre les données observées et ces valeurs attendues. Selon son signe, ce coefficient peut révéler une corrélation négative ou positive, indiquant ainsi l'existence d'une relation entre les variables.variables aléatoires et avec des valeurs attendues et et des écarts-types et est défini comme :
0." 
où Σ désigne l' opérateur d'espérance mathématique , Σ la covariance et ρ une notation alternative couramment utilisée pour le coefficient de corrélation. La corrélation de Pearson est définie uniquement si les deux écarts-types sont finis et positifs. Une formule alternative, exprimée uniquement en termes de moments, est :
Corrélation et indépendance
Il découle de l' inégalité de Cauchy-Schwarz que la valeur absolue du coefficient de corrélation de Pearson ne peut excéder 1. Par conséquent, ce coefficient se situe entre -1 et +1. Il vaut +1 en cas de corrélation linéaire directe (croissante) parfaite, -1 en cas d'anticorrélation linéaire inverse (décroissante) parfaite [7], et une valeur quelconque [ 0 , 1] dans tous les autres cas, indiquant le degré de dépendance linéaire entre les variables. Plus le coefficient tend vers zéro, plus la corrélation est faible (proximité à l'absence de corrélation). Plus le coefficient est proche de -1 ou de 1, plus la corrélation entre les variables est forte.
Si les variables sont indépendantes , le coefficient de corrélation de Pearson est nul. Cependant, comme ce coefficient ne détecte que les dépendances linéaires entre deux variables, la réciproque n'est pas nécessairement vraie. Un coefficient de corrélation de 0 n'implique pas que les variables sont indépendantes .
Par exemple, supposons que la variable aléatoire soit symétriquement distribuée autour de zéro et que . Alors est entièrement déterminée par , de sorte que et sont parfaitement dépendantes, mais leur corrélation est nulle ; elles sont non corrélées . Cependant, dans le cas particulier où et suivent conjointement une loi normale , la non-corrélation est équivalente à l'indépendance.
Même si des données non corrélées n'impliquent pas nécessairement l'indépendance, on peut vérifier si des variables aléatoires sont indépendantes si leur information mutuelle est nulle.
Coefficient de corrélation de l'échantillon
Étant donné une série de mesures de la paire indexée par , le coefficient de corrélation de l'échantillon peut être utilisé pour estimer la corrélation de Pearson de la population entre et . Le coefficient de corrélation de l'échantillon est défini comme
où et sont les moyennes d'échantillon de et , et et sont les écarts-types d'échantillon corrigés de et .
Les expressions équivalentes pour sont
où et sont les écarts-types d'échantillon non corrigés de et .
Si les données et sont issues de mesures comportant des erreurs de mesure, les limites réalistes du coefficient de corrélation ne sont pas comprises entre −1 et +1, mais dans un intervalle plus restreint. Dans le cas d'un modèle linéaire à une seule variable indépendante, le coefficient de détermination (R²) est le carré de , soit le coefficient de corrélation de Pearson.
Exemple
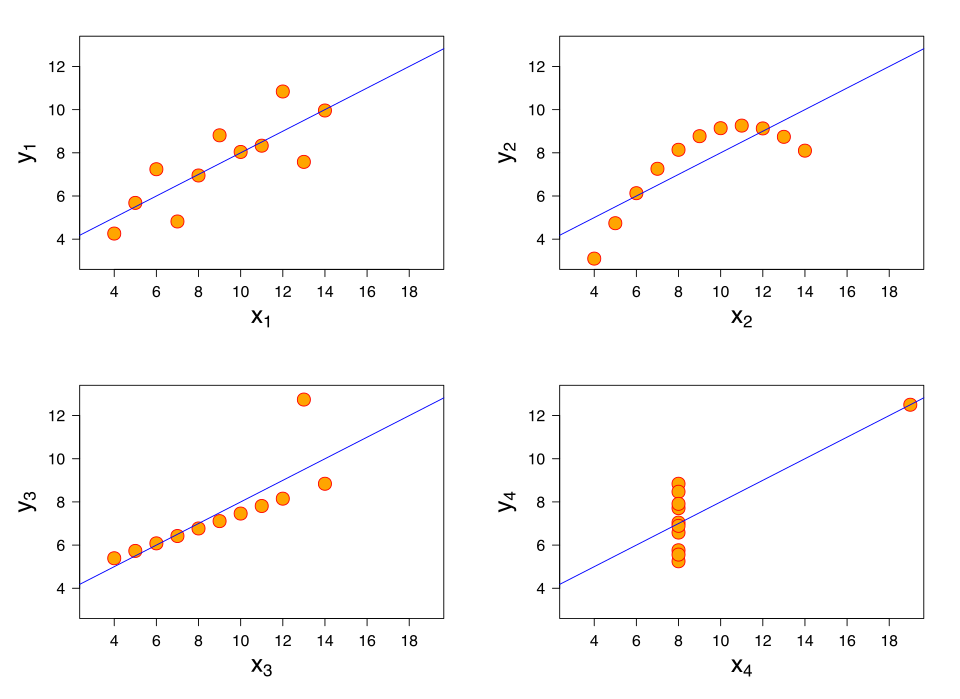
Considérons la distribution de probabilité conjointe de Il en résulte les attentes et les écarts suivants : Donc: Pour illustrer la nature de la corrélation de rang et sa différence avec la corrélation linéaire, considérons les quatre paires de nombres suivantes : Lorsqu'on passe d'une paire à l'autre, augmente, et augmente également . Cette relation est parfaite, dans le sens où une augmentation de s'accompagne toujours d'une augmentation de . Cela signifie que nous avons une corrélation de rang parfaite, et les coefficients de corrélation de Spearman et de Kendall sont tous deux égaux à 1, tandis que dans cet exemple, le coefficient de corrélation de Pearson est de 0,7544, indiquant que les points sont loin d'être alignés. De même, si diminue toujours lorsque augmente , les coefficients de corrélation de rang seront égaux à −1, tandis que le coefficient de corrélation de Pearson peut être proche ou non de −1, selon la proximité des points à une droite. Bien que, dans les cas extrêmes de corrélation de rang parfaite, les deux coefficients soient égaux (tous deux égaux à +1 ou tous deux égaux à −1), ce n'est généralement pas le cas, et les valeurs des deux coefficients ne peuvent donc pas être comparées de manière significative. Par exemple, pour les trois paires (1, 1) (2, 3) (3, 2), le coefficient de Spearman est de 1/2, tandis que le coefficient de Kendall est de 1/3. La corrélation entre l'âge et la taille chez l'enfant est relativement facile à expliquer, mais celle entre l'humeur et la santé chez l'adulte l'est beaucoup moins. Une meilleure humeur entraîne-t-elle une meilleure santé, ou une bonne santé favorise-t-elle une bonne humeur, ou les deux ? Ou bien un autre facteur intervient-il ? Autrement dit, une corrélation peut suggérer une relation causale possible, mais ne permet pas d'établir la nature de cette relation, le cas échéant. Le coefficient de corrélation de Pearson indique la force d'une relation linéaire entre deux variables, mais sa valeur ne caractérise généralement pas complètement cette relation. En particulier, si la moyenne conditionnelle de sachant , notée , n'est pas linéaire en , le coefficient de corrélation ne déterminera pas entièrement la forme de . L'image ci-contre présente les nuages de points du quartet d'Anscombe , un ensemble de quatre paires de variables différentes créé par Francis Anscombe . Ces quatre variables ont la même moyenne (7,5), la même variance (4,12), la même corrélation (0,816) et la même droite de régression . Cependant, comme on peut le constater sur les graphiques, la distribution des variables est très différente. La première (en haut à gauche) semble suivre une loi normale, ce qui correspond à ce que l'on attendrait pour deux variables corrélées, sous l'hypothèse de normalité. La deuxième (en haut à droite) ne suit pas une loi normale ; bien qu'une relation évidente entre les deux variables soit observable, elle n'est pas linéaire. Dans ce cas, le coefficient de corrélation de Pearson n'indique pas l'existence d'une relation fonctionnelle exacte : il indique seulement dans quelle mesure cette relation peut être approximée par une relation linéaire. Dans le troisième cas (en bas à gauche), la relation linéaire est parfaite, à l'exception d'une valeur aberrante qui exerce une influence suffisante pour faire baisser le coefficient de corrélation de 1 à 0,816. Enfin, le quatrième exemple (en bas à droite) montre un autre cas où une seule valeur aberrante suffit à produire un coefficient de corrélation élevé, même si la relation entre les deux variables n'est pas linéaire. Ces exemples indiquent que le coefficient de corrélation, en tant que statistique descriptive , ne peut se substituer à l'examen visuel des données. On prétend parfois que ces exemples démontrent que la corrélation de Pearson suppose que les données suivent une loi normale , mais cela n'est que partiellement exact. La corrélation de Pearson peut être calculée avec précision pour toute distribution possédant une matrice de covariance finie , ce qui inclut la plupart des distributions rencontrées en pratique. Cependant, le coefficient de corrélation de Pearson (conjugué à la moyenne et à la variance de l'échantillon) n'est une statistique suffisante que si les données sont issues d'une loi normale multivariée . Par conséquent, le coefficient de corrélation de Pearson caractérise pleinement la relation entre les variables si et seulement si les données sont issues d'une loi normale multivariée. De même, pour deux processus stochastiques et : s'ils sont indépendants, alors ils ne sont pas corrélés. L'inverse de cette affirmation n'est pas nécessairement vrai. Même si deux variables ne sont pas corrélées, elles peuvent ne pas être indépendantes l'une de l'autre. La sensibilité à la distribution des données peut être exploitée. Par exemple, la corrélation normalisée utilise cette sensibilité pour identifier les corrélations entre les composantes rapides des séries temporelles . En réduisant progressivement l'étendue des valeurs, les corrélations sur le long terme sont éliminées et seules celles sur le court terme sont mises en évidence. La matrice de corrélation des variables aléatoires est la matrice dont l'élément est Ainsi, tous les éléments diagonaux sont identiques et égaux à un . Si les mesures de corrélation utilisées sont les coefficients de corrélation de Pearson, la matrice de corrélation est identique à la matrice de covariance des variables aléatoires standardisées . Ceci s'applique aussi bien à la matrice des corrélations de population (où σ représente l'écart-type de la population) qu'à la matrice des corrélations d'échantillon (où σ représente l'écart-type de l'échantillon). Par conséquent, chaque matrice est nécessairement semi-définie positive . De plus, la matrice de corrélation est strictement définie positive si aucune variable ne peut avoir toutes ses valeurs exactement générées comme une fonction linéaire des valeurs des autres. La matrice de corrélation est symétrique car la corrélation entre et est la même que la corrélation entre et . Une matrice de corrélation apparaît, par exemple, dans une formule du coefficient de détermination multiple , une mesure de la qualité d'ajustement en régression multiple . In statistical modelling, correlation matrices representing the relationships between variables are categorized into different correlation structures, which are distinguished by factors such as the number of parameters required to estimate them. For example, in an exchangeable correlation matrix, all pairs of variables are modeled as having the same correlation, so all non-diagonal elements of the matrix are equal to each other. On the other hand, an autoregressive matrix is often used when variables represent a time series, since correlations are likely to be greater when measurements are closer in time. Other examples include independent, unstructured, M-dependent, and Toeplitz. In exploratory data analysis, the iconography of correlations consists in replacing a correlation matrix by a diagram where the "remarkable" correlations are represented by a solid line (positive correlation), or a dotted line (negative correlation). In some applications (e.g., building data models from only partially observed data) one wants to find the "nearest" correlation matrix to an "approximate" correlation matrix (e.g., a matrix which typically lacks positive semi-definiteness due to the way it has been computed). In 2002, Higham formalized the notion of nearness using the Frobenius norm and provided a method for computing the nearest correlation matrix using the Dykstra's projection algorithm. This sparked interest in the subject, with new theoretical (e.g., computing the nearest correlation matrix with factor structure) and numerical (e.g. usage of Newton's method for computing the nearest correlation matrix) results obtained in the subsequent years. If a pair where La corrélation empirique est une estimation du coefficient de corrélation. Une estimation de la distribution de est donnée par où est la fonction hypergéométrique gaussienne . Cette densité correspond à la fois à une densité a posteriori bayésienne et à une densité de distribution de confiance optimale exacte . Pour les variables continues, plusieurs mesures alternatives de dépendance ont été introduites afin de pallier la limitation de la corrélation de Pearson, qui peut être nulle pour des variables aléatoires dépendantes (voir et les références qui y sont citées pour une vue d'ensemble). Elles partagent toutes la propriété importante qu'une valeur nulle implique l'indépendance. Ceci a conduit certains auteurs à recommander leur utilisation systématique, notamment celle de la corrélation de distance . Une autre mesure alternative est le coefficient de dépendance randomisé ( RDC) . Le RDC est une mesure de dépendance multivariée, basée sur les copules et efficace en termes de calcul ; il est invariant par rapport aux changements d'échelle non linéaires des variables aléatoires. Un inconvénient majeur des mesures alternatives, plus générales, est que, lorsqu'elles sont utilisées pour tester l'association entre deux variables, leur puissance est généralement inférieure à celle de la corrélation de Pearson lorsque les données suivent une distribution normale multivariée . Ceci découle du théorème « No free lunch » . Pour détecter tous les types de relations, ces mesures doivent sacrifier leur puissance pour d'autres relations, notamment dans le cas particulier important d'une relation linéaire à marginales gaussiennes, pour lequel la corrélation de Pearson est optimale. Un autre problème concerne l'interprétation. Alors que la corrélation de Pearson peut être interprétée pour toutes les valeurs, les mesures alternatives ne sont généralement interprétables de manière significative qu'aux valeurs extrêmes Pour deux variables binaires , le rapport de cotes mesure leur dépendance et prend des valeurs non négatives, potentiellement infinies : statistiques apparentées, telles que le Y et le Q de Yule , normalisent ce rapport de cotes dans un intervalle similaire Le modèle logistique généralise le rapport de cotes afin de modéliser les cas où les variables dépendantes sont discrètes et où il peut exister une ou plusieurs variables indépendantes. Le rapport de corrélation , l'information mutuelle basée sur l'entropie , la corrélation totale , la corrélation totale duale et la corrélation polychorique sont tous capables de détecter des dépendances plus générales, tout comme la prise en compte de la copule entre eux, tandis que le coefficient de détermination généralise le coefficient de corrélation à la régression multiple .distributions marginales sont : Coefficients de corrélation de rang
Idées fausses courantes
Corrélation et causalité
corrélations linéaires simples
Propriétés
Non-corrélation et indépendance des processus stochastiques
Sensibilité à la distribution des données
Matrices de corrélation

Nearest valid correlation matrix
Bivariate normal distribution
Autres mesures d'association entre variables aléatoiresloi normale multivariée (voir schéma ci-dessus). Dans le cas des distributions elliptiques, il caractérise les (hyper-)ellipses d'isodensité ; toutefois, il ne caractérise pas entièrement la structure de dépendance (par exemple, les degrés de liberté d'une loi t multivariée déterminent le degré de dépendance des queues de distribution).