protocoles de la suite de protocoles Internet . Il assure la transmission fiable , ordonnée et sans erreur d'un flux d' octets entre des applications exécutées sur des hôtes communiquant via un réseau IP. Il est apparu lors de la première implémentation du réseau , où il complétait le protocole IP (Internet Protocol). C'est pourquoi l'ensemble de la suite est communément appelé TCP/IP .
Les principales applications Internet, telles que le Web , la messagerie électronique, l'administration à distance , le transfert de fichiers et la diffusion multimédia en continu , reposent sur le protocole TCP, qui fait partie de la couche transport du protocole TCP/IP. Le protocole SSL/TLS s'exécute souvent par-dessus TCP. Aujourd'hui, TCP demeure un protocole essentiel pour la plupart des communications Internet, garantissant un transfert de données fiable sur divers réseaux.
Le protocole TCP est orienté connexion , ce qui signifie que l'expéditeur et le destinataire doivent d'abord établir une connexion à partir de paramètres convenus ; ils y parviennent grâce à une procédure d'établissement de liaison en trois étapes . Le serveur doit être à l'écoute (ouverture passive) des demandes de connexion des clients avant qu'une connexion ne soit établie. L'établissement de liaison en trois étapes (ouverture active), la retransmission et la détection d'erreurs contribuent à la fiabilité, mais augmentent la latence . Les applications qui n'exigent pas un service de flux de données fiable peuvent utiliser le protocole UDP (User Datagram Protocol ), qui fournit un service de datagrammes sans connexion privilégiant la rapidité à la fiabilité. Le protocole TCP utilise des mécanismes d'évitement de la congestion du réseau . Cependant, il présente des vulnérabilités, notamment les attaques par déni de service (DoS) , le détournement de connexion , le veto TCP et les attaques par réinitialisation .
Vint Cerf et Bob Kahn ont décrit un protocole d'interconnexion de réseaux permettant le partage de ressources par commutation de paquets entre les nœuds du réseau. Les auteurs avaient collaboré avec Gérard Le Lann pour intégrer des concepts du projet français CYCLADES au nouveau réseau. La spécification du protocole résultant, Yogen Dalal et Carl Sunshine, et publiée en décembre 1974. Elle contient la première utilisation attestée du terme « internet » , abréviation de « interconnexion de réseaux » .de la note d'expérimentation Internet (IEN) décrivent l'évolution du TCP vers la version moderne :- IEN n° 5 Spécification du programme de contrôle de transmission Internet TCP version 2 (mars 1977)
- IEN n° 21 Spécification du programme de contrôle de transmission inter-réseaux TCP version 3 (janvier 1978)
- IEN n° 27 Proposition de format d'en-tête pour TCP version 3.1 (février 1978)
- IEN #40 Protocole de contrôle de transmission, version préliminaire 4 (juin 1978)
- IEN n° 44 : Formats d’en-tête les plus récents (juin 1978)
- IEN n° 55 Spécification du protocole de contrôle de transmission inter-réseaux version 4 (septembre 1978)
- Protocole de contrôle de transmission IEN n° 81, version 4 (février 1979)
- Protocole de contrôle de transmission IEN n° 112 (août 1979)
- IEN #124 PROTOCOLE DE COMMANDE DE TRANSMISSION STANDARD DU DOD (décembre 1979)
Le protocole TCP a été normalisé en janvier 1980 sous la référence RFC 761.
En 2004, Vint Cerf et Bob Kahn ont reçu le prix Turing pour leurs travaux fondamentaux sur TCP/IP.
Fonction réseau
Le protocole TCP (Transmission Control Protocol) assure la communication entre une application et le protocole Internet (IP). Il garantit la connectivité entre hôtes au niveau de la couche transport . Une application n'a pas besoin de connaître les mécanismes de transmission des données via une liaison vers un autre hôte, tels que la fragmentation IP nécessaire pour respecter la limite de transmission du support. Au niveau de la couche transport, TCP gère l'établissement de la connexion et les détails de transmission, et présente une abstraction de la connexion réseau à l'application, généralement via une interface de socket réseau .
Aux niveaux inférieurs de la pile de protocoles, en raison de la congestion du réseau , de l'équilibrage de charge ou d'un comportement imprévisible du réseau, les paquets IP peuvent être perdus , dupliqués ou transmis dans le désordre . Le protocole TCP détecte ces problèmes, demande la retransmission des données perdues, réorganise les données transmises dans le désordre et contribue même à minimiser la congestion du réseau afin de réduire la fréquence des autres problèmes. Si les données ne sont toujours pas transmises, la source est informée de cet échec. Une fois que le récepteur TCP a reconstitué la séquence d'octets initialement transmise, il la transmet à l'application destinataire. Ainsi, TCP masque la complexité du réseau sous-jacent à la communication de l'application.
Le protocole TCP est optimisé pour une livraison précise plutôt que pour une livraison rapide et peut engendrer des délais relativement longs (de l'ordre de la seconde) en cas d'attente de messages reçus dans le désordre ou de retransmission de messages perdus. Par conséquent, il n'est pas particulièrement adapté aux applications temps réel telles que la voix sur IP . Pour de telles applications, des protocoles comme le protocole de transport en temps réel (RTP) fonctionnant sur le protocole de datagrammes utilisateur (UDP) sont généralement recommandés.
Le protocole TCP est un service de transmission de flux d'octets fiable qui garantit que tous les octets reçus seront identiques et dans le même ordre que ceux envoyés. Comme la transmission de paquets sur de nombreux réseaux n'est pas fiable, TCP utilise une technique appelée accusé de réception positif avec retransmission . Cette technique exige que le destinataire réponde par un message d'accusé de réception dès réception des données. L'émetteur conserve une trace de chaque paquet envoyé et gère un délai d'attente à partir de l'heure d'envoi. Si ce délai expire avant la réception de l'accusé de réception, l'émetteur retransmet le paquet. Ce délai est nécessaire en cas de perte ou de corruption d'un paquet.
Alors que le protocole IP gère la livraison effective des données, le protocole TCP assure le suivi des segments – les unités de transmission de données individuelles qui composent un message pour un routage efficace sur le réseau. Par exemple, lorsqu'un fichier HTML est envoyé depuis un serveur web, la couche TCP de ce serveur divise le fichier en segments et les transmet individuellement à la couche Internet de la pile réseau . Le logiciel de la couche Internet encapsule chaque segment TCP dans un paquet IP en ajoutant un en-tête qui inclut (entre autres données) l' adresse IP de destination . Lorsque le programme client sur l'ordinateur de destination reçoit ces paquets, le logiciel TCP de la couche transport réassemble les segments et s'assure de leur ordre correct et de l'absence d'erreurs lors de la transmission du contenu du fichier à l'application destinataire.
structure de segment TCP
Le protocole TCP (Transmission Control Protocol) accepte les données d'un flux de données, les divise en segments et ajoute un en-tête TCP, créant ainsi un segment TCP. Ce segment est ensuite encapsulé dans un datagramme IP (Internet Protocol) et échangé avec les pairs.
Le terme « paquet TCP » apparaît à la fois dans un usage informel et formel, tandis que dans une terminologie plus précise, le segment fait référence à l' unité de données du protocole TCP (PDU), le datagramme à la PDU IP et la trame à la PDU de la couche liaison de données :
Les processus transmettent des données en appelant le protocole TCP et en lui passant des tampons de données comme arguments. Le protocole TCP regroupe les données de ces tampons en segments et appelle le module Internet [par exemple IP] pour transmettre chaque segment au protocole TCP de destination.
Un segment TCP se compose d'un en-tête et d'une section de données . L'en-tête contient 10 champs obligatoires et un champ d'extension optionnel ( Options , octets 20 à 56 du tableau). La section de données, qui suit l'en-tête, contient les données utiles transmises à l'application. La longueur de la section de données n'est pas spécifiée dans l'en-tête ; elle peut être calculée en soustrayant la longueur totale du datagramme IP, spécifiée dans l'en-tête, de la longueur combinée de l'en-tête et de l'en-tête IP.Octuor
- Spécifie la taille de l'en-tête TCP en mots de 32 bits . La taille minimale est de 5 mots et la taille maximale de 15 mots, ce qui correspond à une taille minimale de 20 octets et une taille maximale de 60 octets, permettant jusqu'à 40 octets d'options dans l'en-tête. Ce champ tire son nom du fait qu'il représente également le décalage entre le début du segment TCP et les données proprement dites.
- RFC expérimentale 3540 , ECN-nonce. ECN-nonce n'a jamais été largement utilisé et la RFC a été classée comme historique.
- Un projet de RFC propose une nouvelle utilisation pour ce bit. Ce bit est désormais utilisé pour négocier l'utilisation d' ECN précis .
- de tcpdump , un indicateur activé est indiqué par le caractère entre parenthèses.
- CWR (W) : 1 bit
- L'indicateur de réduction de la fenêtre de congestion (CWR) est activé par l'hôte émetteur pour indiquer qu'il a reçu un segment TCP avec l'indicateur ECE activé et qu'il a répondu dans le mécanisme de contrôle de congestion.
- ECE (E) : 1 bit
- ECN-Echo a un double rôle, selon la valeur du drapeau SYN. Il indique :
- Si l'indicateur SYN est défini (1), le pair TCP est compatible ECN .
- Si l'indicateur SYN est désactivé (0), un paquet dont l'en-tête IP contient l'indicateur de congestion (ECN=11) a été reçu lors d'une transmission normale. Ceci indique à l'émetteur TCP une congestion du réseau (ou une congestion imminente).
- URG (U) : 1 bit
- Indique que le champ pointeur Urgent est significatif.
- ACK (.) : 1 bit
- Indique que le champ d'accusé de réception est significatif. Tous les paquets suivant le paquet SYN initial envoyé par le client doivent avoir cet indicateur activé.
- PSH (P) : 1 bit
- Fonction Push. Demande d'envoyer les données mises en mémoire tampon sur le réseau (c'est-à-dire de les transmettre) à l'extrémité émettrice et à l'application réceptrice à l'extrémité réceptrice.
- RST (R) : 1 bit
- Réinitialiser la connexion
- SYN (S) : 1 bit
- Synchroniser les numéros de séquence. Seul le premier paquet envoyé de chaque extrémité doit avoir cet indicateur activé. La signification de certains autres indicateurs et champs varie en fonction de cet indicateur ; certains ne sont valides que lorsqu’il est activé, et d’autres lorsqu’il est désactivé.
- FIN (F) : 1 bit
- Dernier paquet de l'expéditeur
- § Contrôle de flux et § Mise à l'échelle de la fenêtre .)
- Somme de contrôle : 16 bits
- Le champ de somme de contrôle 16 bits sert à la vérification d'erreurs de l'en-tête TCP, de la charge utile et d'un pseudo-en-tête IP. Ce pseudo-en-tête comprend l' adresse IP source , l' adresse IP de destination , le numéro de protocole TCP (6) et la longueur des en-têtes et de la charge utile TCP (en octets).
- Décalage des données . Le remplissage de l'en-tête TCP est utilisé pour garantir que l'en-tête TCP se termine et que les données commencent sur une limite de 32 bits. Ce remplissage est composé de zéros.
- Les options comportent jusqu'à trois champs : Option-Kind (1 octet), Option-Length (1 octet) et Option-Data (variable). Le champ Option-Kind indique le type d'option et est le seul champ obligatoire. Selon sa valeur, les deux champs suivants peuvent être renseignés. Option-Length indique la longueur totale de l'option, et Option-Data contient les données associées à l'option, le cas échéant. Par exemple, un octet Option-Kind égal à 1 indique qu'il s'agit d'une option sans opération, utilisée uniquement pour le remplissage, et qu'aucun champ Option-Length ou Option-Data ne la suit. Un octet Option-Kind égal à 0 marque la fin des options et ne comporte également qu'un seul octet. Un octet Option-Kind égal à 2 indique l'option « Taille maximale du segment » et est suivi d'un octet Option-Length spécifiant la longueur du champ MSS. Option-Length correspond à la longueur totale du champ d'options donné, incluant les champs Option-Kind et Option-Length. Ainsi, bien que la valeur MSS soit généralement exprimée en deux octets, la longueur de l'option sera de 4. Par exemple, un champ d'option MSS avec une valeur de 0x05B4 est codé comme ( 0x02 0x04 0x05B4 ) dans la section des options TCP.
Type d'option Longueur de l'option Données d'option But Notes 0 MD5 (option 19) initialement conçue pour protéger les sessions BGP . Voir RFC 5925 .la section TCP multipath pour plus de détails. - Les autres valeurs d'option sont historiques, obsolètes, expérimentales, non encore normalisées ou non attribuées. L'attribution des numéros d'option est gérée par l' IANA ( Internet Assigned Numbers Authority ).
Diagramme d'état TCP simplifié Le fonctionnement du protocole TCP se divise en trois phases. L'établissement de la connexion est un processus de négociation en plusieurs étapes qui établit une connexion avant le transfert de données . Une fois le transfert terminé, la fermeture de la connexion libère toutes les ressources allouées.
Une connexion TCP est gérée par un système d'exploitation via une ressource qui représente le point de terminaison local des communications, le socket Internet . Pendant la durée de vie d'une connexion TCP, le point de terminaison local subit une série de changements d'état :
états de socket TCP État Point de terminaison Description ÉCOUTER Serveur En attente d'une demande de connexion provenant d'un point de terminaison TCP distant. SYN-SENT Client En attente d'une demande de connexion correspondante après l'envoi d'une demande de connexion. SYN-REÇU Serveur En attente d'un accusé de réception de la demande de connexion après avoir reçu et envoyé une demande de connexion. ÉTABLI Serveur et client Une connexion ouverte permet de transmettre les données reçues à l'utilisateur. Il s'agit de l'état normal de la phase de transfert de données de la connexion. FIN-ATTENTE-1 Serveur et client En attente d'une demande de fermeture de connexion provenant du TCP distant, ou d'un accusé de réception de la demande de fermeture de connexion précédemment envoyée. FIN-ATTENTE-2 Serveur et client En attente d'une demande de fermeture de connexion provenant du serveur TCP distant. ATTENTE FERMÉ Serveur et client En attente d'une demande de fermeture de connexion de la part de l'utilisateur local. CLÔTURE Serveur et client En attente d'un accusé de réception de la demande de fermeture de connexion de la part du serveur TCP distant. DERNIER ACK Serveur et client En attente d'un accusé de réception de la demande de fermeture de connexion précédemment envoyée au TCP distant (qui inclut un accusé de réception de sa propre demande de fermeture de connexion). TEMPS D'ATTENTE Serveur ou client Attendre suffisamment de temps pour s'assurer que tous les paquets restants sur la connexion ont expiré. FERMÉ Serveur et client Aucun état de connexion. Établissement de la connexion Avant qu'un client tente de se connecter à un serveur, ce dernier doit d'abord se lier à un port et l'ouvrir aux connexions : c'est ce qu'on appelle une ouverture passive. Une fois l'ouverture passive établie, un client peut établir une connexion en initiant une ouverture active via la procédure d'authentification en trois étapes (ou protocole en trois phases).
- SYN : L’ouverture active est effectuée par l’envoi d’un SYN du client au serveur. Le client attribue au segment un numéro de séquence aléatoire x.
- SYN-ACK : En réponse, le serveur envoie un SYN-ACK. Le numéro d’accusé de réception est incrémenté de 1 par rapport au numéro de séquence reçu (x+1), et le numéro de séquence choisi par le serveur pour le paquet est un autre nombre aléatoire, y.
- ACK : Enfin, le client renvoie un accusé de réception (ACK) au serveur. Le numéro de séquence est incrémenté de 1 par rapport à la valeur de l’accusé de réception reçu (x+1), et le numéro d’accusé de réception est incrémenté de 1 par rapport au numéro de séquence reçu (y+1).
Les étapes 1 et 2 permettent d'établir et de confirmer le numéro de séquence pour un sens (client vers serveur). Les étapes 2 et 3 permettent d'établir et de confirmer le numéro de séquence pour l'autre sens (serveur vers client). Une fois ces étapes terminées, le client et le serveur ont reçu les accusés de réception et une communication bidirectionnelle (full-duplex) est établie.
Fin de connexion
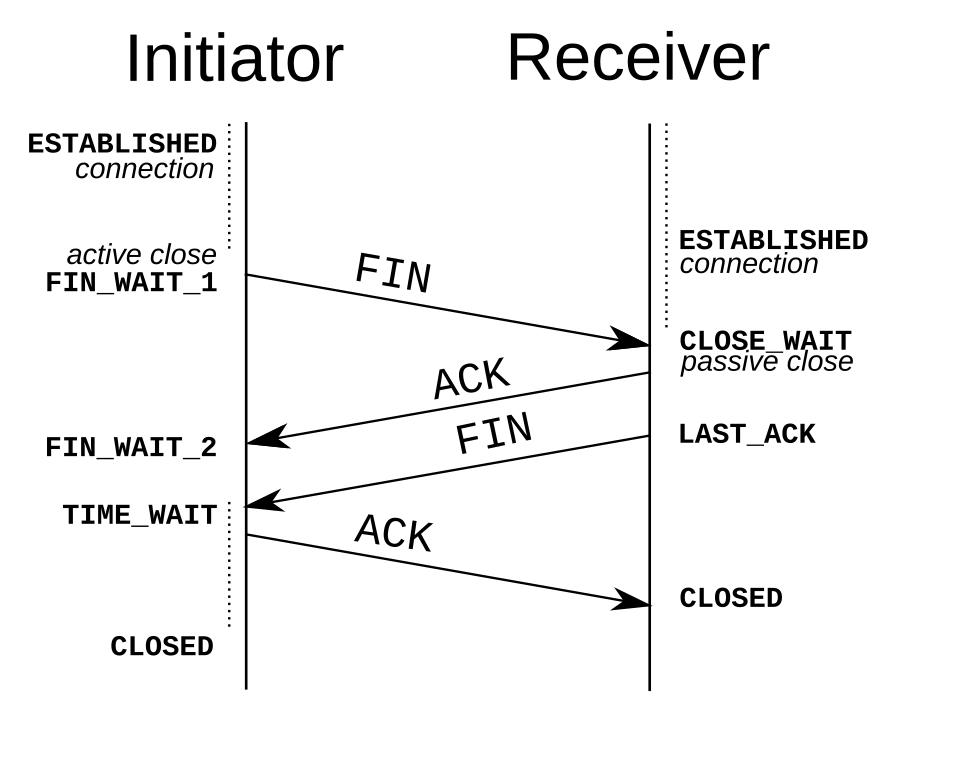
Fin de connexion 
Diagramme de séquence détaillé de la fonction close() de TCP La phase de fermeture de connexion utilise une poignée de main en quatre étapes, chaque extrémité de la connexion se terminant indépendamment. Lorsqu'un point de terminaison souhaite interrompre sa partie de la connexion, il transmet un paquet FIN, auquel l'autre extrémité répond par un ACK. Ainsi, une fermeture classique nécessite une paire de segments FIN et ACK de chaque point de terminaison TCP. Après que l'extrémité ayant envoyé le premier FIN a répondu par l'ACK final, elle attend un délai d'attente avant de fermer définitivement la connexion. Pendant ce délai, le port local est indisponible pour les nouvelles connexions ; cet état permet au client TCP de renvoyer l'accusé de réception final au serveur au cas où l'ACK serait perdu lors de la transmission. La durée de ce délai dépend de l'implémentation, mais des valeurs courantes sont de 30 secondes, 1 minute et 2 minutes. Après l'expiration du délai, le client passe à l'état CLOSED et le port local redevient disponible pour les nouvelles connexions.
Il est également possible de terminer la connexion par une poignée de main en trois étapes, lorsque l'hôte A envoie un FIN et que l'hôte B répond par un FIN & ACK (combinant deux étapes en une) et que l'hôte A répond par un ACK.
Certains systèmes d'exploitation, comme Linux implémentent une séquence de fermeture semi-duplex. Si l'hôte ferme activement une connexion alors qu'il reste des données entrantes non lues, il envoie le signal RST (entraînant la perte des données reçues) au lieu de FIN. Ceci garantit qu'une application TCP est informée de la perte de données .
Une connexion peut être semi -ouverte , auquel cas l'une des parties l'a fermée, mais pas l'autre. La partie qui a fermé la connexion ne peut plus y envoyer de données, contrairement à l'autre. La partie qui a fermé la connexion doit continuer à lire les données jusqu'à ce que l'autre partie la ferme également.
Utilisation des ressources
La plupart des implémentations attribuent une entrée dans une table qui associe une session à un processus système en cours d'exécution. Les paquets TCP ne contenant pas d'identifiant de session, les deux extrémités identifient la session à l'aide de l'adresse IP et du port du client. À chaque réception d'un paquet, l'implémentation TCP doit consulter cette table pour trouver le processus de destination. Chaque entrée de la table est appelée bloc de contrôle de transmission (TCB). Elle contient des informations sur les extrémités (adresse IP et port), l'état de la connexion, les données en cours d'échange des paquets et les tampons d'envoi et de réception des données.
Le nombre de sessions côté serveur est limité uniquement par la mémoire et peut augmenter avec l'arrivée de nouvelles connexions. Cependant, le client doit allouer un port éphémère avant d'envoyer le premier SYN au serveur. Ce port reste alloué pendant toute la durée de la communication et limite ainsi le nombre de connexions sortantes depuis chaque adresse IP du client. Si une application ne ferme pas correctement les connexions inutilisées, le client peut manquer de ressources et devenir incapable d'établir de nouvelles connexions TCP, même depuis d'autres applications.
Les deux points d'extrémité doivent également allouer de l'espace pour les paquets non acquittés et les données reçues (mais non lues).
Transfert de données
Le protocole de contrôle de transmission (TCP) diffère du protocole de datagramme utilisateur (UDP) par plusieurs caractéristiques clés :
- Transfert de données ordonné : l'hôte de destination réorganise les segments selon un numéro de séquence
- Retransmission des paquets perdus : tout flux cumulatif non acquitté est retransmis
- Transfert de données sans erreur : les paquets corrompus sont traités comme perdus et sont retransmis
- Contrôle de flux : limite le débit de transfert des données par l’émetteur afin de garantir une livraison fiable. Le récepteur informe continuellement l’émetteur de la quantité de données pouvant être reçue. Lorsque la mémoire tampon du récepteur est pleine, l’accusé de réception suivant suspend le transfert et permet le traitement des données restantes.
- Contrôle de la congestion : les paquets perdus (présumés dus à la congestion) déclenchent une réduction du taux de livraison des données
Transmission fiable
Le protocole TCP utilise un numéro de séquence pour identifier chaque octet de données. Ce numéro de séquence détermine l'ordre d'envoi des octets depuis chaque ordinateur, permettant ainsi de reconstituer les données dans l'ordre, même en cas de livraison désordonnée . Le numéro de séquence du premier octet est choisi par l'émetteur pour le premier paquet, marqué SYN. Ce numéro peut être arbitraire et doit, de fait, être imprévisible afin de se prémunir contre les attaques par prédiction de séquence TCP .
Les accusés de réception (ACK), accompagnés d'un numéro de séquence, sont envoyés par le destinataire des données pour informer l'expéditeur de la réception des données à l'octet spécifié. Les ACK n'impliquent pas que les données ont été transmises à l'application ; ils signifient simplement qu'il incombe désormais au destinataire de les acheminer.
La fiabilité est assurée par la capacité de l'émetteur à détecter les données perdues et à les retransmettre. Le protocole TCP utilise deux techniques principales pour identifier les pertes : le délai d'expiration de la retransmission (RTO) et les accusés de réception cumulatifs dupliqués (DupAcks).
Lorsqu'un segment TCP est retransmis, il conserve le même numéro de séquence que la tentative de livraison initiale. Cette confusion entre l'ordre de livraison et l'ordre logique des données implique que, lors de la réception d'un accusé de réception après une retransmission, l'émetteur ne peut déterminer s'il s'agit de la transmission initiale ou de la retransmission : c'est ce qu'on appelle l' ambiguïté de retransmission . Le protocole TCP présente une complexité accrue due à cette ambiguïté
retransmission basée sur les accusés de réception dupliqués
Si un segment (par exemple, le segment numéro 100) d'un flux est perdu, le récepteur ne peut pas accuser réception des paquets suivants, car il utilise des accusés de réception cumulatifs. Par conséquent, le récepteur accuse réception du paquet 99 une nouvelle fois lors de la réception d'un autre paquet de données. Cet accusé de réception en double sert de signal de perte de paquet. Ainsi, si l'émetteur reçoit trois accusés de réception en double, il retransmet le dernier paquet non acquitté. Un seuil de trois est utilisé car le réseau peut réordonner les segments, ce qui entraîne des accusés de réception en double. Il a été démontré que ce seuil permet d'éviter les retransmissions intempestives dues à un réordonnancement. Certaines implémentations TCP utilisent des accusés de réception sélectifs (SACK) pour fournir un retour d'information explicite sur les segments reçus. Cela améliore considérablement la capacité de TCP à retransmettre les segments appropriés.
L'ambiguïté de retransmission peut entraîner des retransmissions rapides intempestives et une tentative d'évitement de la congestion en cas de réordonnancement dépassant le seuil d'accusé de réception dupliqué [44]. deux dernières décennies, une augmentation du réordonnancement des paquets a été observée sur Internet , ce qui a conduit les implémentations TCP, comme celle du noyau Linux, à adopter des méthodes heuristiques pour ajuster ce seuil . Récemment, des efforts ont été déployés pour supprimer progressivement les retransmissions rapides basées sur les accusés de réception dupliqués et les remplacer par des retransmissions basées sur un temporisateur (à ne pas confondre avec le RTO classique, abordé ci-dessous). L'algorithme de détection de perte temporel appelé Recent Acknowledgment (RACK) a été adopté comme algorithme par défaut sous Linux et Windows
Retransmission basée sur le délai d'expiration
Lorsqu'un émetteur transmet un segment, il initialise un minuteur avec une estimation prudente de l'heure d'arrivée de l'accusé de réception. Le segment est retransmis si le minuteur expire, avec un nouveau seuil de délai d'attente égal au double de la valeur précédente, ce qui induit un comportement de temporisation exponentielle . Généralement, la valeur initiale du minuteur est les attaques par déni de service de type « homme du milieu » .
L'estimation précise du RTT est essentielle pour la récupération des paquets perdus, car elle permet à l'émetteur de considérer un paquet non acquitté comme perdu après un délai suffisant (c'est-à-dire en déterminant le délai RTO). L'ambiguïté de retransmission peut rendre l'estimation du RTT par l'émetteur imprécise. Dans un environnement où les RTT sont variables, des délais d'attente parasites peuvent survenir : si le RTT est sous-estimé, le RTO se déclenche, entraînant une retransmission inutile et un redémarrage lent. Après une retransmission parasite, à la réception des accusés de réception des transmissions initiales, l'émetteur peut les interpréter comme confirmant la retransmission et conclure, à tort, que des segments envoyés entre la transmission initiale et la retransmission ont été perdus, provoquant ainsi d'autres retransmissions inutiles et une congestion réelle de la liaison ; l'accusé de réception sélectif permet d'atténuer cet effet. L'algorithme de Karn garantit une bonne estimation du RTT — à terme — en attendant un accusé de réception non ambigu avant d'ajuster le RTO. Cependant, après des retransmissions intempestives, l'obtention d'un tel accusé de réception peut prendre un temps considérable, dégradant ainsi les performances pendant cette période. Les horodatages TCP résolvent également le problème d'ambiguïté des retransmissions lors de la définition du RTO, bien qu'ils n'améliorent pas nécessairement l'estimation du RTT.
Détection d'erreurs
Les numéros de séquence permettent aux récepteurs d'éliminer les paquets en double et de remettre correctement dans l'ordre les paquets reçus dans le désordre. Les accusés de réception permettent aux expéditeurs de déterminer quand retransmettre les paquets perdus.
Pour garantir l'exactitude des données, un champ de somme de contrôle est inclus ; voir CRC au niveau 2 , en dessous des protocoles TCP et IP, comme c'est le cas pour le protocole PPP ou la trame Ethernet . Cependant, l'introduction d'erreurs dans les paquets entre les sauts protégés par CRC est fréquente et la somme de contrôle TCP de 16 bits permet de détecter la plupart d'entre elles.
Contrôle du débit
Le protocole TCP utilise un mécanisme de contrôle de flux de bout en bout afin d'éviter que l'émetteur n'envoie des données trop rapidement pour que le récepteur TCP puisse les recevoir et les traiter correctement. Ce mécanisme de contrôle de flux est essentiel dans un environnement où communiquent des machines aux vitesses de réseau différentes. Par exemple, si un PC envoie des données à un smartphone qui traite lentement les données reçues, ce dernier doit pouvoir réguler le flux de données pour éviter d'être surchargé.
Le protocole TCP utilise un système de contrôle de flux à fenêtre glissante . Dans chaque segment TCP, le récepteur spécifie, dans le champ de fenêtre de réception, la quantité de données supplémentaires (en octets) qu'il est prêt à mettre en mémoire tampon pour la connexion. L'hôte émetteur ne peut envoyer que cette quantité de données avant de devoir attendre un accusé de réception et une mise à jour de la fenêtre de réception de l'hôte récepteur.
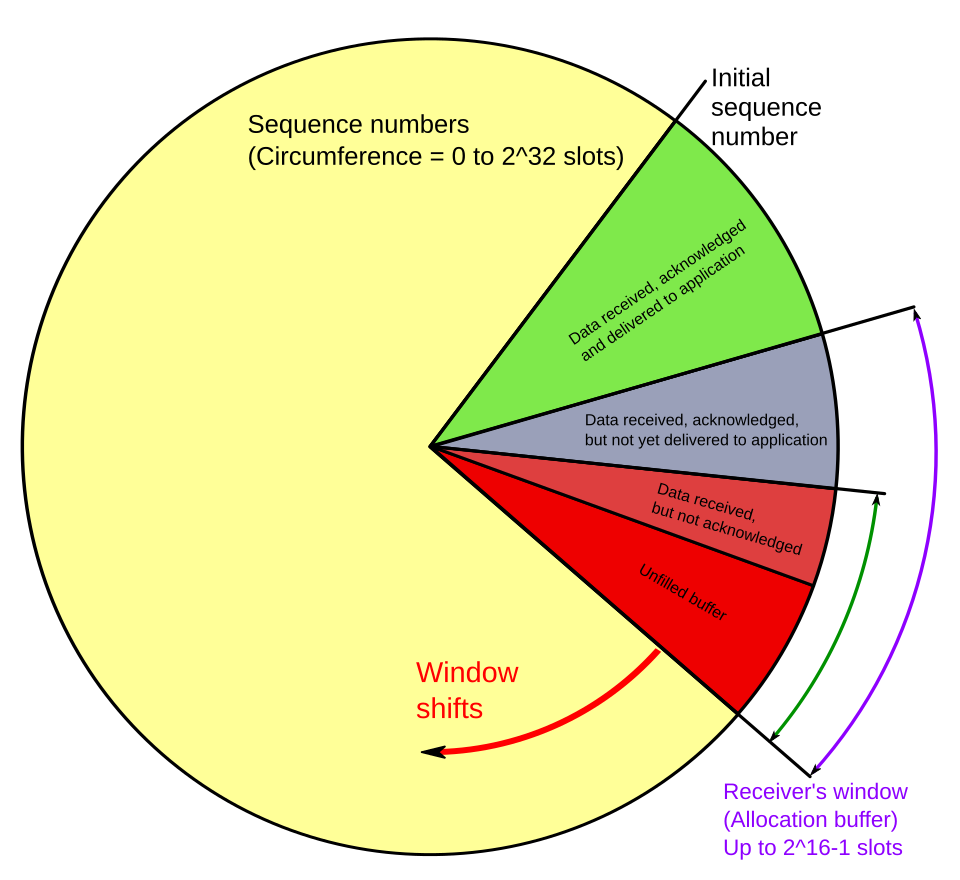
Les numéros de séquence TCP et les fenêtres de réception fonctionnent comme une horloge. La fenêtre de réception se décale à chaque réception et accusé de réception d'un nouveau segment de données. Une fois les numéros de séquence épuisés, la numérotation revient à 0. Lorsqu'un récepteur annonce une taille de fenêtre de 0, l'émetteur cesse d'envoyer des données et active son temporisateur de persistance . Ce temporisateur protège le protocole TCP d'un blocage pouvant survenir en cas de perte d'une mise à jour ultérieure de la taille de fenêtre par le récepteur. L'émetteur ne peut alors plus envoyer de données tant qu'il n'a pas reçu une nouvelle mise à jour. À l'expiration du temporisateur, l'émetteur TCP tente de rétablir le protocole en envoyant un petit paquet afin que le récepteur réponde par un nouvel accusé de réception contenant la nouvelle taille de fenêtre.
Si un récepteur traite les données entrantes par petits incréments, il peut annoncer de manière répétée une petite fenêtre de réception. C'est ce qu'on appelle le syndrome de la fenêtre inutile , car il est inefficace d'envoyer seulement quelques octets de données dans un segment TCP, compte tenu de la surcharge relativement importante de l'en-tête TCP.
le contrôle de la congestion . TCP utilise plusieurs mécanismes pour garantir des performances élevées et éviter la saturation du réseau , une situation de blocage où les performances sont fortement dégradées. Ces mécanismes contrôlent le débit de données entrant dans le réseau, en le maintenant en dessous d'un seuil susceptible de provoquer une saturation. Ils permettent également une répartition équitable des flux, selon un principe de maximum-minimum .Contrôle de la congestion
Les accusés de réception des données envoyées, ou leur absence, permettent aux émetteurs de déduire l'état du réseau entre l'émetteur et le récepteur TCP. Associés à des temporisateurs, ces mécanismes permettent aux émetteurs et récepteurs TCP de moduler le flux de données. On parle alors de contrôle ou d'évitement de la congestion.
Les implémentations modernes de TCP contiennent quatre algorithmes imbriqués : le démarrage lent , l'évitement de la congestion , la retransmission rapide et la récupération rapide .
De plus, les émetteurs utilisent un délai de retransmission (RTO) basé sur le temps d'aller-retour (RTT) estimé entre l'émetteur et le récepteur, ainsi que sur la variance de ce temps d'aller-retour . L'estimation du RTT présente des subtilités. Par exemple, les émetteurs doivent être précis lors du calcul des échantillons de RTT pour les paquets retransmis ; ils utilisent généralement l'algorithme de Karn ou les horodatages TCP . Ces échantillons de RTT individuels sont ensuite moyennés dans le temps pour créer un temps d'aller-retour lissé (SRTT) à l'aide de d'algorithmes d'évitement de la congestion pour TCP .
Taille maximale du segment
La taille maximale de segment (MSS) correspond à la quantité maximale de données, exprimée en octets, que TCP accepte de recevoir dans un seul segment. Pour des performances optimales, la MSS doit être suffisamment petite afin d'éviter la fragmentation IP , qui peut entraîner des pertes de paquets et un nombre excessif de retransmissions. Généralement, la MSS est annoncée par chaque extrémité à l'aide de l'option `MSS` lors de l'établissement de la connexion TCP. La valeur de cette option est calculée à partir de la taille maximale de l'unité de transmission (MTU) de la couche liaison de données des réseaux auxquels l'émetteur et le récepteur sont directement connectés. Les émetteurs TCP peuvent utiliser la découverte de la MTU du chemin pour déduire la MTU minimale sur le chemin réseau entre l'émetteur et le récepteur, et ainsi ajuster dynamiquement la MSS afin d'éviter la fragmentation IP au sein du réseau.
L'annonce du MSS peut également être appelée négociation du MSS , mais à proprement parler, le MSS n'est pas négocié . Deux valeurs de MSS totalement indépendantes sont autorisées pour les deux sens de flux de données dans une connexion TCP , il n'est donc pas nécessaire de convenir d'une configuration de MSS commune pour une connexion bidirectionnelle.
le protocole SCTP (Stream Control Transmission Protocol ).Remerciements sélectifs
Les accusés de réception sélectifs peuvent être « retirés », c’est-à-dire que le destinataire peut unilatéralement ignorer les données acquittées de manière sélective. option d'échelle de la fenêtre TCP , définie dans l'optimisation du protocole TCP .
L'option d'échelle de fenêtre est utilisée uniquement lors de l'établissement de la liaison TCP en trois étapes. Sa valeur représente le nombre de bits à décaler vers la gauche du champ de taille de fenêtre de 16 bits lors de son interprétation. Cette valeur peut être définie indépendamment de 0 (aucun décalage) à 14 pour chaque direction. Les deux extrémités doivent envoyer cette option dans leurs segments SYN pour activer l'échelle de fenêtre dans les deux sens.
Certains routeurs et pare-feu de paquets modifient le facteur d'échelle de la fenêtre TCP pendant une transmission. Cela entraîne des différences de taille de fenêtre TCP entre l'émetteur et le récepteur. Il en résulte un trafic instable, potentiellement très lent. Ce problème est visible sur certains sites situés derrière un routeur défectueux.
Horodatage TCP
Les horodatages TCP, définis dans Windows Server 2008 , 2012 et 2016.
Des statistiques récentes montrent que le niveau d'adoption de l'horodatage TCP a stagné, à environ 40 %, en raison de l'abandon de la prise en charge par Windows Server depuis Windows Server 2008.
Données hors bande
Il est possible d'interrompre ou d'annuler le flux en file d'attente au lieu d'attendre sa fin. Pour ce faire, il faut spécifier que les données sont urgentes . Cela marque la transmission comme étant des données hors bande (OOB) et indique au programme récepteur de les traiter immédiatement. Une fois le traitement terminé, TCP en informe l'application et reprend le traitement du flux en file d'attente. Par exemple, lors d'une session de connexion à distance, TCP peut envoyer une séquence de touches qui interrompt ou annule le programme distant sans attendre la fin de son transfert en cours.
Le pointeur urgent modifie uniquement le traitement sur l'hôte distant et n'accélère aucun traitement sur le réseau lui-même. Cette fonctionnalité est implémentée différemment ou de manière imparfaite selon les systèmes, voire n'est pas prise en charge. Lorsqu'elle est disponible, il est prudent de considérer que seuls les octets de données hors bande (OOB) seront traités de manière fiable. Étant donné que cette fonctionnalité est peu utilisée, elle n'est pas suffisamment testée sur certaines plateformes et a été associée à des vulnérabilités , comme WinNuke par exemple.
Obligation de livraison de données
Normalement, TCP attend 200 ms pour qu'un paquet de données complet soit envoyé ( l'algorithme de Nagle regroupe les petits messages en un seul paquet). Cette attente engendre des délais courts, mais potentiellement importants s'ils se répètent constamment lors d'un transfert de fichier. Par exemple, un bloc d'envoi typique fait 4 Ko et une MSS typique est de 1460. Sur un réseau Ethernet 10 Mbit/s, deux paquets sont envoyés en environ 1,2 ms chacun, suivis d'un troisième paquet contenant les 1176 octets restants après une pause de 197 ms, le temps que TCP remplisse sa mémoire tampon. Dans le cas de Telnet, chaque frappe au clavier est renvoyée par le serveur avant même que l'utilisateur puisse la voir à l'écran. Ce délai deviendrait alors très gênant.
L'activation de l' option de socket
TCP_NODELAYmodifie le délai d'envoi par défaut de 200 ms. Les applications utilisent cette option pour forcer l'envoi des données après l'écriture d'un caractère ou d'une ligne de caractères.La l'espace utilisateur à l'aide des sockets Berkeley ; il est contrôlé uniquement par la pile de protocoles .
vulnérabilités
Le protocole TCP peut être attaqué de diverses manières. Les résultats d'une évaluation de sécurité approfondie du protocole TCP, ainsi que les mesures d'atténuation possibles pour les problèmes identifiés, ont été publiés en 2009 et ont fait l'objet de recherches au sein de l' IETF jusqu'en 2012 Parmi les vulnérabilités notables figurent le déni de service, le détournement de connexion, le veto TCP et l'attaque par réinitialisation TCP .
Refus de service
En utilisant une adresse IP usurpée et en envoyant de manière répétée des paquets SYN spécialement conçus , suivis de nombreux paquets ACK, les attaquants peuvent saturer les ressources du serveur, qui doit gérer ces connexions frauduleuses. Il s'agit d'une attaque par inondation SYN . Parmi les solutions proposées, on trouve les cookies SYN et les énigmes cryptographiques, bien que les cookies SYN présentent leurs propres vulnérabilités. Sockstress est une attaque similaire, qui peut être atténuée par une gestion optimisée des ressources système . Une attaque par déni de service (DoS) avancée, exploitant la persistance du protocole TCP, a été analysée dans Phrack n° 66. Les inondations PUSH et ACK constituent d'autres variantes.
l'usurpation d'ARP ou à d'autres attaques de routage permettant à un attaquant de prendre le contrôle permanent de la connexion TCP.Détournement de connexion
une attaque par déni de service . C'est pourquoi le numéro de séquence initial est désormais choisi aléatoirement.
Veto TCP
Un attaquant capable d'intercepter et de prédire la taille du prochain paquet à envoyer peut amener le destinataire à accepter une charge utile malveillante sans interrompre la connexion existante. L'attaquant injecte un paquet malveillant dont le numéro de séquence et la taille correspondent à ceux du prochain paquet attendu. Lorsque le paquet légitime est finalement reçu, il s'avère qu'il possède le même numéro de séquence et la même longueur qu'un paquet déjà reçu et il est silencieusement rejeté comme un paquet dupliqué normal : le paquet légitime est bloqué par le paquet malveillant. Contrairement au détournement de connexion, la connexion n'est jamais désynchronisée et la communication se poursuit normalement après l'acceptation de la charge utile malveillante. Le mécanisme de veto TCP offre moins de contrôle à l'attaquant sur la communication, mais rend l'attaque particulièrement difficile à détecter. Le seul indice pour le destinataire qu'un problème survient est un unique paquet dupliqué, un phénomène courant sur un réseau IP. L'expéditeur du paquet bloqué ne constate jamais aucune trace de l'attaque.
: adresse source, port source , adresse de destination et port de destination. Les numéros de port servent à identifier différents services et à autoriser plusieurs connexions entre hôtes. TCP utilise des numéros de port sur 16 bits , offrant 65 536 valeurs possibles pour chaque port source et de destination. La dépendance de l’identité de la connexion aux adresses implique que les connexions TCP sont liées à un seul chemin réseau ; TCP ne peut pas utiliser d’autres routes disponibles pour les hôtes multihébergés , et les connexions sont interrompues si l’adresse d’un point de terminaison change.ports TCP
Les numéros de port sont classés en trois catégories principales : ports connus, ports enregistrés et ports dynamiques ou privés. Les ports connus sont attribués par l’ IANA ( Internet Assigned Numbers Authority ) et sont généralement utilisés par les processus système. Les applications connues fonctionnant comme serveurs et écoutant passivement les connexions utilisent généralement ces ports. Citons par exemple : FTP (20 et 21), SSH (22), ( 23), SMTP (25), HTTP sur SSL/TLS 443) et HTTP (80). Les ports enregistrés (1024 à 49151) peuvent être attribués à des services spécifiques par des développeurs tiers, mais certains systèmes exploitation allouent également des ports clients éphémères dans cette plage. Les ports dynamiques ou privés (49152 à 65535) ne sont associés à aucun service enregistré et sont généralement utilisés exclusivement comme ports éphémères pour les connexions client temporaires.
La traduction d'adresses réseau (NAT) utilise généralement des numéros de port dynamiques, côté public, pour lever l'ambiguïté du flux de trafic qui transite entre un réseau public et un sous-réseau privé , permettant ainsi à de nombreuses adresses IP (et leurs ports) sur le sous-réseau d'être desservies par une seule adresse publique.
Développement
Le protocole TCP est complexe. Bien que des améliorations significatives aient été apportées et proposées au fil des ans, son fonctionnement de base n'a pas fondamentalement changé depuis sa première spécification la notification explicite de congestion (ECN), un mécanisme de signalisation permettant d'éviter la congestion.
L'algorithme original d'évitement de la congestion TCP était connu sous le nom de TCP Tahoe , mais de nombreux algorithmes alternatifs ont été proposés depuis (notamment TCP Reno , TCP Vegas , FAST TCP , TCP New Reno et TCP Hybla ).
Le protocole TCP multipath (MPTCP) est un projet en cours au sein de l'IETF visant à permettre à une connexion TCP d'utiliser plusieurs chemins afin d'optimiser l'utilisation des ressources et d'accroître la redondance. La redondance offerte par le MPTCP dans le contexte des réseaux sans fil permet l'utilisation simultanée de différents réseaux, ce qui améliore le débit et les capacités de transfert intercellulaire. Le MPTCP offre également des gains de performance dans les environnements de centres de données . L' implémentation de référence du MPTCP a été développée dans le noyau Linux . Le MPTCP est utilisé pour prendre en charge l'application de reconnaissance vocale Siri sur iPhone, iPad et Mac
tcpcrypt est une extension proposée en juillet 2010 pour fournir un chiffrement au niveau transport directement dans TCP. Elle est conçue pour fonctionner de manière transparente et ne nécessite aucune configuration. Contrairement à TLS (SSL), tcpcrypt ne fournit pas d'authentification, mais propose des primitives simples permettant à l'application de s'en charger. La RFC de tcpcrypt a été publiée par l'IETF en mai 2019.
TCP Fast Open est une extension permettant d'accélérer l'ouverture de connexions TCP successives entre deux points de terminaison. Elle fonctionne en sautant la poignée de main en trois étapes grâce à un cookie cryptographique . Elle est similaire à une proposition antérieure appelée T/TCP , qui n'a pas été largement adoptée en raison de problèmes de sécurité. TCP Fast Open a été publié sous la référence de démarrage lent . Cet algorithme est conçu pour améliorer la vitesse de récupération et constitue l'algorithme de contrôle de congestion par défaut dans les noyaux Linux 3.2 et versions ultérieures.
Propositions obsolètes
Les transactions par cookies TCP (TCPCT) constituent une extension proposée en décembre 2009 pour sécuriser les serveurs contre les attaques par déni de service (DoS). Contrairement aux cookies SYN, TCPCT n'entre pas en conflit avec d'autres extensions TCP telles que le redimensionnement de la fenêtre . TCPCT a été conçu pour répondre aux exigences de DNSSEC , les serveurs devant gérer un grand nombre de connexions TCP éphémères. En 2016, TCPCT a été déprécié au profit de TCP Fast Open. Le statut de la RFC originale a été modifié en « historique » .
Implémentations matérielles
Pour pallier les besoins en puissance de calcul du protocole TCP, une solution consiste à développer des implémentations matérielles, communément appelées moteurs de déchargement TCP (TOE). Le principal inconvénient des TOE réside dans leur intégration complexe aux systèmes informatiques, qui nécessite des modifications importantes du système d'exploitation de l'ordinateur ou du périphérique.
Il a été démontré que TCP low power ( TCPLP ) fonctionne dans des environnements aux ressources limitées où le protocole CoAP basé sur UDP est généralement préféré.
Image filaire et ossification
Les données transmises via TCP offrent d'importantes possibilités de collecte et de modification d'informations aux observateurs situés sur le chemin, car les métadonnées du protocole sont transmises en clair . Bien que cette transparence soit utile aux opérateurs de réseau et aux chercheurs, les informations collectées à partir des métadonnées du protocole peuvent réduire la confidentialité de l'utilisateur final. Cette visibilité et cette malléabilité des métadonnées ont rendu le protocole TCP difficile à étendre – un cas d' ossification du protocole – car tout nœud intermédiaire (un « middlebox ») peut prendre des décisions basées sur ces métadonnées, voire les modifier, enfreignant ainsi le principe de bout en bout . Une étude a révélé qu'un tiers des chemins sur Internet rencontrent au moins un intermédiaire qui modifie les métadonnées TCP, et que 6,5 % des chemins subissent les effets néfastes de cette ossification. La nécessité d'éviter les risques d'extensibilité liés aux intermédiaires a imposé des contraintes importantes à la conception de MPTCP , et les difficultés causées par les intermédiaires ont freiné le déploiement de TCP Fast Open dans les navigateurs web . Une autre source de rigidité est la difficulté de modifier les fonctions TCP aux points de terminaison, généralement dans le noyau du système d'exploitation ou dans le matériel doté d'un moteur de déchargement TCP .
Performance
Le protocole TCP, en fournissant aux applications l'abstraction d'un flux d'octets fiable , peut souffrir du blocage en tête de file : si des paquets sont réordonnés ou perdus et doivent être retransmis (et sont donc réordonnés), les données des parties séquentiellement ultérieures du flux peuvent être reçues avant celles des parties séquentiellement antérieures. Or, ces données ultérieures ne peuvent généralement pas être utilisées tant que les données antérieures n'ont pas été reçues, ce qui engendre une latence réseau . Si plusieurs messages indépendants de niveau supérieur sont encapsulés et multiplexés sur une seule connexion TCP, le blocage en tête de file peut entraîner l'attente de la réception d'un message envoyé plus tôt pour le traitement d'un message entièrement reçu mais envoyé ultérieurement. Les navigateurs Web tentent d'atténuer ce blocage en ouvrant plusieurs connexions parallèles. Cela engendre le coût de l'établissement répété des connexions et multiplie les ressources nécessaires au suivi de ces connexions aux points de terminaison. Les connexions parallèles disposent également d'un contrôle de congestion fonctionnant indépendamment les unes des autres, au lieu de pouvoir mettre en commun les informations et réagir plus rapidement aux conditions du réseau observées ; Les schémas d'envoi initiaux agressifs de TCP peuvent provoquer une congestion si plusieurs connexions parallèles sont ouvertes ; et le modèle d'équité par connexion conduit à une monopolisation des ressources par les applications qui adoptent cette approche.
L'établissement de la connexion contribue fortement à la latence perçue par les utilisateurs web. La poignée de main TCP en trois étapes introduit une latence d'un RTT lors de l'établissement de la connexion avant que les données puissent être envoyées. Pour les flux courts, ces délais sont très importants. Le protocole TLS ( Transport Layer Security ) nécessite sa propre poignée de main pour l'échange de clés lors de l'établissement de la connexion. Du fait de son architecture en couches, les poignées de main TCP et TLS se déroulent séquentiellement ; la poignée de main TLS ne peut commencer qu'une fois la poignée de main TCP terminée. Deux RTT sont nécessaires pour l'établissement d'une connexion avec TLS 1.2 sur TCP. TLS 1.3 permet une reprise de connexion sans RTT dans certaines circonstances, mais, lorsqu'il est implémenté sur TCP, un RTT reste nécessaire pour la poignée de main TCP, et celui-ci ne peut pas faciliter l'établissement de la connexion initiale. Les échanges de clés sans RTT présentent également des défis cryptographiques, car l'échange de clés non interactif efficace, sûr contre la relecture et sécurisé en transmission est un sujet de recherche ouvert. TCP Fast Open permet la transmission de données dans les paquets initiaux (c.-à-d. SYN et SYN-ACK), supprimant ainsi un RTT de latence lors de l'établissement de la connexion. Cependant, le déploiement de TCP Fast Open s'est avéré difficile en raison de la rigidification du protocole ; navigateur Web ne l'utilisait par défaut.
Le débit TCP est affecté par le réordonnancement des paquets . Les paquets réordonnés peuvent entraîner l'envoi d'accusés de réception dupliqués qui, s'ils dépassent un certain seuil, déclenchent une retransmission intempestive et un contrôle de congestion. Le comportement de transmission peut également devenir irrégulier, car de larges plages de paquets sont acquittées simultanément lors de la réception d'un paquet réordonné au début de la plage (de manière similaire à l'impact du blocage en tête de file sur les applications). la congestion du réseau et où la taille de la fenêtre de congestion est fortement réduite par précaution. Cependant, les liaisons sans fil sont sujettes à des pertes sporadiques et généralement temporaires dues à l'affaiblissement du signal , aux masquages, aux transferts intercellulaires, aux interférences et à d'autres phénomènes radio qui ne relèvent pas strictement de la congestion. Après la réduction (erronée) de la taille de la fenêtre de congestion, due à la perte de paquets, une phase d'évitement de la congestion peut survenir, caractérisée par une diminution prudente de cette taille. Ceci entraîne une sous-utilisation de la liaison radio. De nombreuses recherches ont été menées pour lutter contre ces effets néfastes. Les solutions proposées peuvent être classées en trois catégories : les solutions de bout en bout, qui nécessitent des modifications côté client ou serveur ; les solutions de couche liaison, telles que le protocole RLP (Radio Link Protocol) dans les réseaux cellulaires ; et les solutions basées sur un proxy, qui requièrent des modifications du réseau sans intervention sur les nœuds terminaux. Un certain nombre d'algorithmes alternatifs de contrôle de la congestion, tels que Vegas , Westwood , Veno et Santa Cruz, ont été proposés pour aider à résoudre le problème sans fil.processeur réseau , puis de relayer les données vers une seconde connexion destinée au système final. Les paquets de données provenant de l'émetteur sont mis en mémoire tampon au niveau du nœud accélérateur, qui effectue des retransmissions locales en cas de perte de paquets. Ainsi, en cas de pertes, la boucle de rétroaction entre l'émetteur et le récepteur est raccourcie à celle entre le nœud accélérateur et le récepteur, ce qui garantit une livraison plus rapide des données à ce dernier.
Le protocole TCP étant adaptatif, le débit d'injection des paquets par l'émetteur est directement proportionnel à la charge du réseau et à la capacité de traitement du récepteur. L'émetteur évalue la charge du réseau à partir des accusés de réception qu'il reçoit. Le nœud d'accélération répartit la boucle de rétroaction entre l'émetteur et le récepteur, garantissant ainsi un temps d'aller-retour (RTT) plus court par paquet. Un RTT plus court est avantageux car il assure une réponse plus rapide aux variations du réseau et une adaptation plus rapide de l'émetteur face à ces variations.
Cette méthode présente l'inconvénient d'obliger la session TCP à transiter par l'accélérateur ; par conséquent, si le routage change et que l'accélérateur n'est plus sur le chemin, la connexion sera interrompue. De plus, elle compromet la continuité de bout en bout du mécanisme d'accusé de réception TCP (ACK) : lorsque l'accusé de réception est reçu par l'expéditeur, le paquet a déjà été stocké par l'accélérateur et n'a pas encore été transmis au destinataire.
Débogage
Un analyseur de paquets , qui intercepte le trafic TCP sur une liaison réseau, peut s'avérer utile pour déboguer les réseaux, les piles réseau et les applications utilisant TCP, en permettant à un ingénieur de visualiser les paquets transitant par cette liaison. Certaines piles réseau prennent en charge l'option de socket SO_DEBUG, activable via la commande setsockopt. Cette option affiche tous les paquets, états TCP et événements présents sur ce socket, ce qui facilite le débogage. Netstat est un autre utilitaire utilisable pour le débogage.
Alternatives
Pour de nombreuses applications, le protocole TCP n'est pas adapté. En effet, l'application ne peut généralement pas accéder aux paquets suivant un paquet perdu tant que la copie retransmise de ce dernier n'est pas reçue. Ceci pose problème pour les applications temps réel telles que la diffusion multimédia en continu, les jeux multijoueurs en temps réel et la voix sur IP (VoIP), où il est généralement plus utile de recevoir la majeure partie des données rapidement que de les recevoir toutes dans l'ordre.
Pour des raisons historiques et de performance, la plupart des réseaux de stockage (SAN) utilisent le protocole Fibre Channel (FCP) sur des connexions Fibre Channel . Pour les systèmes embarqués , le démarrage réseau et les serveurs traitant des requêtes simples provenant d'un grand nombre de clients (par exemple, les serveurs DNS ), la complexité du protocole TCP peut s'avérer problématique. Des opérations telles que la transmission de données entre deux hôtes situés derrière un NAT (via STUN ou un système similaire) sont bien plus simples sans avoir recours à un protocole relativement complexe comme TCP.
En général, lorsque le protocole TCP est inadapté, on utilise le protocole UDP (User Datagram Protocol ). Ce dernier offre les mêmes fonctionnalités de multiplexage et de calcul de sommes de contrôle que TCP, mais ne gère ni les flux ni la retransmission, ce qui permet au développeur d'applications de les implémenter de manière adaptée à la situation, ou de les remplacer par d'autres méthodes telles que la correction d'erreurs sans voie de retour ou la dissimulation d'erreurs .
Le protocole SCTP (Stream Control Transmission Protocol ) est un autre protocole offrant des services de transmission de flux fiables, similaires à TCP. Plus récent et considérablement plus complexe que TCP, il n'est pas encore largement déployé. Il est cependant spécialement conçu pour les situations exigeant une fiabilité et une quasi-temps réel.
Le protocole de transport Venturi (VTP) est un protocole propriétaire breveté conçu pour remplacer le protocole TCP de manière transparente et pallier les inefficacités perçues liées au transport de données sans fil. En particulier dans les communications mobiles et les réseaux sans fil, la transmission de données peut devenir instable en raison d'une latence élevée et d'interférences de signal.
L' algorithme d'évitement de congestion du protocole TCP est particulièrement efficace dans les environnements ad hoc où l'expéditeur des données est inconnu à l'avance. Dans un environnement prévisible, un protocole basé sur la synchronisation, tel que le mode de transfert asynchrone (ATM), permet d'éviter la surcharge liée aux retransmissions du protocole TCP.
Le protocole de transfert de données UDP (UDT) est conçu pour les environnements réseau à large bande passante et à latence élevée, notamment pour les transferts de données à grande échelle tels que le transfert de fichiers ou la diffusion multimédia. Dans les réseaux présentant un produit bande passante-délai élevé , l'UDT offre des avantages par rapport au TCP, garantissant une meilleure efficacité et une plus grande équité.
Le protocole de transaction multi-usage (MTP/IP) est un logiciel propriétaire breveté conçu pour atteindre de manière adaptative un débit et des performances de transaction élevés dans une grande variété de conditions de réseau, en particulier celles où TCP est perçu comme inefficace.
IPv4 , la méthode utilisée pour calculer la somme de contrôle est définie comme suit :Calcul de la somme de contrôle
Le champ de somme de contrôle correspond au complément à un (sur 16 bits) de la somme des compléments à un de tous les mots de 16 bits de l'en-tête et du texte. Le calcul de la somme de contrôle doit garantir l'alignement sur 16 bits des données additionnées. Si un segment contient un nombre impair d'octets d'en-tête et de texte, l'alignement peut être obtenu en complétant le dernier octet par des zéros à sa droite afin de former un mot de 16 bits pour le calcul de la somme de contrôle. Ce remplissage n'est pas transmis avec le segment. Lors du calcul de la somme de contrôle, le champ correspondant est lui-même remplacé par des zéros.
Autrement dit, après un remplissage approprié, tous les mots de 16 bits sont additionnés en utilisant l'arithmétique du complément à un . La somme est ensuite complémentée bit à bit et insérée comme champ de somme de contrôle. Un pseudo-en-tête imitant l'en-tête de paquet IPv4 utilisé dans le calcul de la somme de contrôle est le suivant :
Octuor
0 1 2 3 Octuor Peu 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 0 Adresse source 4 32 Adresse de destination 8 64 Zéros Protocole (6) Longueur TCP 12 96 Port source Port de destination 16 128 Numéro de séquence 20 160 Numéro d'accusé de réception 24 192 Décalage des données Réservé drapeaux Fenêtre 28 224 Somme de contrôle Point urgent 32 256 (Options) 36 288 Données 40 320 ⋮ ⋮ La somme de contrôle est calculée sur les champs suivants :
- IPv6 , la méthode utilisée pour calculer la somme de contrôle est modifiée :
Tout protocole de transport ou autre protocole de couche supérieure qui inclut les adresses de l'en-tête IP dans son calcul de somme de contrôle doit être modifié pour être utilisé sur IPv6, afin d'inclure les adresses IPv6 de 128 bits au lieu des adresses IPv4 de 32 bits.
Un pseudo-en-tête imitant l'en-tête IPv6 pour le calcul de la somme de contrôle est présenté ci-dessous.
Octuor
0 1 2 3 Octuor Peu 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 0 0 Adresse source 4 32 8 64 12 96 16 128 Adresse de destination 20 160 24 192 28 224 32 256 Longueur TCP 36 288 Zéros En-tête suivant (6) 40 320 Port source Port de destination 44 352 Numéro de séquence 48 384 Numéro d'accusé de réception 52 416 Décalage des données Réservé drapeaux Fenêtre 56 448 Somme de contrôle Point urgent 60 480 (Options) 64 512 Données 68 544 ⋮ ⋮ La somme de contrôle est calculée sur les champs suivants :
- carte réseau avant la transmission sur le réseau ou lors de la réception des données du réseau à des fins de validation. Cela peut réduire la charge du processeur liée au calcul de la somme de contrôle, améliorant ainsi potentiellement les performances globales du réseau.
Cette fonctionnalité peut entraîner l'affichage de sommes de contrôle invalides dans les paquets sortants n'ayant pas encore atteint la carte réseau par les analyseurs de paquets qui ignorent ou ne sont pas certains de son utilisation. Ce problème ne concerne que les paquets interceptés avant leur transmission par la carte réseau ; tous les paquets transmis par celle-ci sur le réseau auront des sommes de contrôle valides. Ce problème peut également survenir lors de la surveillance de paquets transmis entre machines virtuelles sur le même hôte, lorsqu'un pilote de périphérique virtuel omet le calcul de la somme de contrôle (par optimisation), sachant que celle-ci sera calculée ultérieurement par le noyau de l'hôte de la machine virtuelle ou par son matériel physique.