En théorie et systèmes d'information, les données numériques , ou informations numériques , sont des données ou des informations représentées sous forme de chaîne de symboles discrets , chacun pouvant prendre une valeur parmi un nombre fini de valeurs issues d'un alphabet , comme des lettres ou des chiffres. Un document texte , constitué d'une chaîne de caractères alphanumériques , en est un exemple. La forme la plus courante de données numériques dans les systèmes d'information modernes est la donnée binaire , représentée par une chaîne de chiffres binaires (bits), chacun pouvant prendre l'une des deux valeurs suivantes : 0 ou 1. Les données numériques se distinguent des données analogiques , représentées par une valeur appartenant à un continuum de nombres réels . Les données analogiques sont transmises par un signal analogique , qui non seulement prend des valeurs continues, mais peut également varier continuellement dans le temps, selon une fonction continue à valeurs réelles du temps. La variation de pression de l'air dans une onde sonore en est un exemple . Les données nécessitent une interprétation pour devenir de l'information . Dans les systèmes informatiques modernes (postérieurs à 1960), toutes les données sont numériques. Le mot « numérique » provient de la même étymologie que les mots « digit » et « digitus » (du latin « digitus », doigt ), car les doigts sont souvent utilisés pour compter. Le mathématicien George Stibitz, des laboratoires Bell, a employé le terme « numérique » en référence aux impulsions électriques rapides émises par un dispositif conçu pour viser et tirer avec des canons antiaériens en 1942. Ce terme est surtout utilisé en informatique et en électronique , notamment lorsque des informations du monde réel sont converties en format numérique binaire , comme dans le cas de l'audio numérique et de la photographie numérique .
Un périphérique de saisie de symboles se compose généralement d'un ensemble d'interrupteurs interrogés à intervalles réguliers afin de déterminer leur état. Toute donnée est perdue si, au cours d'un même intervalle d'interrogation, deux interrupteurs sont actionnés simultanément, ou si un interrupteur est actionné, relâché, puis actionné à nouveau. Cette interrogation peut être effectuée par un processeur spécialisé intégré au périphérique afin de ne pas surcharger le processeur principal . Lorsqu'un nouveau symbole est saisi, le périphérique envoie généralement une interruption , dans un format spécifique, permettant ainsi au processeur de la lire.
Pour les périphériques ne comportant que quelques boutons (comme ceux d'un joystick ), l'état de chacun peut être codé par des bits (généralement 0 pour relâché et 1 pour enfoncé) dans un seul mot. Cette méthode est utile lorsque les combinaisons de touches sont significatives et sert parfois à transmettre l'état des touches de modification d'un clavier (comme Maj et Ctrl). Cependant, elle ne permet pas de gérer un nombre de touches supérieur au nombre de bits contenus dans un octet ou un mot.
Les périphériques comportant de nombreux interrupteurs (comme un clavier d'ordinateur ) disposent généralement ces interrupteurs en matrice de balayage, chaque interrupteur se trouvant à l'intersection des axes x et y. Lorsqu'un interrupteur est enfoncé, il connecte les axes x et y correspondants. L'interrogation (souvent appelée balayage dans ce cas) consiste à activer chaque axe x séquentiellement et à détecter quelles lignes y reçoivent alors un signal , indiquant ainsi les touches enfoncées. Lorsque le processeur du clavier détecte un changement d'état d'une touche, il envoie un signal au processeur central indiquant le code de balayage de la touche et son nouvel état. Le symbole est ensuite encodé ou converti en un nombre en fonction de l'état des touches de modification et de l' encodage de caractères souhaité .
Un encodage personnalisé peut être utilisé pour une application spécifique sans perte de données. Cependant, l'utilisation d'un encodage standard tel que l'ASCII pose problème si un symbole comme « ß » doit être converti mais ne fait pas partie de la norme.
On estime qu'en 1986, moins de 1 % de la capacité technologique mondiale de stockage d'informations était numérique, contre 94 % en 2007. L'année 2002 est considérée comme celle où l'humanité a pu stocker davantage d'informations sous forme numérique que sous forme analogique (le « début de l' ère numérique »).
États
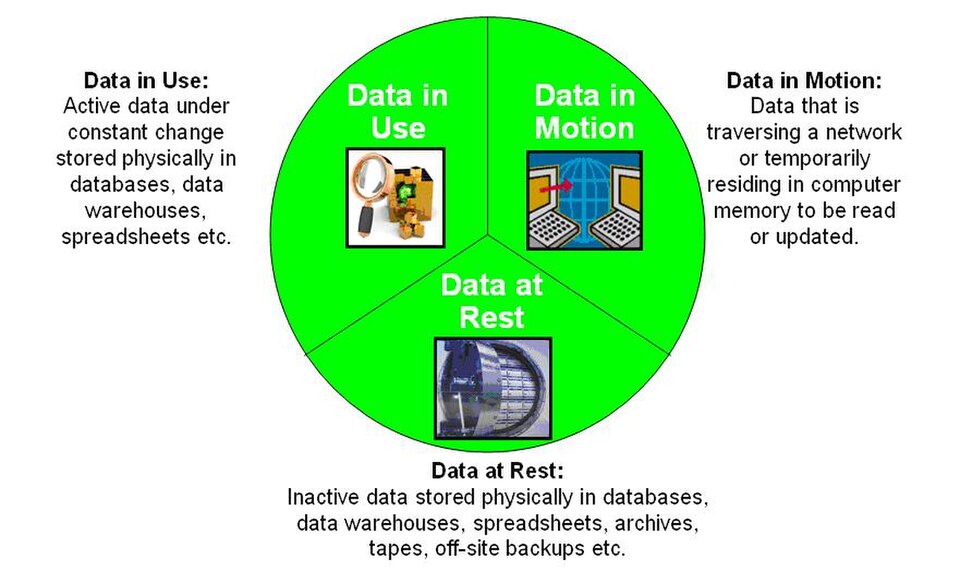
Les données numériques se présentent sous trois états : données au repos , données en transit et données en cours d’utilisation . La confidentialité, l’intégrité et la disponibilité doivent être gérées tout au long du cycle de vie des données, de leur création à leur destruction.
Données au repos
En informatique, les données au repos désignent les données stockées physiquement sur des supports de stockage informatique sous quelque forme numérique que ce soit (par exemple, stockage en nuage , services d'hébergement de fichiers , bases de données , entrepôts de données , feuilles de calcul , archives, bandes magnétiques, sauvegardes hors site ou dans le nuage, appareils mobiles , etc.). Les données au repos comprennent les données structurées et non structurées . Ce type de données est exposé aux menaces de piratage et autres actes malveillants visant à y accéder numériquement ou à voler physiquement le support de stockage. Pour empêcher l'accès, la modification ou le vol de ces données, les organisations mettent souvent en œuvre des mesures de sécurité telles que la protection par mot de passe, le chiffrement des données ou une combinaison des deux. Les options de sécurité utilisées pour ce type de données sont généralement désignées par le terme de protection des données au repos ( PDDR ).
Les définitions comprennent :
"...toutes les données stockées sur ordinateur, à l'exclusion des données qui transitent sur un réseau ou qui résident temporairement dans la mémoire de l'ordinateur pour être lues ou mises à jour."
« …toutes les données stockées, à l’exclusion des données qui transitent fréquemment sur le réseau ou qui résident en mémoire temporaire. Les données au repos comprennent, sans s’y limiter, les données archivées, les données qui ne sont pas consultées ou modifiées fréquemment, les fichiers stockés sur des disques durs, des clés USB, des fichiers stockés sur des bandes et disques de sauvegarde, ainsi que les fichiers stockés hors site ou sur un réseau de stockage (SAN). »
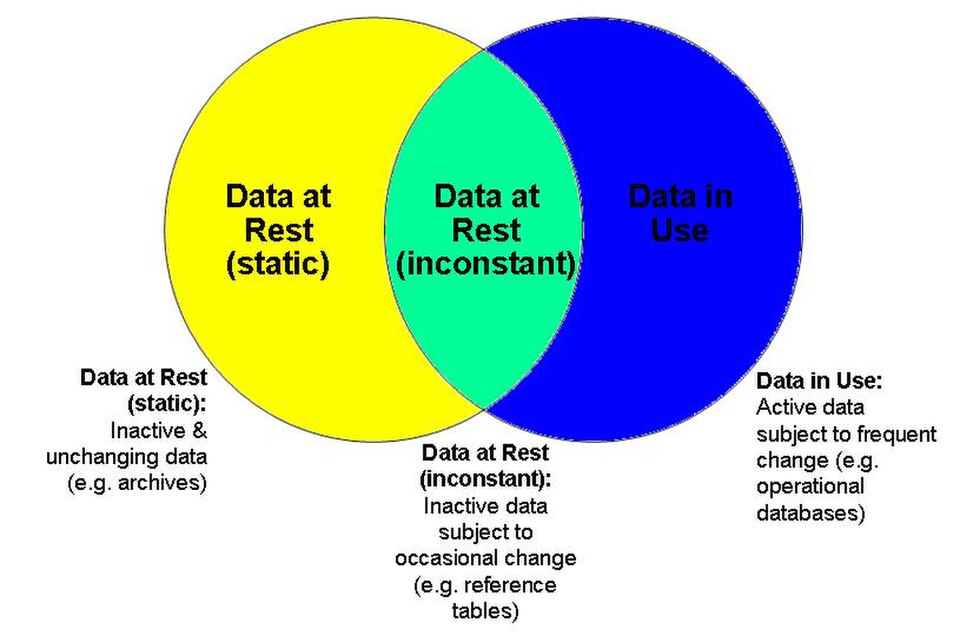
Il est généralement admis que les données archivées (c’est-à-dire celles qui ne changent jamais), quel que soit leur support de stockage, sont des données au repos, tandis que les données actives, sujettes à des modifications constantes ou fréquentes, sont des données en cours d’utilisation. On pourrait entendre par « données inactives » des données susceptibles de changer, mais rarement. L’imprécision de termes tels que « constant » et « fréquent » implique que certaines données stockées ne peuvent être classées de manière exhaustive ni comme données au repos ni comme données en cours d’utilisation. Ces définitions pourraient laisser entendre que les données au repos englobent les données en cours d’utilisation ; or, les données en cours d’utilisation, sujettes à des modifications fréquentes, ont des exigences de traitement distinctes de celles des données au repos, qu’elles soient totalement statiques ou sujettes à des modifications occasionnelles.
Sécurité
De par sa nature, la sécurité des données au repos est une préoccupation croissante pour les entreprises, les organismes gouvernementaux et autres institutions. Les appareils mobiles sont souvent soumis à des protocoles de sécurité spécifiques afin de protéger les données au repos contre tout accès non autorisé en cas de perte ou de vol et il est de plus en plus admis que les systèmes de gestion de bases de données et les serveurs de fichiers doivent également être considérés comme vulnérables ; plus les données restent longtemps inutilisées en stockage, plus elles risquent d’être récupérées par des personnes non autorisées en dehors du réseau.
Le chiffrement des données , qui empêche leur visibilité en cas d'accès non autorisé ou de vol, est couramment utilisé pour protéger les données en transit et de plus en plus préconisé pour la protection des données au repos. Le chiffrement des données au repos ne doit utiliser que des méthodes de chiffrement robustes telles que AES ou RSA . Les données chiffrées doivent le rester même en cas de défaillance des contrôles d'accès, comme les identifiants et mots de passe. Il est recommandé de renforcer le chiffrement à plusieurs niveaux. La cryptographie peut être mise en œuvre au niveau de la base de données hébergeant les données et au niveau du support physique de stockage. Les clés de chiffrement doivent être mises à jour régulièrement et stockées séparément des données. Le chiffrement permet également l'effacement crypté des données à la fin de leur cycle de vie ou de celle du matériel. Un audit périodique des données sensibles doit être intégré à la politique de sécurité et réalisé selon un calendrier établi. Enfin, il convient de ne stocker que le minimum de données sensibles.
La tokenisation est une approche non mathématique de protection des données au repos qui remplace les données sensibles par des substituts non sensibles, appelés jetons, dépourvus de toute signification ou valeur exploitable. Ce processus ne modifie ni le type ni la longueur des données, ce qui permet leur traitement par des systèmes existants, tels que les bases de données, sensibles à la longueur et au type des données. Les jetons nécessitent beaucoup moins de ressources de calcul et d'espace de stockage dans les bases de données que les données chiffrées de manière traditionnelle. Ce résultat est obtenu en conservant certaines données partiellement ou totalement visibles pour le traitement et l'analyse, tandis que les informations sensibles restent masquées. Grâce à ces faibles besoins en traitement et en stockage, la tokenisation est une méthode idéale pour sécuriser les données au repos dans les systèmes gérant de grands volumes de données.
Une autre méthode pour prévenir les accès non autorisés aux données au repos consiste à recourir à la fédération de données , notamment lorsque les données sont réparties à l'échelle mondiale (par exemple, dans des archives offshore). Prenons l'exemple d'une organisation européenne qui stocke ses données archivées hors site, aux États-Unis. En vertu du USA PATRIOT Act les autorités américaines peuvent exiger l'accès à toutes les données physiquement stockées sur leur territoire, même si elles contiennent des informations personnelles concernant des citoyens européens sans lien avec les États-Unis. Le chiffrement des données à lui seul ne suffit pas à empêcher cela, car les autorités ont le droit d'exiger le déchiffrement des informations. Une politique de fédération de données qui conserve les informations personnelles des citoyens sans lien avec l'étranger dans leur pays d'origine (séparément des informations non personnelles ou pertinentes pour les autorités offshore) est une solution possible. Cependant, les données stockées à l'étranger restent accessibles grâce à la législation du CLOUD Act .
Données utilisées
Les données en cours d'utilisation sont un terme de technologie de l'information faisant référence aux données actives stockées dans un état numérique non persistant ou dans une mémoire volatile , généralement dans la mémoire vive (RAM) de l'ordinateur, les caches du processeur ou les registres du processeur .
L’expression « données en cours d’utilisation » désigne également les « données actives » dans le contexte d’une base de données ou d’une application. Par exemple, certaines solutions de passerelle de chiffrement d’entreprise pour le cloud prétendent chiffrer les données au repos, les données en transit et les données en cours d’utilisation .
Certains fournisseurs de logiciels en nuage en tant que service (SaaS) considèrent les données en cours d'utilisation comme toutes les données actuellement traitées par les applications, lorsque le processeur et la mémoire sont utilisés.
Sécurité
De par sa nature, la sécurité des données en cours d'utilisation est une préoccupation croissante pour les entreprises, les administrations et autres institutions. Ces données, ou mémoire vive, peuvent contenir des informations sensibles telles que des certificats numériques, des clés de chiffrement, de la propriété intellectuelle (algorithmes logiciels, données de conception) et des données personnelles . La compromission des données en cours d'utilisation permet d'accéder aux données chiffrées, qu'elles soient stockées ou en transit. Par exemple, une personne ayant accès à la mémoire vive peut l'analyser pour localiser la clé de chiffrement des données stockées. Une fois cette clé obtenue, elle peut déchiffrer ces données. Les menaces pesant sur les données en cours d'utilisation peuvent prendre la forme d' attaques par démarrage à froid , de dispositifs matériels malveillants, de rootkits et de bootkits.
Le chiffrement, qui empêche la visibilité des données en cas d'accès non autorisé ou de vol, est couramment utilisé pour protéger les données en transit et les données au repos, et de plus en plus reconnu comme une méthode optimale pour protéger les données en cours d'utilisation. De nombreux projets de chiffrement de la mémoire ont été menés. Les consoles Microsoft Xbox sont conçues pour chiffrer la mémoire, et la société PrivateCore propose actuellement le logiciel commercial vCage, qui assure l'attestation et le chiffrement complet de la mémoire pour les serveurs x86. Plusieurs articles ont été publiés, soulignant la disponibilité de processeurs x86 et ARM grand public à sécurité renforcée. Dans ce travail, un processeur ARM Cortex-A8 sert de substrat à une solution de chiffrement complet de la mémoire. Les segments de processus (par exemple, la pile, le code ou le tas) peuvent être chiffrés individuellement ou par composition. Ce travail constitue la première implémentation du chiffrement complet de la mémoire sur un processeur grand public mobile. Le système garantit la confidentialité et l'intégrité du code et des données, chiffrés partout en dehors du processeur.
Pour les systèmes x86, AMD propose la fonctionnalité de chiffrement sécurisé de la mémoire (SME), introduite en 2017 avec Epyc . Intel a promis d'intégrer sa fonctionnalité de chiffrement total de la mémoire (TME) dans un prochain processeur.
Les correctifs du noyau du système d'exploitation, tels que TRESOR et Loop-Amnesia, modifient ce dernier afin que les registres du processeur puissent être utilisés pour stocker les clés de chiffrement, évitant ainsi leur présence dans la mémoire vive (RAM). Bien que cette approche ne soit pas universelle et ne protège pas toutes les données en cours d'utilisation, elle offre une protection contre les attaques par démarrage à froid. Les clés de chiffrement étant stockées dans le processeur plutôt que dans la RAM, les clés de chiffrement des données au repos sont ainsi protégées contre les attaques susceptibles de compromettre les clés de chiffrement en mémoire.
Les enclaves permettent de sécuriser une « enclave » par chiffrement dans la RAM, de sorte que les données de l’enclave soient chiffrées lorsqu’elles se trouvent dans la RAM, mais disponibles en clair dans le processeur et son cache. Intel Corporation a introduit le concept d’« enclaves » dans le cadre de ses extensions Software Guard . Intel a présenté une architecture combinant logiciel et matériel du processeur dans des articles techniques publiés en 2013.
Plusieurs outils cryptographiques, dont le calcul multipartite sécurisé et le chiffrement homomorphe , permettent le traitement privé de données sur des systèmes non fiables. Les données en cours d'utilisation peuvent être manipulées de manière chiffrée et ne jamais être exposées au système effectuant le traitement.
Données en transit
Les données en transit , également appelées données en mouvement et données en vol sont des données en route entre la source et la destination, généralement sur un réseau informatique .
Les données en transit peuvent être séparées en deux catégories : les informations qui circulent sur un réseau public ou non sécurisé comme Internet et les données qui circulent dans les limites d’un réseau privé comme un réseau local d’entreprise (LAN).

En informatique
Les données internes à un ordinateur circulent généralement en parallèle . Les données en provenance ou à destination d'un ordinateur circulent généralement en série . Les données provenant d'un appareil analogique, tel qu'un capteur de température, peuvent être converties en numérique à l'aide d'un convertisseur analogique-numérique . Les données représentant des quantités , des caractères ou des symboles sur lesquels un ordinateur effectue des opérations sont stockées et enregistrées sur des supports d'enregistrement magnétiques , optiques , électroniques ou mécaniques, puis transmises sous forme de signaux numériques électriques ou optiques. Les données transitent entre l'ordinateur et les périphériques .
Les éléments physiques de la mémoire d'un ordinateur sont constitués d'une adresse et d'un octet (ou mot) de données. Les données numériques sont souvent stockées dans des bases de données relationnelles , telles que des tables ou des bases de données SQL, et peuvent généralement être représentées par des paires clé/valeur abstraites. Les données peuvent être organisées selon différents types de structures de données , notamment les tableaux, les graphes et les objets . Ces structures peuvent stocker des données de types variés , tels que des nombres , des chaînes de caractères et même d'autres structures de données .
Caractéristiques
Les métadonnées permettent de transformer les données en informations. Ce sont des données sur les données. Elles peuvent être implicites, explicites ou explicites.
Les données relatives à des événements ou processus physiques comportent une dimension temporelle. Cette dimension temporelle peut être implicite. C'est le cas lorsqu'un appareil, tel qu'un enregistreur de température, reçoit des données d'un capteur de température . À la réception de la température, on considère que les données ont pour référence temporelle l' instant présent . L'appareil enregistre donc simultanément la date, l'heure et la température. Lorsque l'enregistreur de données transmet des températures, il doit également indiquer la date et l'heure comme métadonnées pour chaque relevé.
Fondamentalement, les ordinateurs suivent une séquence d'instructions qui leur sont données sous forme de données. Un ensemble d'instructions permettant d'effectuer une ou plusieurs tâches est appelé un programme . Un programme est constitué de données sous forme d'instructions codées qui contrôlent le fonctionnement d'un ordinateur ou d'une autre machine. En règle générale, le programme, tel qu'exécuté par l'ordinateur, est composé de code machine . Les éléments de stockage manipulés par le programme, mais non exécutés par l' unité centrale de traitement (CPU), sont également des données. Une donnée est, en substance, une valeur stockée à un emplacement précis. Il est donc possible pour des programmes informatiques d'agir sur d'autres programmes informatiques en manipulant leurs données programmatiques.
Pour stocker des octets de données dans un fichier, il faut les sérialiser dans un format de fichier . Généralement, les programmes sont stockés dans des types de fichiers spécifiques, différents de ceux utilisés pour les autres données. Les fichiers exécutables contiennent des programmes ; tous les autres fichiers sont également des fichiers de données . Cependant, les fichiers exécutables peuvent aussi contenir des données intégrées au programme. En particulier, certains fichiers exécutables possèdent un segment de données qui contient généralement des constantes et des valeurs initiales pour les variables, deux éléments qui peuvent être considérés comme des données.
La frontière entre programme et données peut devenir floue. Un interpréteur , par exemple, est un programme. Les données d'entrée d'un interpréteur constituent elles-mêmes un programme, même s'il n'est pas exprimé en langage machine natif . Dans de nombreux cas, le programme interprété est un fichier texte lisible par l'humain , que l'on manipule avec un éditeur de texte . La métaprogrammation implique également que des programmes manipulent d'autres programmes comme des données. Des programmes tels que les compilateurs , les éditeurs de liens , les débogueurs , les outils de mise à jour, les antivirus , etc., utilisent d'autres programmes comme données.
Par exemple, un utilisateur peut d'abord demander au système d'exploitation de charger un logiciel de traitement de texte à partir d'un fichier, puis utiliser ce logiciel pour ouvrir et modifier un document stocké dans un autre fichier. Dans ce cas, le document serait considéré comme une donnée. Si le traitement de texte intègre également un correcteur orthographique , son dictionnaire (liste de mots) serait lui aussi considéré comme une donnée. Les algorithmes utilisés par le correcteur orthographique pour suggérer des corrections seraient soit des données de code machine , soit du texte écrit dans un langage de programmation interprétable .
Dans un autre usage, les fichiers binaires (qui ne sont pas lisibles par l'homme ) sont parfois appelés données par opposition au texte lisible par l'homme .
La quantité totale de données numériques en 2007 était estimée à 281 milliards de gigaoctets (281 exaoctets ).
Clés et valeurs de données, structures et persistance
Les clés dans les données fournissent le contexte aux valeurs. Quelle que soit la structure des données, une clé est toujours présente. Les clés dans les données et les structures de données sont essentielles pour donner du sens aux valeurs. Sans clé associée directement ou indirectement à une valeur, ou à un ensemble de valeurs dans une structure, les valeurs perdent leur sens et cessent d'être des données. Autrement dit, une clé doit être liée à une valeur pour que celle-ci soit considérée comme une donnée.
Les données peuvent être représentées dans les ordinateurs de multiples façons, comme le montrent les exemples suivants :
BÉLIER
La mémoire vive (RAM) contient des données auxquelles le processeur a un accès direct. Le processeur ne peut manipuler que les données contenues dans ses registres ou sa mémoire. Ceci contraste avec le stockage de données, où le processeur doit gérer le transfert des données entre le périphérique de stockage (disque, bande magnétique, etc.) et la mémoire. La RAM est un tableau d'emplacements linéaires contigus qu'un processeur peut lire ou écrire en fournissant une adresse pour l'opération de lecture ou d'écriture. Le processeur peut accéder à n'importe quel emplacement mémoire, à tout moment et dans n'importe quel ordre. En RAM, la plus petite unité de données est le bit binaire . Les capacités et les limitations d'accès à la RAM sont spécifiques au processeur. En général, la mémoire principale est organisée comme un tableau d' emplacements commençant à l'adresse 0 ( 0 en hexadécimal ). Chaque emplacement peut généralement stocker 8 ou 32 bits, selon l' architecture de l'ordinateur .
Clés
Les clés de données ne correspondent pas nécessairement à une adresse matérielle directe en mémoire. Des clés indirectes , abstraites et logiques peuvent être associées à des valeurs pour former une structure de données . Les structures de données possèdent des décalages (ou liens ou chemins) prédéterminés par rapport au début de la structure, où sont stockées les valeurs. Ainsi, la clé de données est composée de la clé d'accès à la structure et du décalage (ou lien ou chemin) correspondant. Lorsqu'une telle structure est répétée, en stockant des variations des valeurs et des clés de données au sein de la même structure répétitive, le résultat peut être assimilé à un tableau . Dans ce tableau, chaque élément de la structure répétitive correspond à une colonne et chaque répétition à une ligne. Dans cette organisation des données, la clé de données est généralement une valeur présente dans une colonne (ou une combinaison des valeurs de plusieurs colonnes).
Structures de données récurrentes organisées
La représentation tabulaire des structures de données répétitives n'est qu'une possibilité parmi d'autres. Ces structures peuvent être organisées hiérarchiquement , les nœuds étant liés entre eux par une cascade de relations parent-enfant. Des valeurs, et potentiellement des structures de données plus complexes, sont associées à ces nœuds. Ainsi, la hiérarchie nodale permet d'accéder aux structures de données qui leur sont liées. Cette représentation peut être vue comme un arbre inversé . Les systèmes de fichiers des systèmes d'exploitation modernes en sont un exemple courant ; le format XML en est un autre.
Données triées ou ordonnées
Les données présentent certaines caractéristiques intrinsèques lorsqu'elles sont triées selon une clé . Toutes les valeurs associées à des sous-ensembles de la clé apparaissent ensemble. Lors du parcours séquentiel de groupes de données ayant la même clé, ou lorsqu'un sous-ensemble de la clé change, on parle de rupture, ou de rupture de contrôle , dans le domaine du traitement des données. Cela facilite notamment l'agrégation des valeurs de données associées à des sous-ensembles d'une clé.
Stockage périphérique
Avant l'avènement des mémoires non volatiles de grande capacité comme la mémoire flash , le stockage persistant des données était traditionnellement réalisé en écrivant les données sur des périphériques de stockage externes tels que les bandes magnétiques et les disques durs . Ces périphériques accèdent généralement à un emplacement précis sur le support magnétique, puis lisent ou écrivent des blocs de données d'une taille prédéterminée. Dans ce cas, l'emplacement de lecture sur le support constitue la clé de données et les blocs représentent les valeurs des données. Les premiers systèmes de fichiers ou systèmes d'exploitation utilisant des données brutes sur disque réservaient des blocs contigus sur le disque dur pour les fichiers de données . Dans ces systèmes, les fichiers pouvaient être saturés, l'espace disque étant épuisé avant que toutes les données n'y soient écrites. Ainsi, une grande quantité d'espace inutilisé était réservée inutilement afin de garantir un espace libre suffisant pour chaque fichier. Les systèmes de fichiers ultérieurs ont introduit les partitions . Ils réservent des blocs d'espace disque pour les partitions et utilisent ces blocs alloués de manière plus économique, en les attribuant dynamiquement à un fichier selon les besoins. Pour ce faire, le système de fichiers devait conserver une trace des blocs utilisés ou non par les fichiers de données dans un catalogue ou une table d'allocation de fichiers. Bien que cette méthode permette une meilleure utilisation de l'espace disque, elle entraîne une fragmentation des fichiers et, par conséquent, une augmentation des performances due au temps de recherche supplémentaire nécessaire pour lire les données. Les systèmes de fichiers modernes réorganisent dynamiquement les fichiers fragmentés afin d'optimiser les temps d'accès. Les évolutions ultérieures des systèmes de fichiers ont conduit à la virtualisation des disques durs, c'est-à-dire à la possibilité de définir un lecteur logique comme une partition issue de plusieurs disques physiques.
données indexées
Extraire un petit sous-ensemble de données d'un ensemble beaucoup plus vaste peut impliquer une recherche séquentielle inefficace. Les index permettent de copier les clés et les adresses d'emplacement des structures de données dans les fichiers, les tables et les ensembles de données, puis de les organiser à l'aide de structures arborescentes inversées afin de réduire le temps nécessaire à l'extraction d'un sous-ensemble des données originales. Pour ce faire, la clé du sous-ensemble de données à extraire doit être connue avant le début de l'extraction. Les index les plus courants sont l' arbre B et l' indexation par clé de hachage dynamique . L'indexation représente une surcharge pour le classement et l'extraction des données. Il existe d'autres méthodes d'organisation des index, comme le tri des clés et l'utilisation d'un algorithme de recherche dichotomique .
Abstraction et indirection
La programmation orientée objet utilise deux concepts fondamentaux pour comprendre les données et les logiciels :
- La structure hiérarchique des classes taxonomiques , qui est un exemple de structure de données hiérarchique ; et
- lors de l'exécution, la création de références aux structures de données en mémoire d'objets qui ont été instanciés à partir d'une bibliothèque de classes .
Un objet d'une classe donnée n'existe qu'après son instanciation. Une fois la référence à un objet effacée, l'objet cesse d'exister. Les emplacements mémoire où étaient stockées ses données sont alors considérés comme de la mémoire inutilisée , disponible pour une réutilisation ultérieure.
Données de base de données
L'avènement des bases de données a introduit une couche d'abstraction supplémentaire pour le stockage persistant des données. Les bases de données utilisent des métadonnées et un protocole de langage de requête structuré (SQL) entre les systèmes client et serveur , communiquant via un réseau informatique , et un système de journalisation des transactions en deux phases pour garantir l'intégrité des données enregistrées.
Traitement parallèle distribué des données
Les technologies modernes de persistance des données, évolutives et performantes, telles qu'Apache Hadoop , reposent sur un traitement distribué massivement parallèle des données, réparties sur de nombreux ordinateurs standard connectés à un réseau à haut débit. Dans ces systèmes, les données sont distribuées sur plusieurs ordinateurs ; par conséquent, chaque ordinateur du système doit être représenté dans la clé de données, directement ou indirectement. Ceci permet de différencier deux ensembles de données identiques, traités simultanément sur des ordinateurs différents.
Propriétés de l'information numérique
Toute information numérique possède des propriétés communes qui la distinguent des données analogiques en matière de communication :
- Synchronisation : Puisque l’information numérique est véhiculée par l’ordre des symboles, tout système numérique dispose d’un mécanisme permettant de déterminer le début d’une séquence. Dans les langues humaines écrites ou parlées, la synchronisation est généralement assurée par les pauses (espaces), la mise en majuscules et la ponctuation . Les communications machine utilisent généralement des séquences de synchronisation spécifiques .
- Langage : Toute communication numérique requiert un langage formel , qui, dans ce contexte, regroupe toutes les informations que l’émetteur et le récepteur doivent posséder au préalable pour que la communication aboutisse. Les langages sont généralement arbitraires et spécifient la signification à attribuer à des séquences de symboles particulières, l’étendue des valeurs autorisées, les méthodes de synchronisation à utiliser, etc.
- Erreurs : Les perturbations ( bruit ) dans les communications analogiques introduisent inévitablement un écart, généralement faible, entre la communication prévue et la communication réelle. Dans les communications numériques, les perturbations ne génèrent d'erreurs que lorsqu'elles sont suffisamment importantes pour entraîner la confusion d'un symbole avec un autre ou la perturbation de la séquence de symboles. Il est généralement possible d'obtenir des communications numériques quasi exemptes d'erreurs. De plus, des techniques telles que les codes de contrôle permettent de détecter les erreurs et de les corriger par redondance ou retransmission. Les erreurs dans les communications numériques peuvent prendre la forme d' erreurs de substitution, où un symbole est remplacé par un autre, ou d'erreurs d'insertion/suppression , où un symbole incorrect est inséré ou supprimé d'un message numérique. Les erreurs non corrigées dans les communications numériques ont un impact imprévisible et généralement important sur le contenu informationnel de la communication.
- Copie : En raison de la présence inévitable de bruit, la réalisation de nombreuses copies successives d’une communication analogique est impossible, car chaque génération augmente le bruit. Les communications numériques étant généralement exemptes d’erreurs, il est possible de réaliser des copies de copies indéfiniment.
- Granularité : La représentation numérique d'une valeur analogique à variation continue implique généralement le choix du nombre de symboles qui lui sont attribués. Ce nombre détermine la précision ou la résolution de la donnée résultante. La différence entre la valeur analogique réelle et sa représentation numérique est appelée erreur de quantification . Par exemple, si la température réelle est de 23,234456544453 degrés, mais que seulement deux chiffres (23) sont attribués à ce paramètre dans une représentation numérique particulière, l'erreur de quantification est de 0,234456544453. Cette propriété de la communication numérique est appelée granularité .
- Compressibilité : Selon Miller, « les données numériques non compressées sont très volumineuses et, à l’état brut, elles produiraient un signal plus important (donc plus difficile à transférer) que les données analogiques. Cependant, les données numériques peuvent être compressées. La compression réduit la bande passante nécessaire à la transmission des informations. Les données peuvent être compressées, envoyées, puis décompressées au point de réception. Cela permet de transmettre beaucoup plus d’informations et se traduit, par exemple, par des signaux de télévision numérique offrant davantage de fréquences pour un plus grand nombre de chaînes. »
Systèmes numériques historiques
Bien que les signaux numériques soient généralement associés aux systèmes électroniques binaires utilisés dans l'électronique et l'informatique modernes, les systèmes numériques sont en réalité anciens et ne sont pas nécessairement binaires ou électroniques.
- Le code génétique de l'ADN est une forme naturelle de stockage de données numériques.
- Texte écrit (en raison du jeu de caractères limité et de l'utilisation de symboles discrets – l'alphabet dans la plupart des cas)
- Le boulier a été inventé entre 1000 et 500 avant J.-C. Il est ensuite devenu un outil de calcul de fréquence. De nos jours, il peut servir de calculatrice numérique à la fois simple et sophistiquée, utilisant des boules disposées en rangées pour représenter les nombres. Les boules n'ont de signification que par leurs positions hautes ou basses, et non par des états intermédiaires analogiques.
- Une balise est peut-être le signal numérique non électronique le plus simple, avec seulement deux états (allumé et éteint). En particulier, les signaux de fumée constituent l'un des plus anciens exemples de signal numérique, où une « porteuse » analogique (la fumée) est modulée par une couverture pour générer un signal numérique (des bouffées) qui transmet une information.
- Le code Morse utilise six états numériques — point, trait, espace intra-caractère (entre chaque point ou trait), petit espace (entre chaque lettre), espace moyen (entre les mots) et grand espace (entre les phrases) — pour envoyer des messages via divers supports potentiels tels que l'électricité ou la lumière, par exemple en utilisant un télégraphe électrique ou une lumière clignotante.
- Le braille utilise un code à six bits rendu sous forme de motifs de points.
- Le sémaphore à drapeaux utilise des tiges ou des drapeaux tenus dans des positions particulières pour envoyer des messages au récepteur qui les observe à une certaine distance.
- Les pavillons de signalisation maritime internationaux comportent des marques distinctives qui représentent des lettres de l'alphabet afin de permettre aux navires de s'envoyer des messages entre eux.
- Plus récemment inventé, le modem module un signal porteur analogique (comme le son) pour encoder des informations numériques électriques binaires, sous forme d'une série d'impulsions sonores numériques binaires. Une version légèrement antérieure, étonnamment fiable, du même concept consistait à enregistrer une séquence d'informations audio numériques « signal » et « absence de signal » (c'est-à-dire « son » et « silence ») sur une cassette magnétique pour les premiers ordinateurs personnels .